 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional Regret Minimization
Dec 30, 2025Multi-criteria decision making in large databases is very important in real world applications. Recently, an interactive query has been studied extensively in the database literature with the advantage of both the top-k query (with limited output size) and the skyline query (which does not require users to explicitly specify their preference function). This approach iteratively asks the user to select the one preferred within a set of options. Based on rounds of feedback, the query learns the implicit preference and returns the most favorable as a recommendation. However, many modern applications in areas like housing or financial product markets feature datasets with hundreds of attributes. Existing interactive algorithms either fail to scale or require excessive user interactions (often exceeding 1000 rounds). Motivated by this, we propose FHDR (Fast High-Dimensional Reduction), a novel framework that takes less than 0.01s with fewer than 30 rounds of interaction. It is considered a breakthrough in the field of interactive queries since most, if not all, existing studies are not scalable to high-dimensional datasets. Extensive experiments demonstrate that FHDR outperforms the best-known algorithms by at least an order of magnitude in execution time and up to several orders of magnitude in terms of the number of interactions required, establishing a new state of the art for scalable interactive regret minimization.
Streaming Word Embeddings with the Space-Saving Algorithm
Apr 24, 2017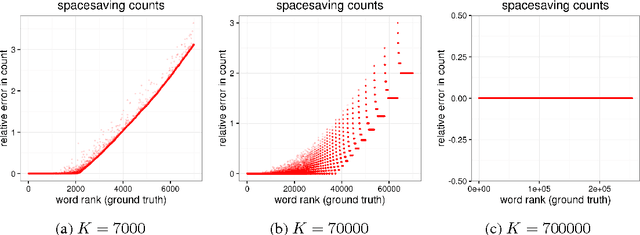

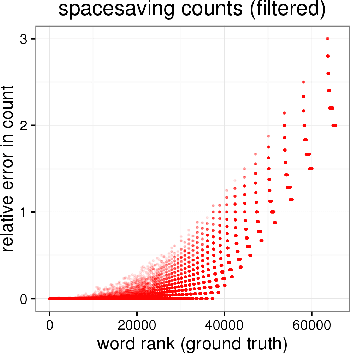
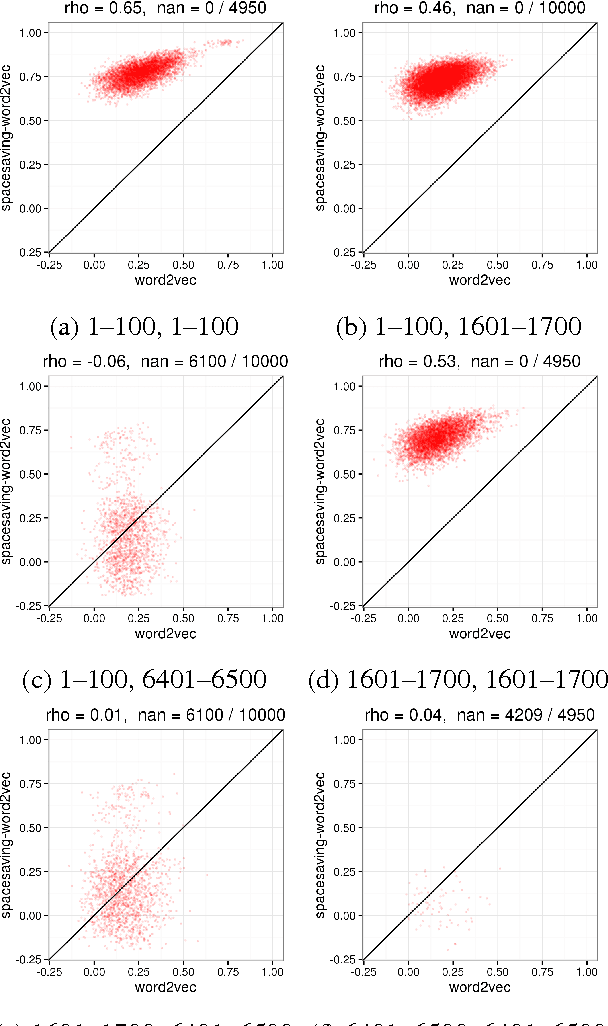
We develop a streaming (one-pass, bounded-memory) word embedding algorithm based on the canonical skip-gram with negative sampling algorithm implemented in word2vec. We compare our streaming algorithm to word2vec empirically by measuring the cosine similarity between word pairs under each algorithm and by applying each algorithm in the downstream task of hashtag prediction on a two-month interval of the Twitter sample stream. We then discuss the results of these experiments, concluding they provide partial validation of our approach as a streaming replacement for word2vec. Finally, we discuss potential failure modes and suggest directions for future work.