 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDformer: Efficient End-to-End Transformer for Depth Completion
Sep 12, 2024



Depth completion aims to predict dense depth maps with sparse depth measurements from a depth sensor. Currently, Convolutional Neural Network (CNN) based models are the most popular methods applied to depth completion tasks. However, despite the excellent high-end performance, they suffer from a limited representation area. To overcome the drawbacks of CNNs, a more effective and powerful method has been presented: the Transformer, which is an adaptive self-attention setting sequence-to-sequence model. While the standard Transformer quadratically increases the computational cost from the key-query dot-product of input resolution which improperly employs depth completion tasks. In this work, we propose a different window-based Transformer architecture for depth completion tasks named Sparse-to-Dense Transformer (SDformer). The network consists of an input module for the depth map and RGB image features extraction and concatenation, a U-shaped encoder-decoder Transformer for extracting deep features, and a refinement module. Specifically, we first concatenate the depth map features with the RGB image features through the input model. Then, instead of calculating self-attention with the whole feature maps, we apply different window sizes to extract the long-range depth dependencies. Finally, we refine the predicted features from the input module and the U-shaped encoder-decoder Transformer module to get the enriching depth features and employ a convolution layer to obtain the dense depth map. In practice, the SDformer obtains state-of-the-art results against the CNN-based depth completion models with lower computing loads and parameters on the NYU Depth V2 and KITTI DC datasets.
Measuring Similarity: Computationally Reproducing the Scholar's Interests
Dec 14, 2018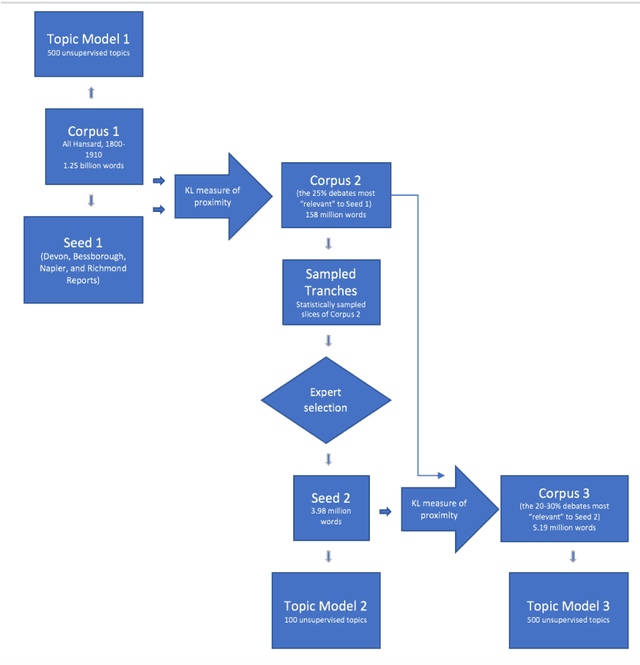
Computerized document classification already orders the news articles that Apple's "News" app or Google's "personalized search" feature groups together to match a reader's interests. The invisible and therefore illegible decisions that go into these tailored searches have been the subject of a critique by scholars who emphasize that our intelligence about documents is only as good as our ability to understand the criteria of search. This article will attempt to unpack the procedures used in computational classification of texts, translating them into term legible to humanists, and examining opportunities to render the computational text classification process subject to expert critique and improvement.
Mining Spatio-temporal Data on Industrialization from Historical Registries
Dec 03, 2016
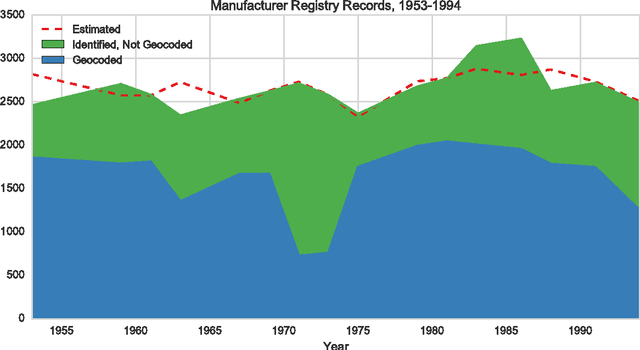
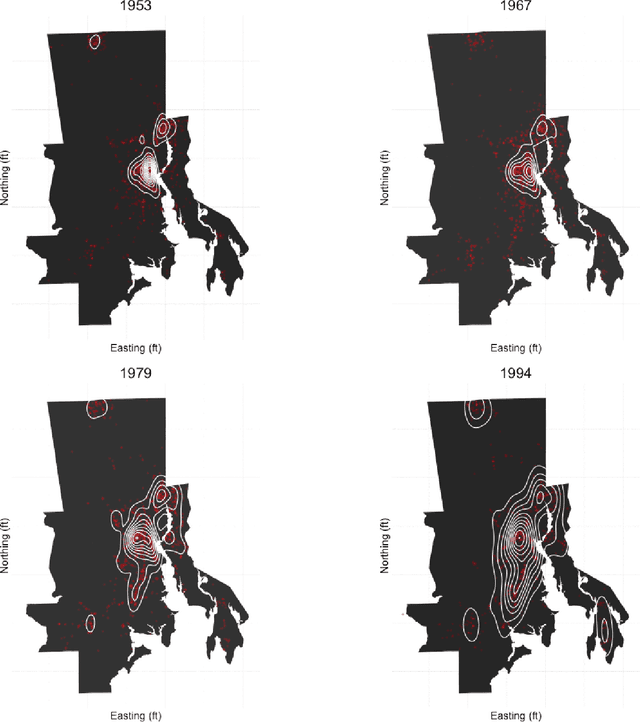
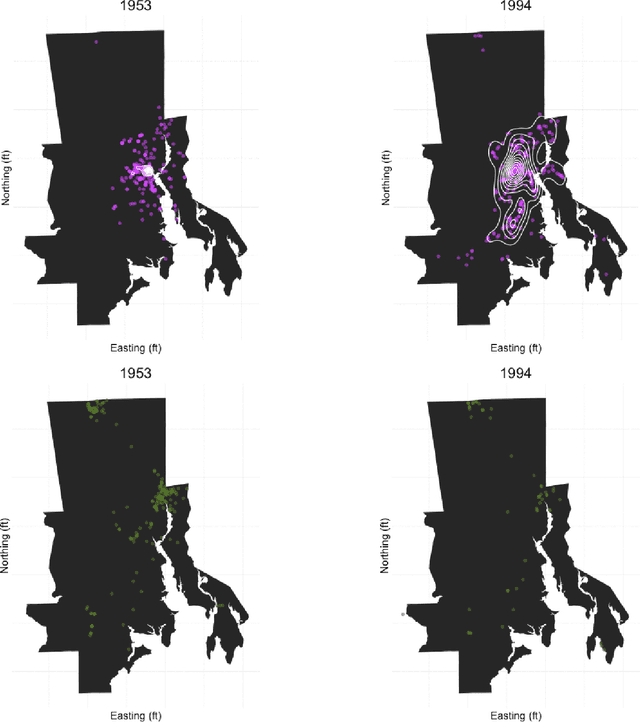
Despite the growing availability of big data in many fields, historical data on socioevironmental phenomena are often not available due to a lack of automated and scalable approaches for collecting, digitizing, and assembling them. We have developed a data-mining method for extracting tabulated, geocoded data from printed directories. While scanning and optical character recognition (OCR) can digitize printed text, these methods alone do not capture the structure of the underlying data. Our pipeline integrates both page layout analysis and OCR to extract tabular, geocoded data from structured text. We demonstrate the utility of this method by applying it to scanned manufacturing registries from Rhode Island that record 41 years of industrial land use. The resulting spatio-temporal data can be used for socioenvironmental analyses of industrialization at a resolution that was not previously possible. In particular, we find strong evidence for the dispersion of manufacturing from the urban core of Providence, the state's capital, along the Interstate 95 corridor to the north and south.