 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval 2023 Task 6: LegalEval - Understanding Legal Texts
May 01, 2023



In populous countries, pending legal cases have been growing exponentially. There is a need for developing NLP-based techniques for processing and automatically understanding legal documents. To promote research in the area of Legal NLP we organized the shared task LegalEval - Understanding Legal Texts at SemEval 2023. LegalEval task has three sub-tasks: Task-A (Rhetorical Roles Labeling) is about automatically structuring legal documents into semantically coherent units, Task-B (Legal Named Entity Recognition) deals with identifying relevant entities in a legal document and Task-C (Court Judgement Prediction with Explanation) explores the possibility of automatically predicting the outcome of a legal case along with providing an explanation for the prediction. In total 26 teams (approx. 100 participants spread across the world) submitted systems paper. In each of the sub-tasks, the proposed systems outperformed the baselines; however, there is a lot of scope for improvement. This paper describes the tasks, and analyzes techniques proposed by various teams.
Multi-Task Learning Framework for Extracting Emotion Cause Span and Entailment in Conversations
Nov 07, 2022



Predicting emotions expressed in text is a well-studied problem in the NLP community. Recently there has been active research in extracting the cause of an emotion expressed in text. Most of the previous work has done causal emotion entailment in documents. In this work, we propose neural models to extract emotion cause span and entailment in conversations. For learning such models, we use RECCON dataset, which is annotated with cause spans at the utterance level. In particular, we propose MuTEC, an end-to-end Multi-Task learning framework for extracting emotions, emotion cause, and entailment in conversations. This is in contrast to existing baseline models that use ground truth emotions to extract the cause. MuTEC performs better than the baselines for most of the data folds provided in the dataset.
Generalized Product-of-Experts for Learning Multimodal Representations in Noisy Environments
Nov 07, 2022A real-world application or setting involves interaction between different modalities (e.g., video, speech, text). In order to process the multimodal information automatically and use it for an end application, Multimodal Representation Learning (MRL) has emerged as an active area of research in recent times. MRL involves learning reliable and robust representations of information from heterogeneous sources and fusing them. However, in practice, the data acquired from different sources are typically noisy. In some extreme cases, a noise of large magnitude can completely alter the semantics of the data leading to inconsistencies in the parallel multimodal data. In this paper, we propose a novel method for multimodal representation learning in a noisy environment via the generalized product of experts technique. In the proposed method, we train a separate network for each modality to assess the credibility of information coming from that modality, and subsequently, the contribution from each modality is dynamically varied while estimating the joint distribution. We evaluate our method on two challenging benchmarks from two diverse domains: multimodal 3D hand-pose estimation and multimodal surgical video segmentation. We attain state-of-the-art performance on both benchmarks. Our extensive quantitative and qualitative evaluations show the advantages of our method compared to previous approaches.
COGMEN: COntextualized GNN based Multimodal Emotion recognitioN
May 05, 2022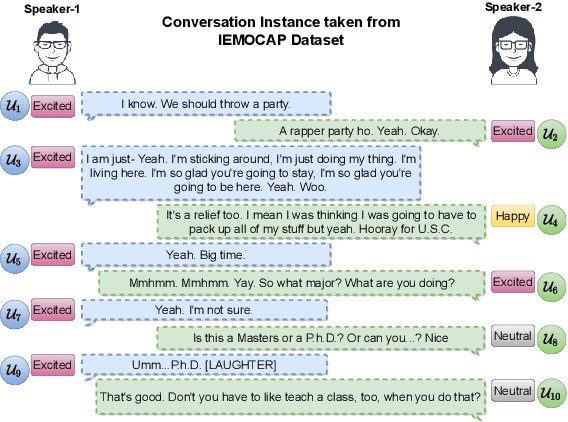
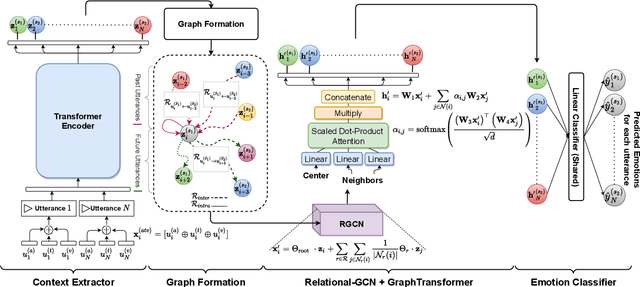
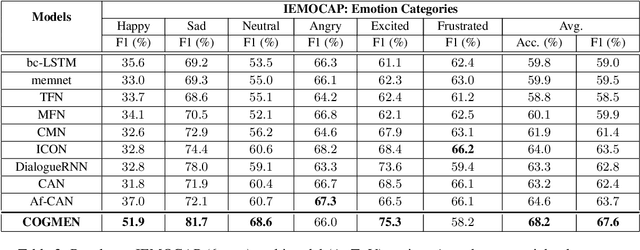
Emotions are an inherent part of human interactions, and consequently, it is imperative to develop AI systems that understand and recognize human emotions. During a conversation involving various people, a person's emotions are influenced by the other speaker's utterances and their own emotional state over the utterances. In this paper, we propose COntextualized Graph Neural Network based Multimodal Emotion recognitioN (COGMEN) system that leverages local information (i.e., inter/intra dependency between speakers) and global information (context). The proposed model uses Graph Neural Network (GNN) based architecture to model the complex dependencies (local and global information) in a conversation. Our model gives state-of-the-art (SOTA) results on IEMOCAP and MOSEI datasets, and detailed ablation experiments show the importance of modeling information at both levels.
HLDC: Hindi Legal Documents Corpus
Apr 02, 2022

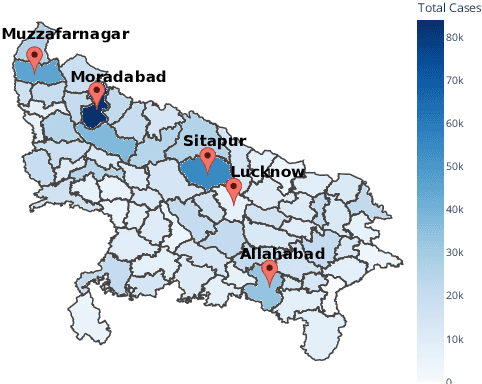
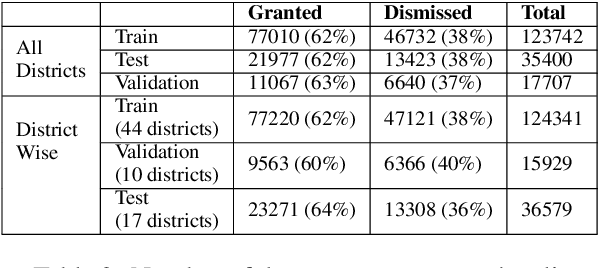
Many populous countries including India are burdened with a considerable backlog of legal cases. Development of automated systems that could process legal documents and augment legal practitioners can mitigate this. However, there is a dearth of high-quality corpora that is needed to develop such data-driven systems. The problem gets even more pronounced in the case of low resource languages such as Hindi. In this resource paper, we introduce the Hindi Legal Documents Corpus (HLDC), a corpus of more than 900K legal documents in Hindi. Documents are cleaned and structured to enable the development of downstream applications. Further, as a use-case for the corpus, we introduce the task of bail prediction. We experiment with a battery of models and propose a Multi-Task Learning (MTL) based model for the same. MTL models use summarization as an auxiliary task along with bail prediction as the main task. Experiments with different models are indicative of the need for further research in this area. We release the corpus and model implementation code with this paper: https://github.com/Exploration-Lab/HLDC
Corpus for Automatic Structuring of Legal Documents
Jan 31, 2022
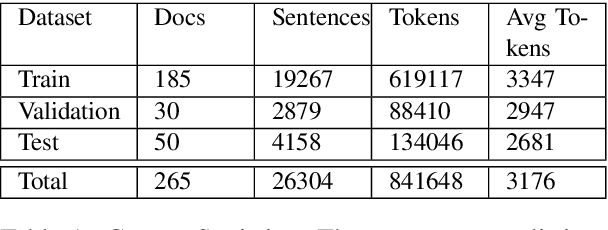
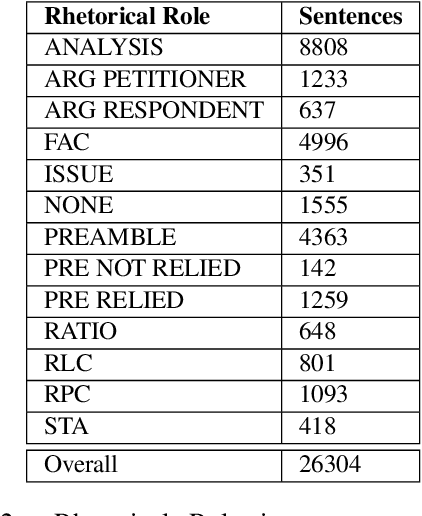
In populous countries, pending legal cases have been growing exponentially. There is a need for developing techniques for processing and organizing legal documents. In this paper, we introduce a new corpus for structuring legal documents. In particular, we introduce a corpus of legal judgment documents in English that are segmented into topical and coherent parts. Each of these parts is annotated with a label coming from a list of pre-defined Rhetorical Roles. We develop baseline models for automatically predicting rhetorical roles in a legal document based on the annotated corpus. Further, we show the application of rhetorical roles to improve performance on the tasks of summarization and legal judgment prediction. We release the corpus and baseline model code along with the paper.
Shapes of Emotions: Multimodal Emotion Recognition in Conversations via Emotion Shifts
Dec 03, 2021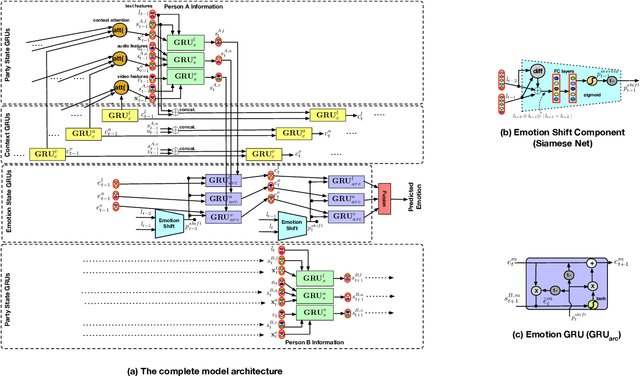
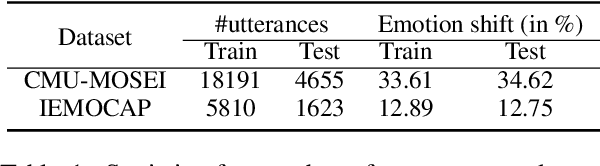
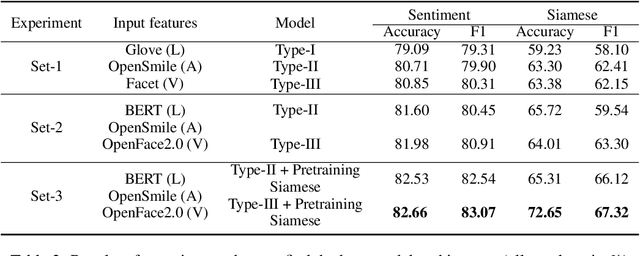
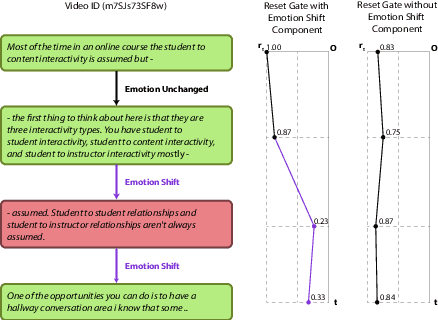
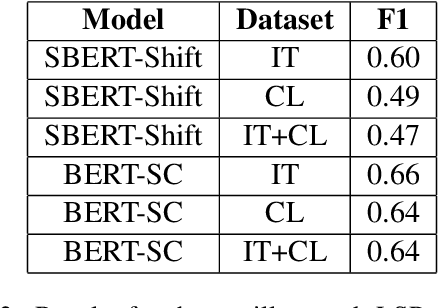
Emotion Recognition in Conversations (ERC) is an important and active research problem. Recent work has shown the benefits of using multiple modalities (e.g., text, audio, and video) for the ERC task. In a conversation, participants tend to maintain a particular emotional state unless some external stimuli evokes a change. There is a continuous ebb and flow of emotions in a conversation. Inspired by this observation, we propose a multimodal ERC model and augment it with an emotion-shift component. The proposed emotion-shift component is modular and can be added to any existing multimodal ERC model (with a few modifications), to improve emotion recognition. We experiment with different variants of the model, and results show that the inclusion of emotion shift signal helps the model to outperform existing multimodal models for ERC and hence showing the state-of-the-art performance on MOSEI and IEMOCAP datasets.
Semantic Segmentation of Legal Documents via Rhetorical Roles
Dec 03, 2021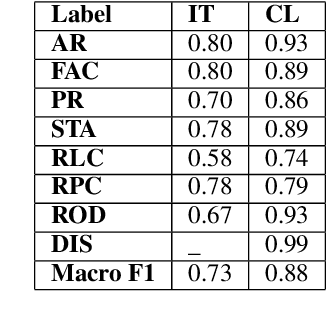
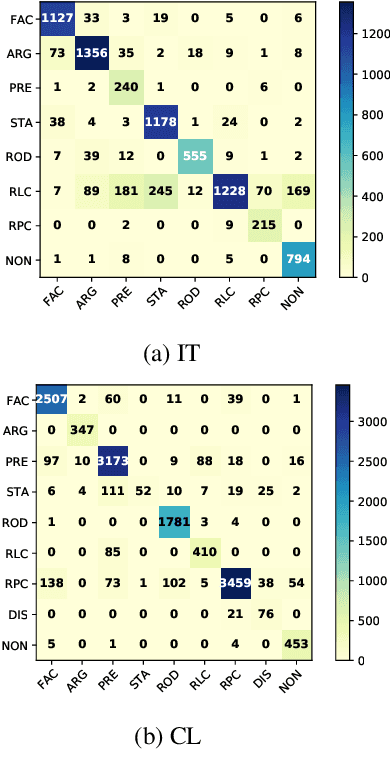
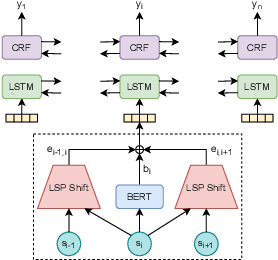
Legal documents are unstructured, use legal jargon, and have considerable length, making it difficult to process automatically via conventional text processing techniques. A legal document processing system would benefit substantially if the documents could be semantically segmented into coherent units of information. This paper proposes a Rhetorical Roles (RR) system for segmenting a legal document into semantically coherent units: facts, arguments, statute, issue, precedent, ruling, and ratio. With the help of legal experts, we propose a set of 13 fine-grained rhetorical role labels and create a new corpus of legal documents annotated with the proposed RR. We develop a system for segmenting a document into rhetorical role units. In particular, we develop a multitask learning-based deep learning model with document rhetorical role label shift as an auxiliary task for segmenting a legal document. We experiment extensively with various deep learning models for predicting rhetorical roles in a document, and the proposed model shows superior performance over the existing models. Further, we apply RR for predicting the judgment of legal cases and show that the use of RR enhances the prediction compared to the transformer-based models.
Fine-Grained Emotion Prediction by Modeling Emotion Definitions
Jul 26, 2021
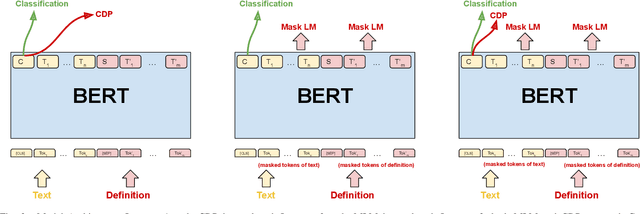
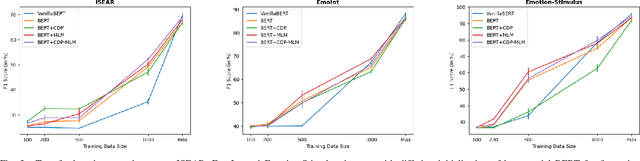

In this paper, we propose a new framework for fine-grained emotion prediction in the text through emotion definition modeling. Our approach involves a multi-task learning framework that models definitions of emotions as an auxiliary task while being trained on the primary task of emotion prediction. We model definitions using masked language modeling and class definition prediction tasks. Our models outperform existing state-of-the-art for fine-grained emotion dataset GoEmotions. We further show that this trained model can be used for transfer learning on other benchmark datasets in emotion prediction with varying emotion label sets, domains, and sizes. The proposed models outperform the baselines on transfer learning experiments demonstrating the generalization capability of the models.
Pre-trained Language Models as Prior Knowledge for Playing Text-based Games
Jul 18, 2021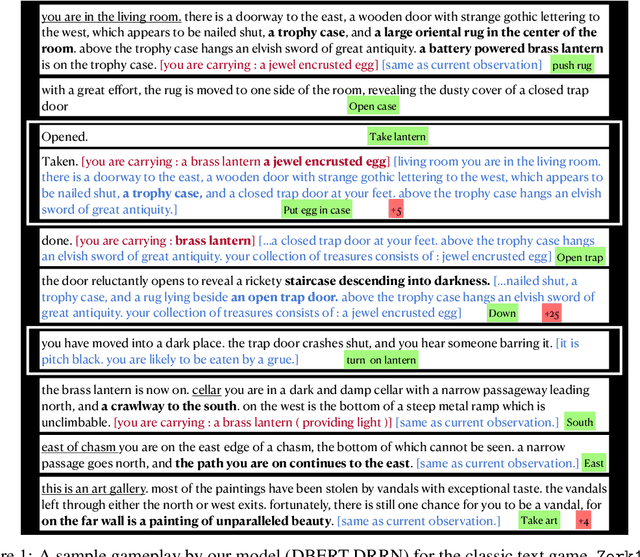
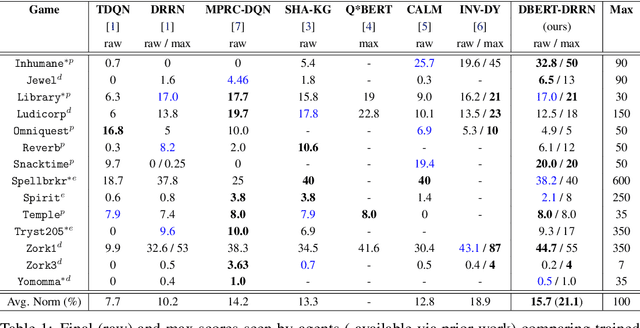
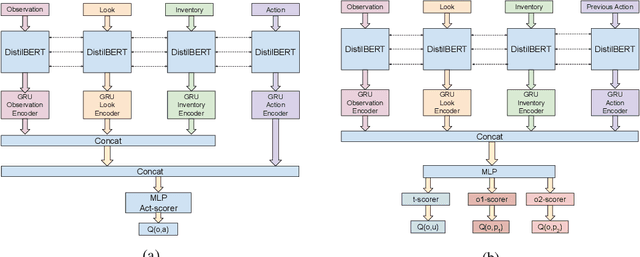
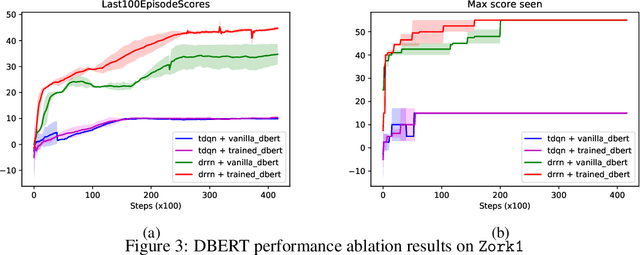
Recently, text world games have been proposed to enable artificial agents to understand and reason about real-world scenarios. These text-based games are challenging for artificial agents, as it requires understanding and interaction using natural language in a partially observable environment. In this paper, we improve the semantic understanding of the agent by proposing a simple RL with LM framework where we use transformer-based language models with Deep RL models. We perform a detailed study of our framework to demonstrate how our model outperforms all existing agents on the popular game, Zork1, to achieve a score of 44.7, which is 1.6 higher than the state-of-the-art model. Our proposed approach also performs comparably to the state-of-the-art models on the other set of text games.