 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILDC for CJPE: Indian Legal Documents Corpus for Court Judgment Prediction and Explanation
May 31, 2021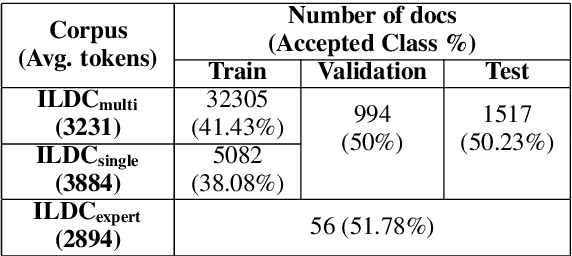
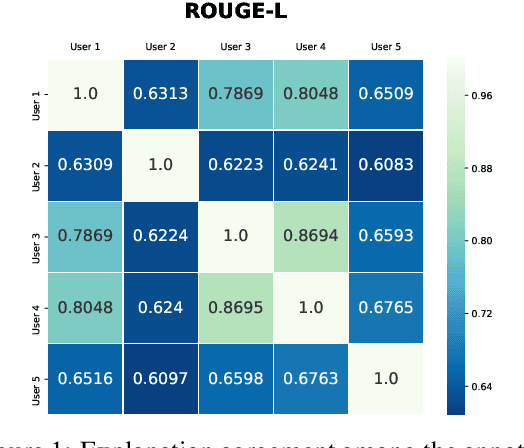
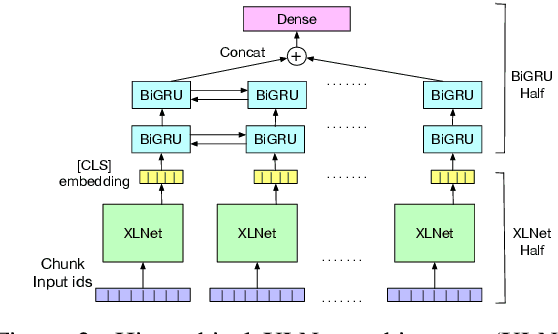

An automated system that could assist a judge in predicting the outcome of a case would help expedite the judicial process. For such a system to be practically useful, predictions by the system should be explainable. To promote research in developing such a system, we introduce ILDC (Indian Legal Documents Corpus). ILDC is a large corpus of 35k Indian Supreme Court cases annotated with original court decisions. A portion of the corpus (a separate test set) is annotated with gold standard explanations by legal experts. Based on ILDC, we propose the task of Court Judgment Prediction and Explanation (CJPE). The task requires an automated system to predict an explainable outcome of a case. We experiment with a battery of baseline models for case predictions and propose a hierarchical occlusion based model for explainability. Our best prediction model has an accuracy of 78% versus 94% for human legal experts, pointing towards the complexity of the prediction task. The analysis of explanations by the proposed algorithm reveals a significant difference in the point of view of the algorithm and legal experts for explaining the judgments, pointing towards scope for future research.
NLP for Climate Policy: Creating a Knowledge Platform for Holistic and Effective Climate Action
May 12, 2021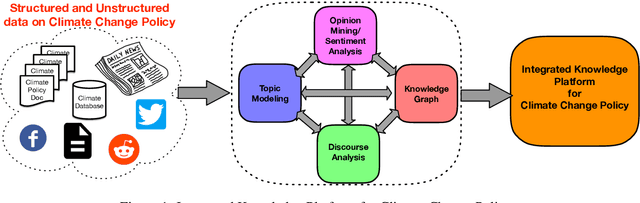
Climate change is a burning issue of our time, with the Sustainable Development Goal (SDG) 13 of the United Nations demanding global climate action. Realizing the urgency, in 2015 in Paris, world leaders signed an agreement committing to taking voluntary action to reduce carbon emissions. However, the scale, magnitude, and climate action processes vary globally, especially between developed and developing countries. Therefore, from parliament to social media, the debates and discussions on climate change gather data from wide-ranging sources essential to the policy design and implementation. The downside is that we do not currently have the mechanisms to pool the worldwide dispersed knowledge emerging from the structured and unstructured data sources. The paper thematically discusses how NLP techniques could be employed in climate policy research and contribute to society's good at large. In particular, we exemplify symbiosis of NLP and Climate Policy Research via four methodologies. The first one deals with the major topics related to climate policy using automated content analysis. We investigate the opinions (sentiments) of major actors' narratives towards climate policy in the second methodology. The third technique explores the climate actors' beliefs towards pro or anti-climate orientation. Finally, we discuss developing a Climate Knowledge Graph. The present theme paper further argues that creating a knowledge platform would help in the formulation of a holistic climate policy and effective climate action. Such a knowledge platform would integrate the policy actors' varied opinions from different social sectors like government, business, civil society, and the scientific community. The research outcome will add value to effective climate action because policymakers can make informed decisions by looking at the diverse public opinion on a comprehensive platform.
BreakingBERT@IITK at SemEval-2021 Task 9 : Statement Verification and Evidence Finding with Tables
Apr 10, 2021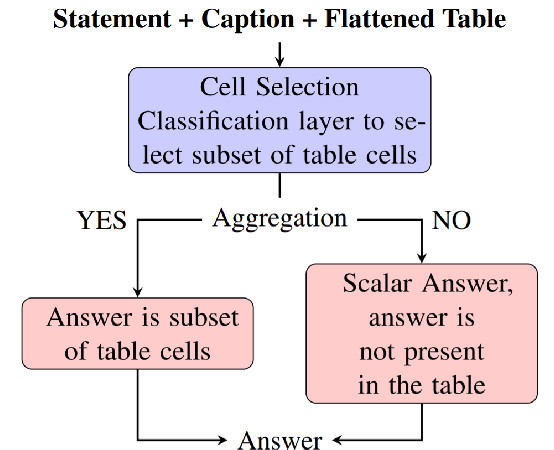
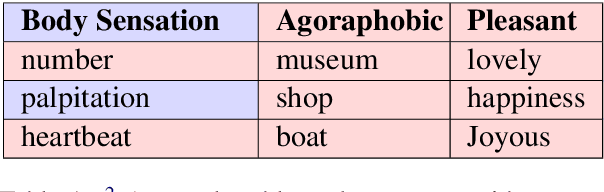

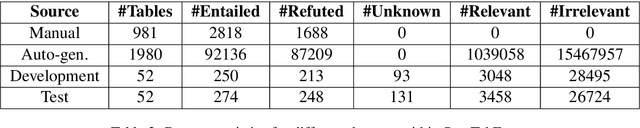
Recently, there has been an interest in factual verification and prediction over structured data like tables and graphs. To circumvent any false news incident, it is necessary to not only model and predict over structured data efficiently but also to explain those predictions. In this paper, as part of the SemEval-2021 Task 9, we tackle the problem of fact verification and evidence finding over tabular data. There are two subtasks. Given a table and a statement/fact, subtask A determines whether the statement is inferred from the tabular data, and subtask B determines which cells in the table provide evidence for the former subtask. We make a comparison of the baselines and state-of-the-art approaches over the given SemTabFact dataset. We also propose a novel approach CellBERT to solve evidence finding as a form of the Natural Language Inference task. We obtain a 3-way F1 score of 0.69 on subtask A and an F1 score of 0.65 on subtask B.
KnowGraph@IITK at SemEval-2021 Task 11: Building KnowledgeGraph for NLP Research
Apr 04, 2021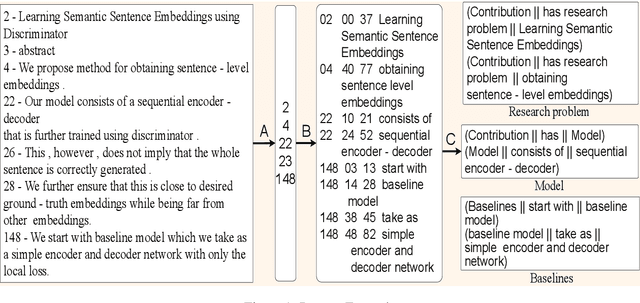
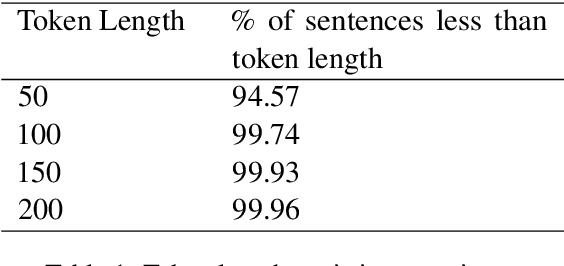
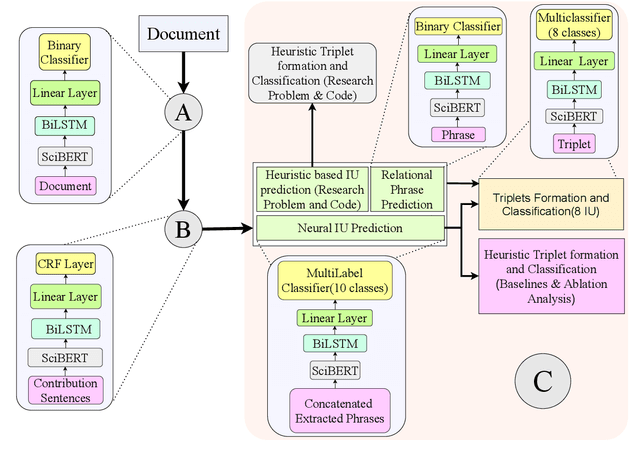
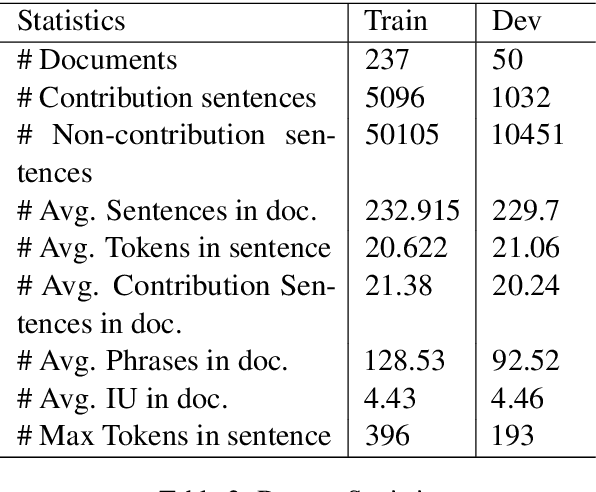
Research in Natural Language Processing is making rapid advances, resulting in the publication of a large number of research papers. Finding relevant research papers and their contribution to the domain is a challenging problem. In this paper, we address this challenge via the SemEval 2021 Task 11: NLPContributionGraph, by developing a system for a research paper contributions-focused knowledge graph over Natural Language Processing literature. The task is divided into three sub-tasks: extracting contribution sentences that show important contributions in the research article, extracting phrases from the contribution sentences, and predicting the information units in the research article together with triplet formation from the phrases. The proposed system is agnostic to the subject domain and can be applied for building a knowledge graph for any area. We found that transformer-based language models can significantly improve existing techniques and utilized the SciBERT-based model. Our first sub-task uses Bidirectional LSTM (BiLSTM) stacked on top of SciBERT model layers, while the second sub-task uses Conditional Random Field (CRF) on top of SciBERT with BiLSTM. The third sub-task uses a combined SciBERT based neural approach with heuristics for information unit prediction and triplet formation from the phrases. Our system achieved F1 score of 0.38, 0.63 and 0.76 in end-to-end pipeline testing, phrase extraction testing and triplet extraction testing respectively.
MCL@IITK at SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation using Augmented Data, Signals, and Transformers
Apr 04, 2021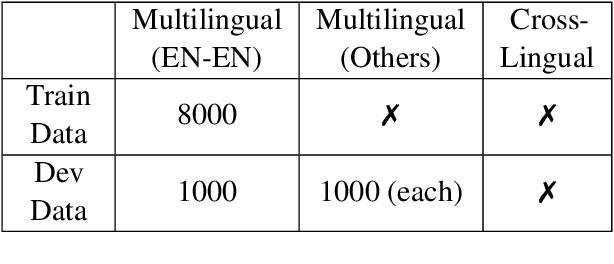
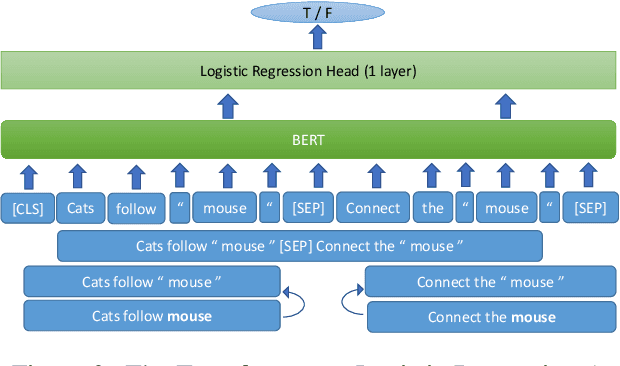
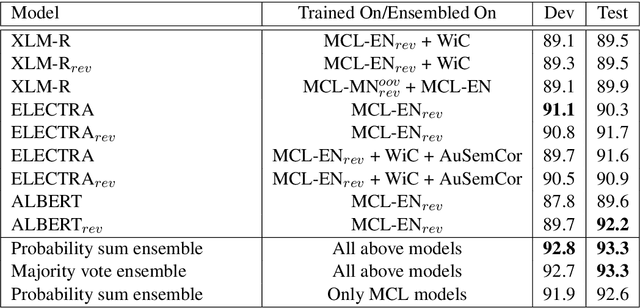
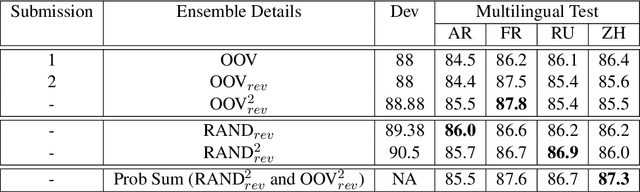
In this work, we present our approach for solving the SemEval 2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC). The task is a sentence pair classification problem where the goal is to detect whether a given word common to both the sentences evokes the same meaning. We submit systems for both the settings - Multilingual (the pair's sentences belong to the same language) and Cross-Lingual (the pair's sentences belong to different languages). The training data is provided only in English. Consequently, we employ cross-lingual transfer techniques. Our approach employs fine-tuning pre-trained transformer-based language models, like ELECTRA and ALBERT, for the English task and XLM-R for all other tasks. To improve these systems' performance, we propose adding a signal to the word to be disambiguated and augmenting our data by sentence pair reversal. We further augment the dataset provided to us with WiC, XL-WiC and SemCor 3.0. Using ensembles, we achieve strong performance in the Multilingual task, placing first in the EN-EN and FR-FR sub-tasks. For the Cross-Lingual setting, we employed translate-test methods and a zero-shot method, using our multilingual models, with the latter performing slightly better.
IITK@Detox at SemEval-2021 Task 5: Semi-Supervised Learning and Dice Loss for Toxic Spans Detection
Apr 04, 2021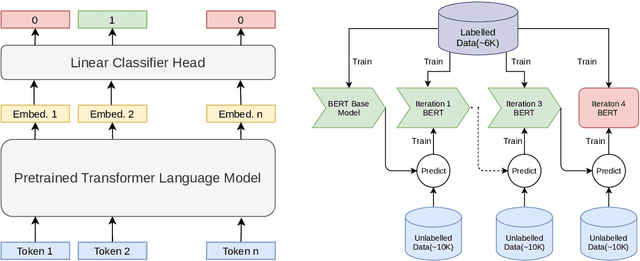
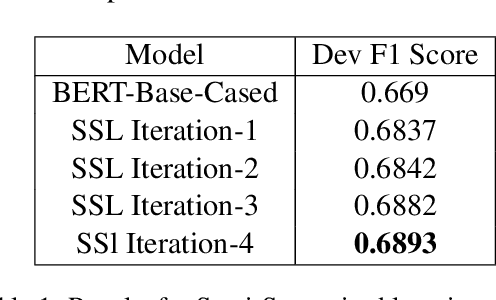
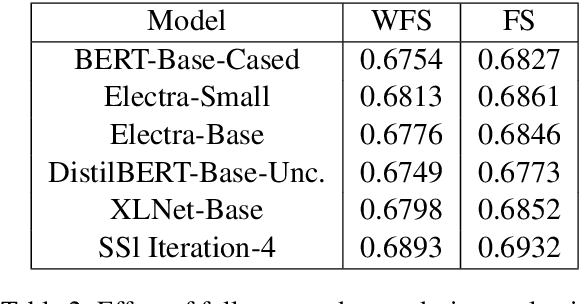
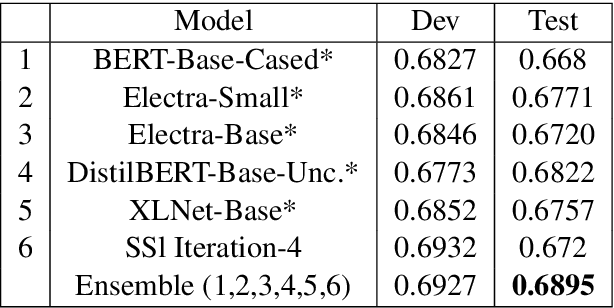
In this work, we present our approach and findings for SemEval-2021 Task 5 - Toxic Spans Detection. The task's main aim was to identify spans to which a given text's toxicity could be attributed. The task is challenging mainly due to two constraints: the small training dataset and imbalanced class distribution. Our paper investigates two techniques, semi-supervised learning and learning with Self-Adjusting Dice Loss, for tackling these challenges. Our submitted system (ranked ninth on the leader board) consisted of an ensemble of various pre-trained Transformer Language Models trained using either of the above-proposed techniques.
ReCAM@IITK at SemEval-2021 Task 4: BERT and ALBERT based Ensemble for Abstract Word Prediction
Apr 04, 2021
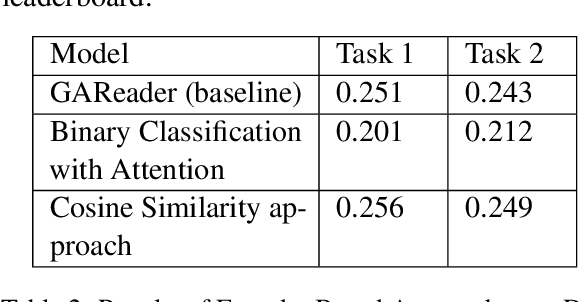
This paper describes our system for Task 4 of SemEval-2021: Reading Comprehension of Abstract Meaning (ReCAM). We participated in all subtasks where the main goal was to predict an abstract word missing from a statement. We fine-tuned the pre-trained masked language models namely BERT and ALBERT and used an Ensemble of these as our submitted system on Subtask 1 (ReCAM-Imperceptibility) and Subtask 2 (ReCAM-Nonspecificity). For Subtask 3 (ReCAM-Intersection), we submitted the ALBERT model as it gives the best results. We tried multiple approaches and found that Masked Language Modeling(MLM) based approach works the best.
Counts@IITK at SemEval-2021 Task 8: SciBERT Based Entity And Semantic Relation Extraction For Scientific Data
Apr 03, 2021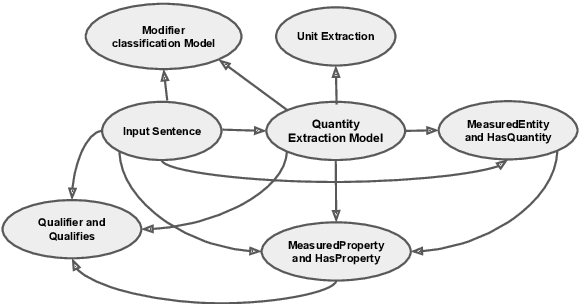
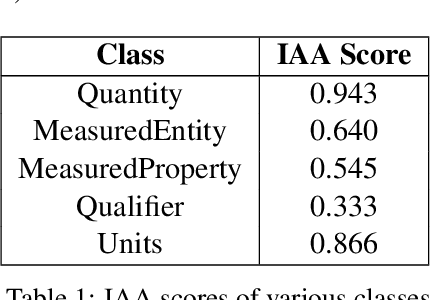
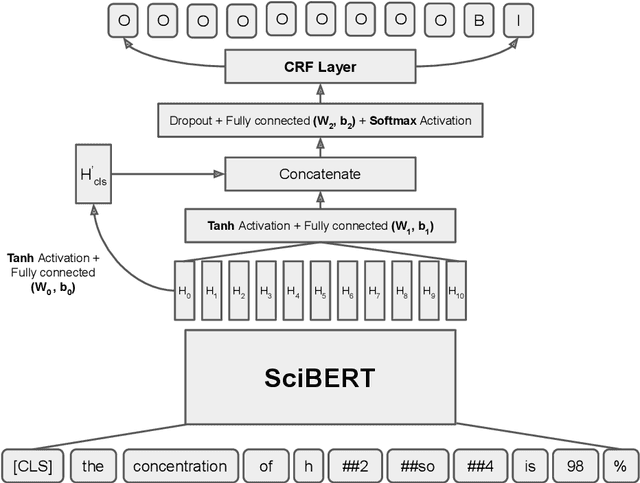
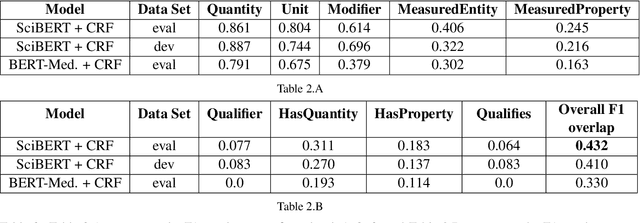
This paper presents the system for SemEval 2021 Task 8 (MeasEval). MeasEval is a novel span extraction, classification, and relation extraction task focused on finding quantities, attributes of these quantities, and additional information, including the related measured entities, properties, and measurement contexts. Our submitted system, which placed fifth (team rank) on the leaderboard, consisted of SciBERT with [CLS] token embedding and CRF layer on top. We were also placed first in Quantity (tied) and Unit subtasks, second in MeasuredEntity, Modifier and Qualifies subtasks, and third in Qualifier subtask.
IITK@LCP at SemEval 2021 Task 1: Classification for Lexical Complexity Regression Task
Apr 02, 2021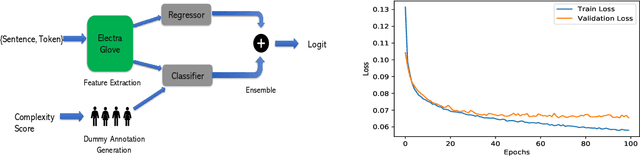
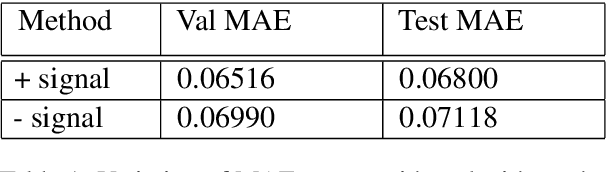
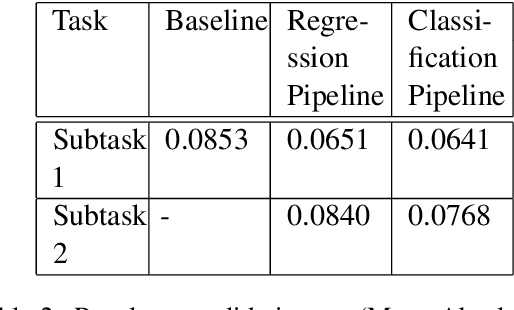
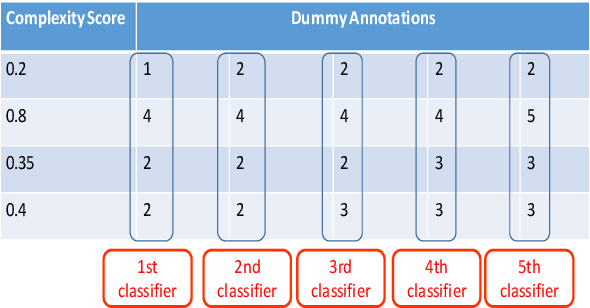
This paper describes our contribution to SemEval 2021 Task 1: Lexical Complexity Prediction. In our approach, we leverage the ELECTRA model and attempt to mirror the data annotation scheme. Although the task is a regression task, we show that we can treat it as an aggregation of several classification and regression models. This somewhat counter-intuitive approach achieved an MAE score of 0.0654 for Sub-Task 1 and MAE of 0.0811 on Sub-Task 2. Additionally, we used the concept of weak supervision signals from Gloss-BERT in our work, and it significantly improved the MAE score in Sub-Task 1.
Humor@IITK at SemEval-2021 Task 7: Large Language Models for Quantifying Humor and Offensiveness
Apr 02, 2021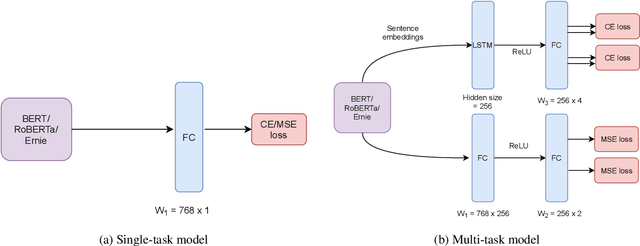
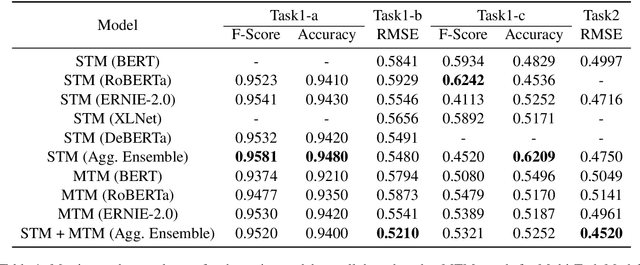
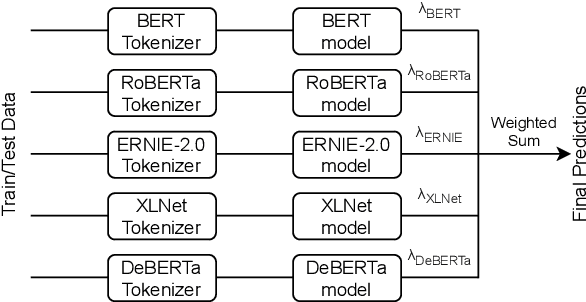
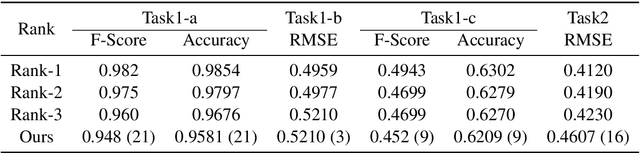
Humor and Offense are highly subjective due to multiple word senses, cultural knowledge, and pragmatic competence. Hence, accurately detecting humorous and offensive texts has several compelling use cases in Recommendation Systems and Personalized Content Moderation. However, due to the lack of an extensive labeled dataset, most prior works in this domain haven't explored large neural models for subjective humor understanding. This paper explores whether large neural models and their ensembles can capture the intricacies associated with humor/offense detection and rating. Our experiments on the SemEval-2021 Task 7: HaHackathon show that we can develop reasonable humor and offense detection systems with such models. Our models are ranked third in subtask 1b and consistently ranked around the top 33% of the leaderboard for the remaining subtasks.