 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023



Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
Revisiting Heterophily in Graph Convolution Networks by Learning Representations Across Topological and Feature Spaces
Nov 02, 2022



Graph convolution networks (GCNs) have been enormously successful in learning representations over several graph-based machine learning tasks. Specific to learning rich node representations, most of the methods have solely relied on the homophily assumption and have shown limited performance on the heterophilous graphs. While several methods have been developed with new architectures to address heterophily, we argue that by learning graph representations across two spaces i.e., topology and feature space GCNs can address heterophily. In this work, we experimentally demonstrate the performance of the proposed GCN framework over semi-supervised node classification task on both homophilous and heterophilous graph benchmarks by learning and combining representations across the topological and the feature spaces.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022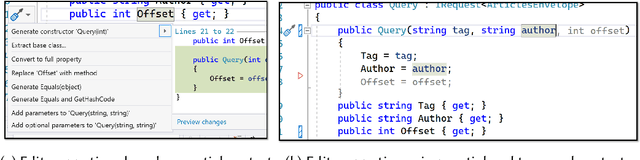


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
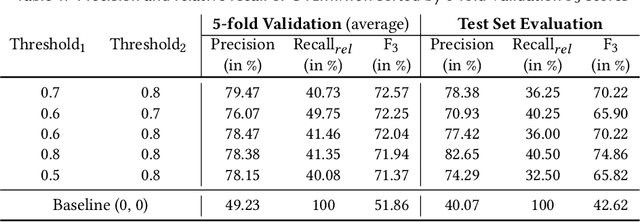
Neurosymbolic Repair for Low-Code Formula Languages
Jul 24, 2022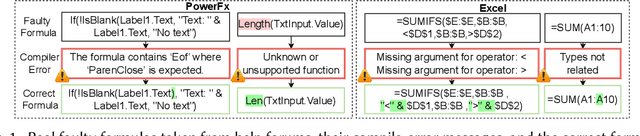
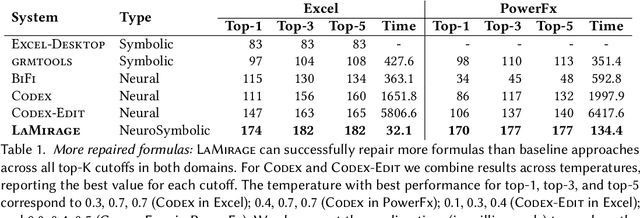

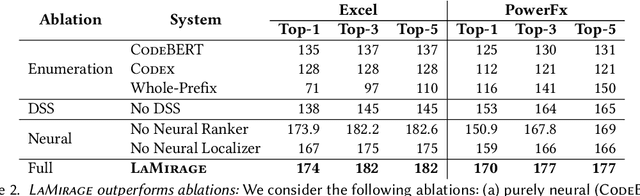
Most users of low-code platforms, such as Excel and PowerApps, write programs in domain-specific formula languages to carry out nontrivial tasks. Often users can write most of the program they want, but introduce small mistakes that yield broken formulas. These mistakes, which can be both syntactic and semantic, are hard for low-code users to identify and fix, even though they can be resolved with just a few edits. We formalize the problem of producing such edits as the last-mile repair problem. To address this problem, we developed LaMirage, a LAst-MIle RepAir-engine GEnerator that combines symbolic and neural techniques to perform last-mile repair in low-code formula languages. LaMirage takes a grammar and a set of domain-specific constraints/rules, which jointly approximate the target language, and uses these to generate a repair engine that can fix formulas in that language. To tackle the challenges of localizing the errors and ranking the candidate repairs, LaMirage leverages neural techniques, whereas it relies on symbolic methods to generate candidate repairs. This combination allows LaMirage to find repairs that satisfy the provided grammar and constraints, and then pick the most natural repair. We compare LaMirage to state-of-the-art neural and symbolic approaches on 400 real Excel and PowerFx formulas, where LaMirage outperforms all baselines. We release these benchmarks to encourage subsequent work in low-code domains.
DeepPS2: Revisiting Photometric Stereo Using Two Differently Illuminated Images
Jul 05, 2022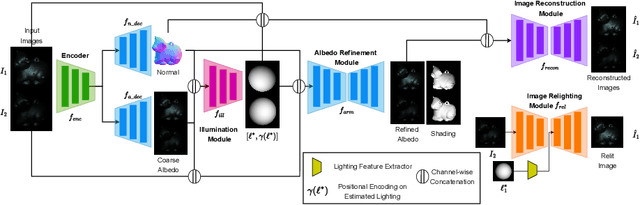
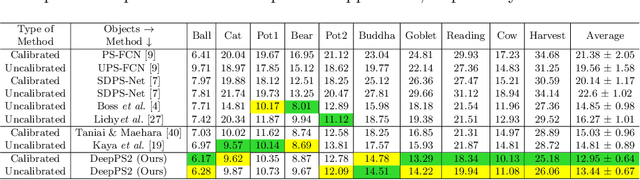
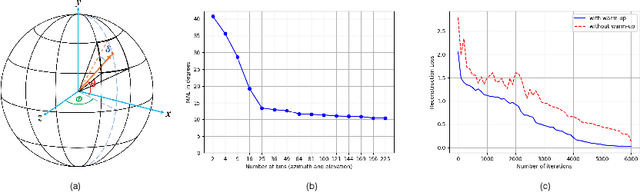
Photometric stereo, a problem of recovering 3D surface normals using images of an object captured under different lightings, has been of great interest and importance in computer vision research. Despite the success of existing traditional and deep learning-based methods, it is still challenging due to: (i) the requirement of three or more differently illuminated images, (ii) the inability to model unknown general reflectance, and (iii) the requirement of accurate 3D ground truth surface normals and known lighting information for training. In this work, we attempt to address an under-explored problem of photometric stereo using just two differently illuminated images, referred to as the PS2 problem. It is an intermediate case between a single image-based reconstruction method like Shape from Shading (SfS) and the traditional Photometric Stereo (PS), which requires three or more images. We propose an inverse rendering-based deep learning framework, called DeepPS2, that jointly performs surface normal, albedo, lighting estimation, and image relighting in a completely self-supervised manner with no requirement of ground truth data. We demonstrate how image relighting in conjunction with image reconstruction enhances the lighting estimation in a self-supervised setting.
Multi-Agent Spatial Predictive Control with Application to Drone Flocking (Extended Version)
Mar 31, 2022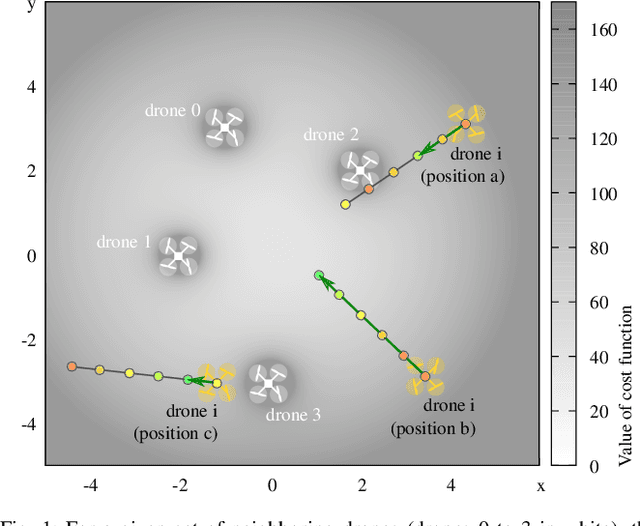
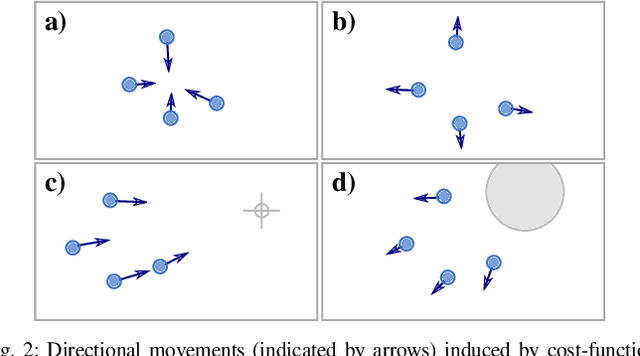
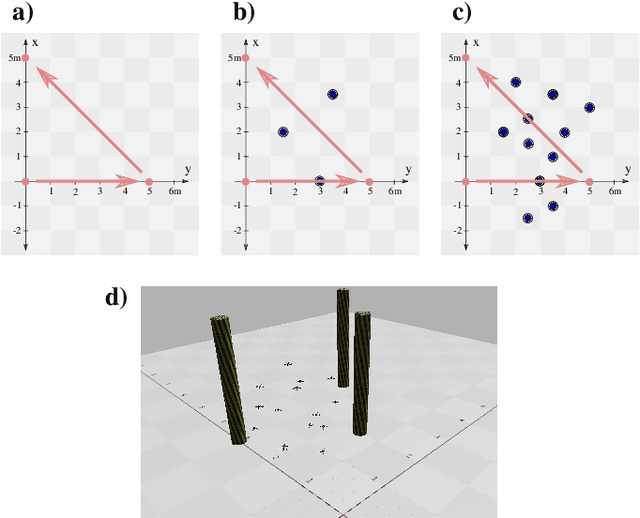
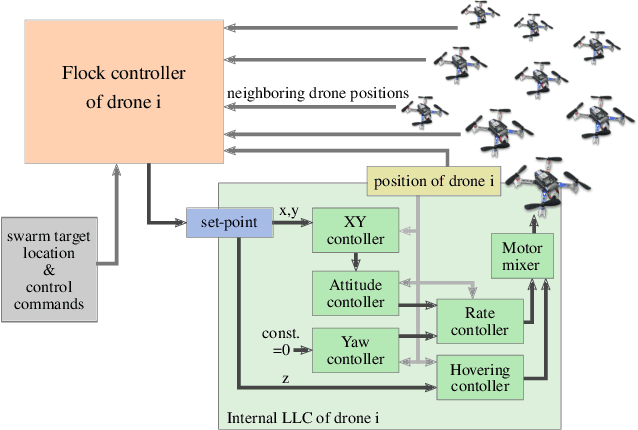
We introduce the novel concept of Spatial Predictive Control (SPC) to solve the following problem: given a collection of agents (e.g., drones) with positional low-level controllers (LLCs) and a mission-specific distributed cost function, how can a distributed controller achieve and maintain cost-function minimization without a plant model and only positional observations of the environment? Our fully distributed SPC controller is based strictly on the position of the agent itself and on those of its neighboring agents. This information is used in every time-step to compute the gradient of the cost function and to perform a spatial look-ahead to predict the best next target position for the LLC. Using a high-fidelity simulation environment, we show that SPC outperforms the most closely related class of controllers, Potential Field Controllers, on the drone flocking problem. We also show that SPC is able to cope with a potential sim-to-real transfer gap by demonstrating its performance on real hardware, namely our implementation of flocking using nine Crazyflie 2.1 drones.
Synchromesh: Reliable code generation from pre-trained language models
Jan 26, 2022

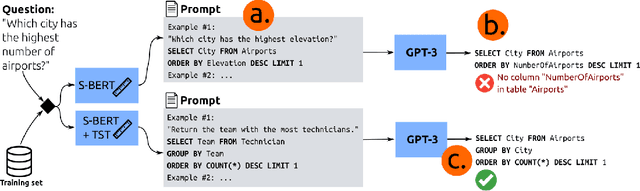
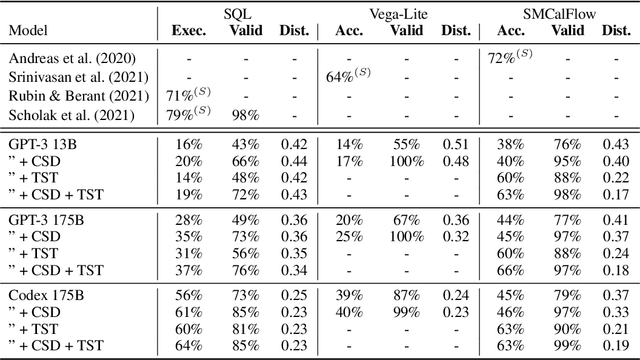
Large pre-trained language models have been used to generate code,providing a flexible interface for synthesizing programs from natural language specifications. However, they often violate syntactic and semantic rules of their output language, limiting their practical usability. In this paper, we propose Synchromesh: a framework for substantially improving the reliability of pre-trained models for code generation. Synchromesh comprises two components. First, it retrieves few-shot examples from a training bank using Target Similarity Tuning (TST), a novel method for semantic example selection. TST learns to recognize utterances that describe similar target programs despite differences in surface natural language features. Then, Synchromesh feeds the examples to a pre-trained language model and samples programs using Constrained Semantic Decoding (CSD): a general framework for constraining the output to a set of valid programs in the target language. CSD leverages constraints on partial outputs to sample complete correct programs, and needs neither re-training nor fine-tuning of the language model. We evaluate our methods by synthesizing code from natural language descriptions using GPT-3 and Codex in three real-world languages: SQL queries, Vega-Lite visualizations and SMCalFlow programs. These domains showcase rich constraints that CSD is able to enforce, including syntax, scope, typing rules, and contextual logic. We observe substantial complementary gains from CSD and TST in prediction accuracy and in effectively preventing run-time errors.
Multi-modal Program Inference: a Marriage of Pre-trainedLanguage Models and Component-based Synthesis
Sep 03, 2021
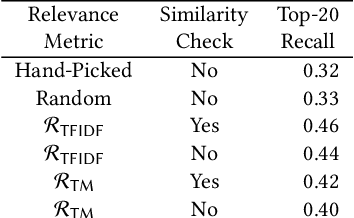


Multi-modal program synthesis refers to the task of synthesizing programs (code) from their specification given in different forms, such as a combination of natural language and examples. Examples provide a precise but incomplete specification, and natural language provides an ambiguous but more "complete" task description. Machine-learned pre-trained models (PTMs) are adept at handling ambiguous natural language, but struggle with generating syntactically and semantically precise code. Program synthesis techniques can generate correct code, often even from incomplete but precise specifications, such as examples, but they are unable to work with the ambiguity of natural languages. We present an approach that combines PTMs with component-based synthesis (CBS): PTMs are used to generate candidates programs from the natural language description of the task, which are then used to guide the CBS procedure to find the program that matches the precise examples-based specification. We use our combination approach to instantiate multi-modal synthesis systems for two programming domains: the domain of regular expressions and the domain of CSS selectors. Our evaluation demonstrates the effectiveness of our domain-agnostic approach in comparison to a state-of-the-art specialized system, and the generality of our approach in providing multi-modal program synthesis from natural language and examples in different programming domains.
Shadow Art Revisited: A Differentiable Rendering Based Approach
Jul 30, 2021
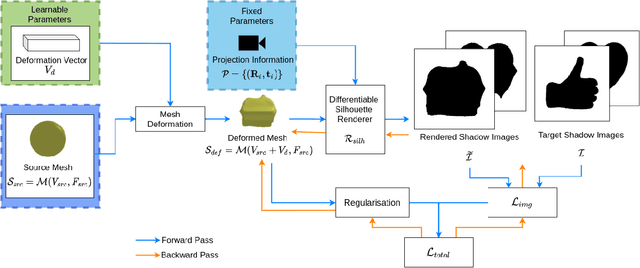
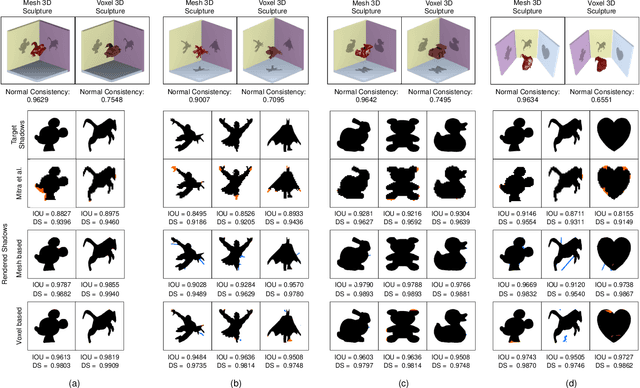
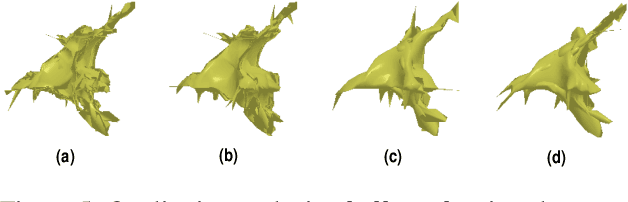
While recent learning based methods have been observed to be superior for several vision-related applications, their potential in generating artistic effects has not been explored much. One such interesting application is Shadow Art - a unique form of sculptural art where 2D shadows cast by a 3D sculpture produce artistic effects. In this work, we revisit shadow art using differentiable rendering based optimization frameworks to obtain the 3D sculpture from a set of shadow (binary) images and their corresponding projection information. Specifically, we discuss shape optimization through voxel as well as mesh-based differentiable renderers. Our choice of using differentiable rendering for generating shadow art sculptures can be attributed to its ability to learn the underlying 3D geometry solely from image data, thus reducing the dependence on 3D ground truth. The qualitative and quantitative results demonstrate the potential of the proposed framework in generating complex 3D sculptures that go beyond those seen in contemporary art pieces using just a set of shadow images as input. Further, we demonstrate the generation of 3D sculptures to cast shadows of faces, animated movie characters, and applicability of the framework to sketch-based 3D reconstruction of underlying shapes.
Information-theoretic User Interaction: Significant Inputs for Program Synthesis
Jun 22, 2020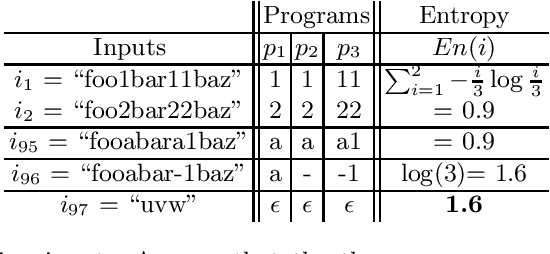
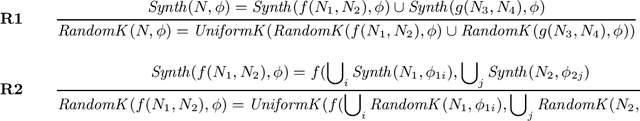
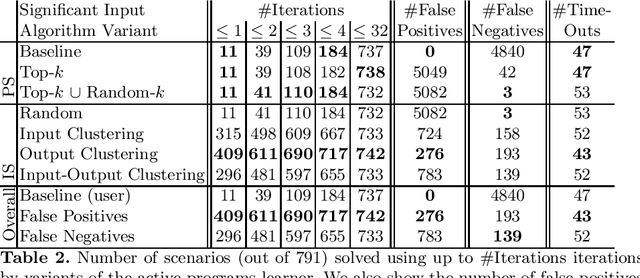
Programming-by-example technologies are being deployed in industrial products for real-time synthesis of various kinds of data transformations. These technologies rely on the user to provide few representative examples of the transformation task. Motivated by the need to find the most pertinent question to ask the user, in this paper, we introduce the {\em significant questions problem}, and show that it is hard in general. We then develop an information-theoretic greedy approach for solving the problem. We justify the greedy algorithm using the conditional entropy result, which informally says that the question that achieves the maximum information gain is the one that we know least about. In the context of interactive program synthesis, we use the above result to develop an {\em{active program learner}} that generates the significant inputs to pose as queries to the user in each iteration. The procedure requires extending a {\em{passive program learner}} to a {\em{sampling program learner}} that is able to sample candidate programs from the set of all consistent programs to enable estimation of information gain. It also uses clustering of inputs based on features in the inputs and the corresponding outputs to sample a small set of candidate significant inputs. Our active learner is able to tradeoff false negatives for false positives and converge in a small number of iterations on a real-world dataset of %around 800 string transformation tasks.