 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Sensitivity in Lean 4 Autoformalization
Apr 25, 2026Natural-language variation poses a key challenge in Lean autoformalization: semantically equivalent paraphrases of the same theorem statements can induce divergent formal outputs, yet it remains unclear whether this variation reflects semantic disagreements or shallower failures. We investigate this question in Lean 4 using 60 deterministic paraphrase rules applied to ProofNet\# and miniF2F. Across four GPT-family models and three open-weight 7B autoformalizers, we find that the observed paraphrase sensitivity reflects compilation-boundary failures rather than semantic divergence among successful formalizations. In particular, when both baseline and perturbed outputs compile, paired predictions are semantically equivalent under BEq+ and structurally near-identical under GTED. By contrast, paraphrasing substantially affects whether outputs compile, with failure modes varying across datasets and perturbation classes. Our results suggest that future training-time interventions should target the compile boundary rather than the semantic layer, and that benchmarks should separate compile-conditional equivalence from surface consistency.
Lightweight Multi-Drone Detection and 3D-Localization via YOLO
Feb 18, 2022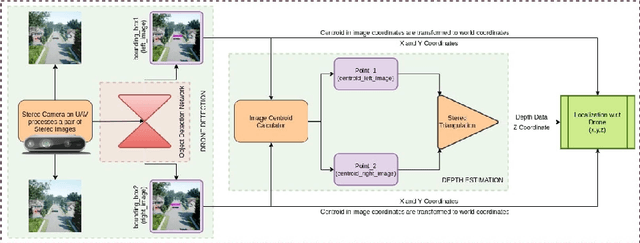
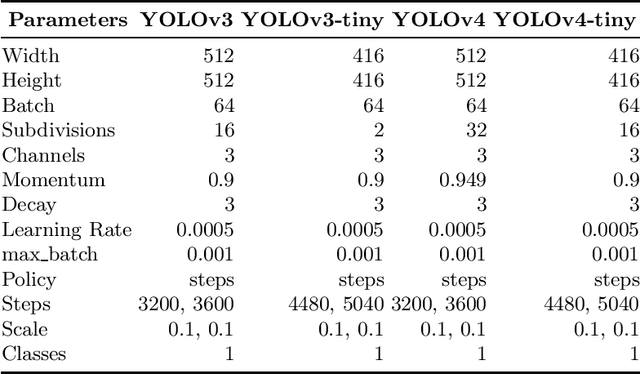
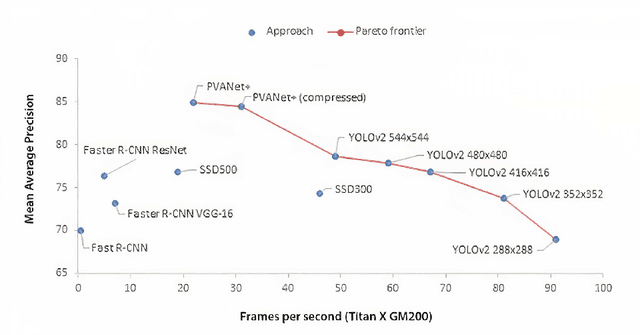
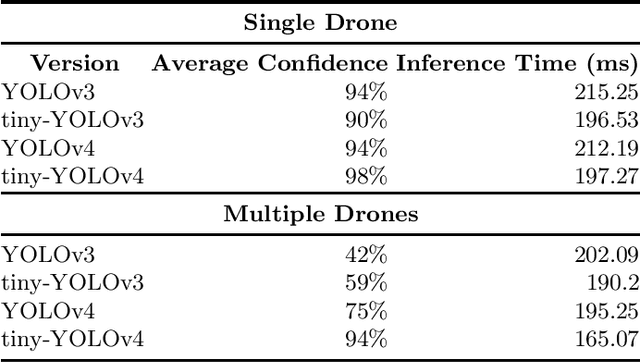
In this work, we present and evaluate a method to perform real-time multiple drone detection and three-dimensional localization using state-of-the-art tiny-YOLOv4 object detection algorithm and stereo triangulation. Our computer vision approach eliminates the need for computationally expensive stereo matching algorithms, thereby significantly reducing the memory footprint and making it deployable on embedded systems. Our drone detection system is highly modular (with support for various detection algorithms) and capable of identifying multiple drones in a system, with real-time detection accuracy of up to 77\% with an average FPS of 332 (on Nvidia Titan Xp). We also test the complete pipeline in AirSim environment, detecting drones at a maximum distance of 8 meters, with a mean error of $23\%$ of the distance. We also release the source code for the project, with pre-trained models and the curated synthetic stereo dataset.