 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIITK@Detox at SemEval-2021 Task 5: Semi-Supervised Learning and Dice Loss for Toxic Spans Detection
Apr 04, 2021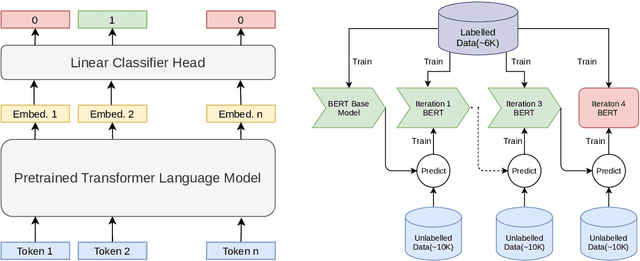
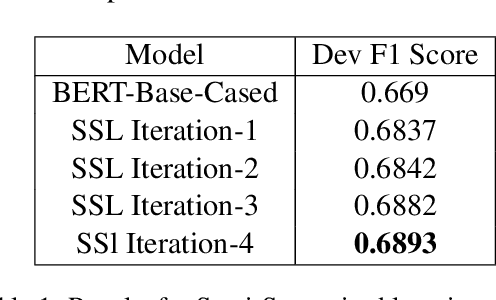
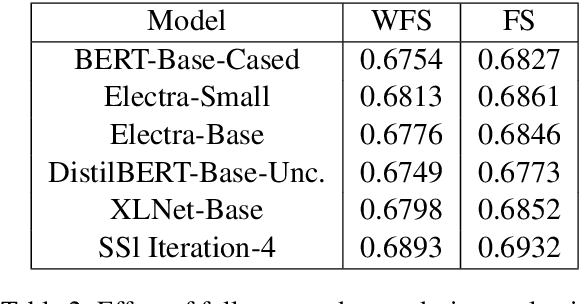
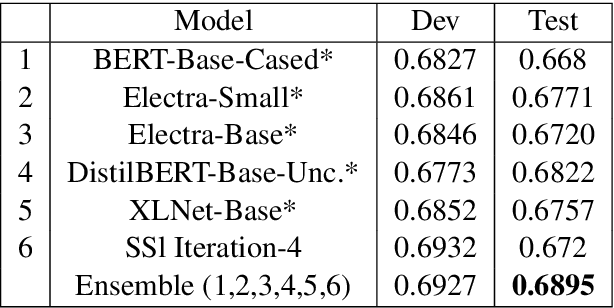
In this work, we present our approach and findings for SemEval-2021 Task 5 - Toxic Spans Detection. The task's main aim was to identify spans to which a given text's toxicity could be attributed. The task is challenging mainly due to two constraints: the small training dataset and imbalanced class distribution. Our paper investigates two techniques, semi-supervised learning and learning with Self-Adjusting Dice Loss, for tackling these challenges. Our submitted system (ranked ninth on the leader board) consisted of an ensemble of various pre-trained Transformer Language Models trained using either of the above-proposed techniques.
Cross-SEAN: A Cross-Stitch Semi-Supervised Neural Attention Model for COVID-19 Fake News Detection
Feb 18, 2021
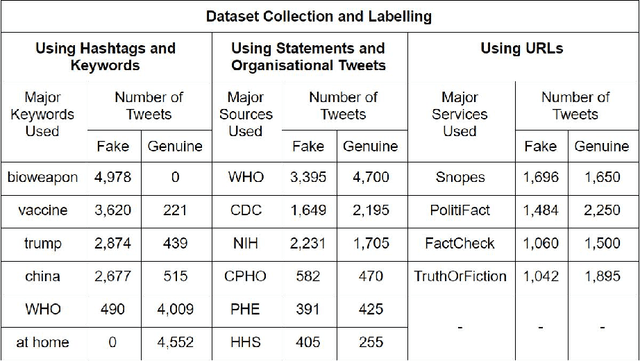
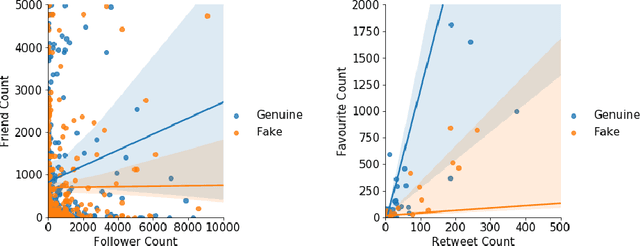

As the COVID-19 pandemic sweeps across the world, it has been accompanied by a tsunami of fake news and misinformation on social media. At the time when reliable information is vital for public health and safety, COVID-19 related fake news has been spreading even faster than the facts. During times such as the COVID-19 pandemic, fake news can not only cause intellectual confusion but can also place lives of people at risk. This calls for an immediate need to contain the spread of such misinformation on social media. We introduce CTF, the first COVID-19 Twitter fake news dataset with labeled genuine and fake tweets. Additionally, we propose Cross-SEAN, a cross-stitch based semi-supervised end-to-end neural attention model, which leverages the large amount of unlabelled data. Cross-SEAN partially generalises to emerging fake news as it learns from relevant external knowledge. We compare Cross-SEAN with seven state-of-the-art fake news detection methods. We observe that it achieves $0.95$ F1 Score on CTF, outperforming the best baseline by $9\%$. We also develop Chrome-SEAN, a Cross-SEAN based chrome extension for real-time detection of fake tweets.