 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormative Study for AI-assisted Data Visualization
Sep 10, 2024


This formative study investigates the impact of data quality on AI-assisted data visualizations, focusing on how uncleaned datasets influence the outcomes of these tools. By generating visualizations from datasets with inherent quality issues, the research aims to identify and categorize the specific visualization problems that arise. The study further explores potential methods and tools to address these visualization challenges efficiently and effectively. Although tool development has not yet been undertaken, the findings emphasize enhancing AI visualization tools to handle flawed data better. This research underscores the critical need for more robust, user-friendly solutions that facilitate quicker and easier correction of data and visualization errors, thereby improving the overall reliability and usability of AI-assisted data visualization processes.
Neurosymbolic Repair for Low-Code Formula Languages
Jul 24, 2022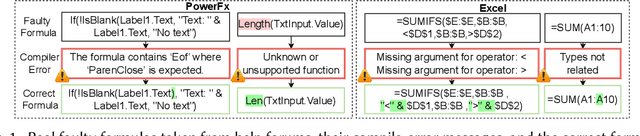
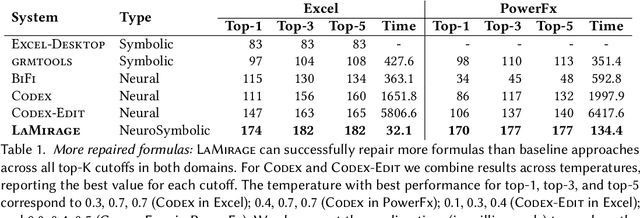

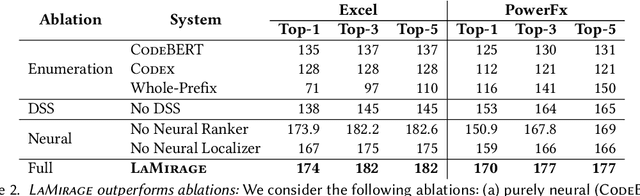
Most users of low-code platforms, such as Excel and PowerApps, write programs in domain-specific formula languages to carry out nontrivial tasks. Often users can write most of the program they want, but introduce small mistakes that yield broken formulas. These mistakes, which can be both syntactic and semantic, are hard for low-code users to identify and fix, even though they can be resolved with just a few edits. We formalize the problem of producing such edits as the last-mile repair problem. To address this problem, we developed LaMirage, a LAst-MIle RepAir-engine GEnerator that combines symbolic and neural techniques to perform last-mile repair in low-code formula languages. LaMirage takes a grammar and a set of domain-specific constraints/rules, which jointly approximate the target language, and uses these to generate a repair engine that can fix formulas in that language. To tackle the challenges of localizing the errors and ranking the candidate repairs, LaMirage leverages neural techniques, whereas it relies on symbolic methods to generate candidate repairs. This combination allows LaMirage to find repairs that satisfy the provided grammar and constraints, and then pick the most natural repair. We compare LaMirage to state-of-the-art neural and symbolic approaches on 400 real Excel and PowerFx formulas, where LaMirage outperforms all baselines. We release these benchmarks to encourage subsequent work in low-code domains.
Through the Data Management Lens: Experimental Analysis and Evaluation of Fair Classification
Jan 18, 2021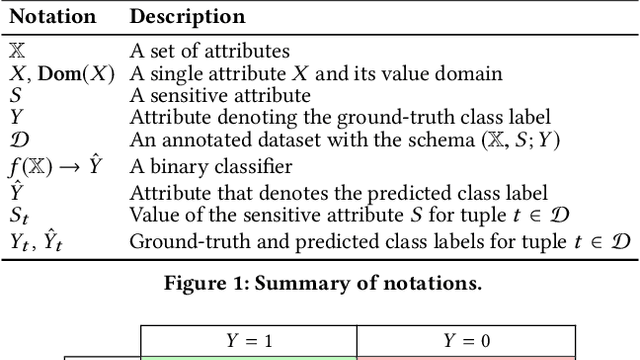
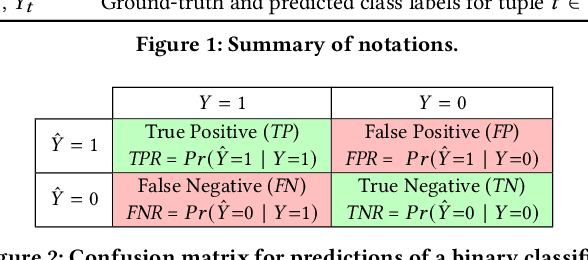
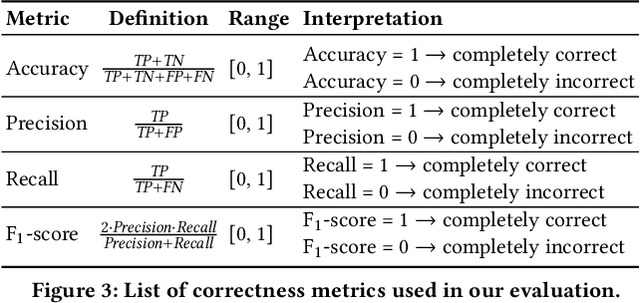
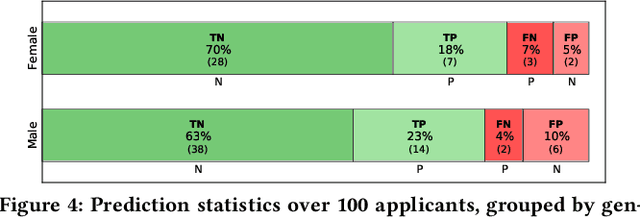
Classification, a heavily-studied data-driven machine learning task, drives an increasing number of prediction systems involving critical human decisions such as loan approval and criminal risk assessment. However, classifiers often demonstrate discriminatory behavior, especially when presented with biased data. Consequently, fairness in classification has emerged as a high-priority research area. Data management research is showing an increasing presence and interest in topics related to data and algorithmic fairness, including the topic of fair classification. The interdisciplinary efforts in fair classification, with machine learning research having the largest presence, have resulted in a large number of fairness notions and a wide range of approaches that have not been systematically evaluated and compared. In this paper, we contribute a broad analysis of 13 fair classification approaches and additional variants, over their correctness, fairness, efficiency, scalability, and stability, using a variety of metrics and real-world datasets. Our analysis highlights novel insights on the impact of different metrics and high-level approach characteristics on different aspects of performance. We also discuss general principles for choosing approaches suitable for different practical settings, and identify areas where data-management-centric solutions are likely to have the most impact.