 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame-Cluster Querying for Overlapping Clusters
Oct 28, 2019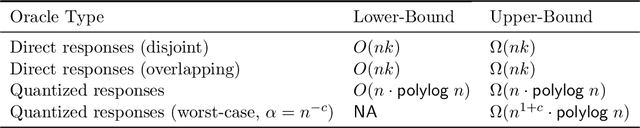

Overlapping clusters are common in models of many practical data-segmentation applications. Suppose we are given $n$ elements to be clustered into $k$ possibly overlapping clusters, and an oracle that can interactively answer queries of the form "do elements $u$ and $v$ belong to the same cluster?" The goal is to recover the clusters with minimum number of such queries. This problem has been of recent interest for the case of disjoint clusters. In this paper, we look at the more practical scenario of overlapping clusters, and provide upper bounds (with algorithms) on the sufficient number of queries. We provide algorithmic results under both arbitrary (worst-case) and statistical modeling assumptions. Our algorithms are parameter free, efficient, and work in the presence of random noise. We also derive information-theoretic lower bounds on the number of queries needed, proving that our algorithms are order optimal. Finally, we test our algorithms over both synthetic and real-world data, showing their practicality and effectiveness.
Semisupervised Clustering by Queries and Locally Encodable Source Coding
Mar 31, 2019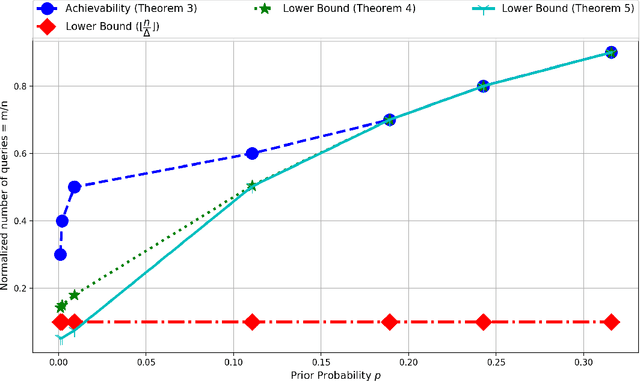
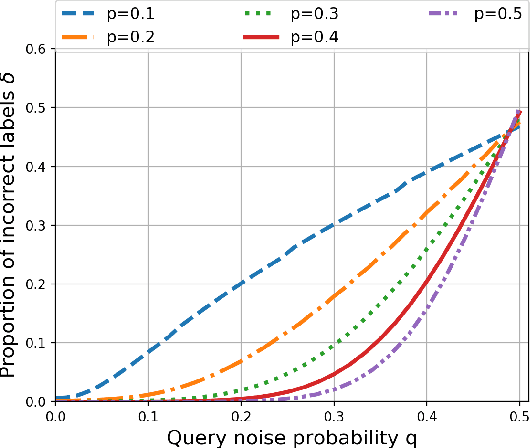
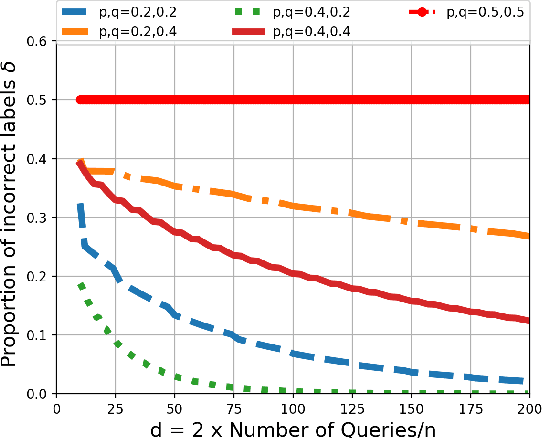
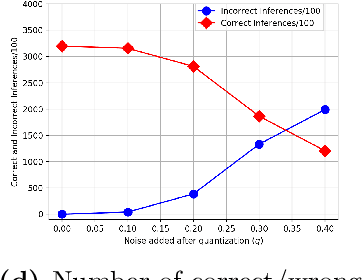
Source coding is the canonical problem of data compression in information theory. In a {\em locally encodable} source coding, each compressed bit depends on only few bits of the input. In this paper, we show that a recently popular model of semisupervised clustering is equivalent to locally encodable source coding. In this model, the task is to perform multiclass labeling of unlabeled elements. At the beginning, we can ask in parallel a set of simple queries to an oracle who provides (possibly erroneous) binary answers to the queries. The queries cannot involve more than two (or a fixed constant number $\Delta$ of) elements. Now the labeling of all the elements (or clustering) must be performed based on the (noisy) query answers. The goal is to recover all the correct labelings while minimizing the number of such queries. The equivalence to locally encodable source codes leads us to find lower bounds on the number of queries required in variety of scenarios. We are also able to show fundamental limitations of pairwise `same cluster' queries - and propose pairwise AND queries, that provably performs better in many situations.
High Dimensional Discrete Integration by Hashing and Optimization
Jun 29, 2018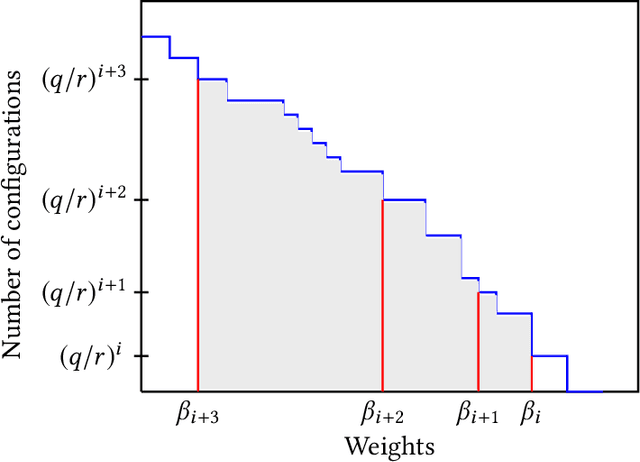
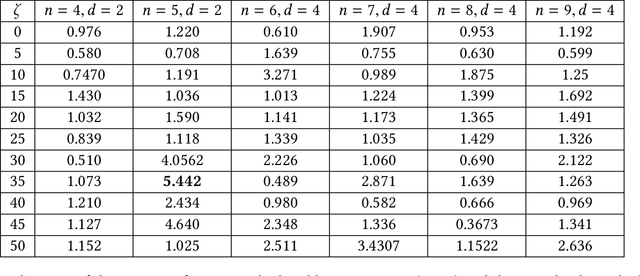
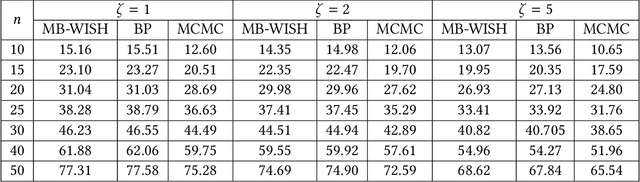
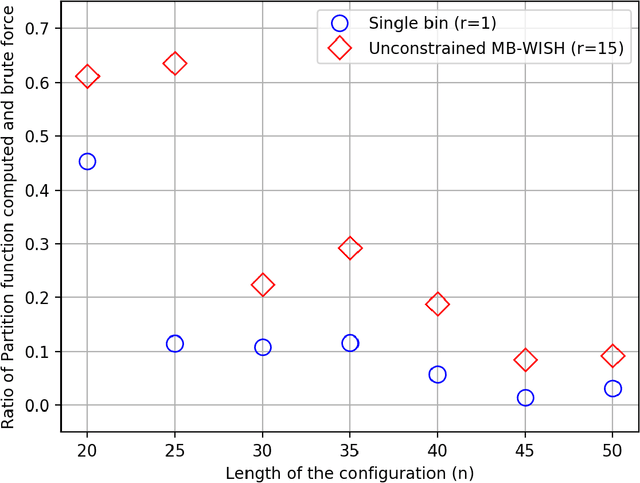
Recently Ermon et al. (2013) pioneered an ingenuous way to practically compute approximations to large scale counting or discrete integration problems by using random hashes. The hashes are used to reduce the counting problems into many separate discrete optimization problems. The optimization problems can be solved by an NP-oracle, and if they allow some amenable structure then commercial SAT solvers or linear programming (LP) solvers can be used in lieu of the NP-oracle. In particular, Ermon et al. has shown that if the domain of integration is $\{0,1\}^n$ then it is possible to obtain a $16$-approximation by this technique. In many crucial counting tasks, such as computation of partition function of ferromagnetic Potts model, the domain of integration is naturally $\{0,1,\dots, q-1\}^n, q>2$. A straightforward extension of Ermon et al.'s work would allow a $q^2$-approximation for this problem, assuming the existence of an optimization oracle. In this paper, we show that it is possible to obtain a $(2+\frac2{q-1})^2$-approximation to the discrete integration problem, when $q$ is a power of an odd prime (a similar expression follows for even $q$). We are able to achieve this by using an idea of optimization over multiple bins of the hash functions, that can be easily implemented by inequality constraints, or even in unconstrained way. Also the burden on the NP-oracle is not increased by our method (an LP solver can still be used). Furthermore, we provide a close-to-4-approximation for the permanent of a matrix by extending our technique. Note that, the domain of integration here is the symmetric group. Finally, we provide memory optimal hash functions that uses minimal number of random bits for the above purpose. We are able to obtain these structured hashes without sacrificing the amenability of the NP-oracle. We provide experimental simulation results to support our algorithms.
Robust Gradient Descent via Moment Encoding with LDPC Codes
May 22, 2018

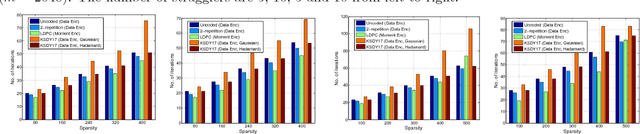
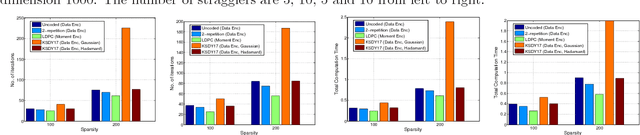
This paper considers the problem of implementing large-scale gradient descent algorithms in a distributed computing setting in the presence of {\em straggling} processors. To mitigate the effect of the stragglers, it has been previously proposed to encode the data with an erasure-correcting code and decode at the master server at the end of the computation. We, instead, propose to encode the second-moment of the data with a low density parity-check (LDPC) code. The iterative decoding algorithms for LDPC codes have very low computational overhead and the number of decoding iterations can be made to automatically adjust with the number of stragglers in the system. We show that for a random model for stragglers, the proposed moment encoding based gradient descent method can be viewed as the stochastic gradient descent method. This allows us to obtain convergence guarantees for the proposed solution. Furthermore, the proposed moment encoding based method is shown to outperform the existing schemes in a real distributed computing setup.
Connectivity in Random Annulus Graphs and the Geometric Block Model
Apr 12, 2018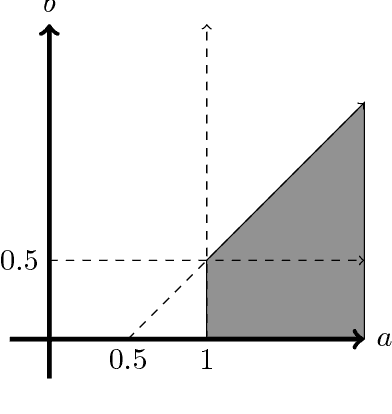


Random geometric graphs are the simplest, and perhaps the earliest possible random graph model of spatial networks, introduced by Gilbert in 1961. In the most basic setting, a random geometric graph $G(n,r)$ has $n$ vertices. Each vertex of the graph is assigned a real number in $[0,1]$ randomly and uniformly. There is an edge between two vertices if the corresponding two random numbers differ by at most $r$ (to mitigate the boundary effect, let us consider the Lee distance here, $d_L(u,v) = \min\{|u-v|, 1-|u-v|\}$). It is well-known that the connectivity threshold regime for random geometric graphs is at $r \approx \frac{\log n}{n}$. In particular, if $r = \frac{a\log n}{n}$, then a random geometric graph is connected with high probability if and only if $a > 1$. Consider $G(n,\frac{(1+\epsilon)\log{n}}{n})$ for any $\epsilon >0$ to satisfy the connectivity requirement and delete half of its edges which have distance at most $\frac{\log{n}}{2n}$. It is natural to believe that the resultant graph will be disconnected. Surprisingly, we show that the graph still remains connected! Formally, generalizing random geometric graphs, we define a random annulus graph $G(n, [r_1, r_2]), r_1 <r_2$ with $n$ vertices. Each vertex of the graph is assigned a real number in $[0,1]$ randomly and uniformly as before. There is an edge between two vertices if the Lee distance between the corresponding two random numbers is between $r_1$ and $r_2$, $0<r_1<r_2$. Let us assume $r_1 = \frac{b \log n}{n},$ and $r_2 = \frac{a \log n}{n}, 0 <b <a$. We show that this graph is connected with high probability if and only if $a -b > \frac12$ and $a >1$. That is $G(n, [0,\frac{0.99\log n}{n}])$ is not connected but $G(n,[\frac{0.50 \log n}{n},\frac{1+\epsilon \log n}{n}])$ is. This result is then used to give improved lower and upper bounds on the recovery threshold of the geometric block model.
Representation Learning and Recovery in the ReLU Model
Mar 12, 2018Rectified linear units, or ReLUs, have become the preferred activation function for artificial neural networks. In this paper we consider two basic learning problems assuming that the underlying data follow a generative model based on a ReLU-network -- a neural network with ReLU activations. As a primarily theoretical study, we limit ourselves to a single-layer network. The first problem we study corresponds to dictionary-learning in the presence of nonlinearity (modeled by the ReLU functions). Given a set of observation vectors $\mathbf{y}^i \in \mathbb{R}^d, i =1, 2, \dots , n$, we aim to recover $d\times k$ matrix $A$ and the latent vectors $\{\mathbf{c}^i\} \subset \mathbb{R}^k$ under the model $\mathbf{y}^i = \mathrm{ReLU}(A\mathbf{c}^i +\mathbf{b})$, where $\mathbf{b}\in \mathbb{R}^d$ is a random bias. We show that it is possible to recover the column space of $A$ within an error of $O(d)$ (in Frobenius norm) under certain conditions on the probability distribution of $\mathbf{b}$. The second problem we consider is that of robust recovery of the signal in the presence of outliers, i.e., large but sparse noise. In this setting we are interested in recovering the latent vector $\mathbf{c}$ from its noisy nonlinear sketches of the form $\mathbf{v} = \mathrm{ReLU}(A\mathbf{c}) + \mathbf{e}+\mathbf{w}$, where $\mathbf{e} \in \mathbb{R}^d$ denotes the outliers with sparsity $s$ and $\mathbf{w} \in \mathbb{R}^d$ denote the dense but small noise. This line of work has recently been studied (Soltanolkotabi, 2017) without the presence of outliers. For this problem, we show that a generalized LASSO algorithm is able to recover the signal $\mathbf{c} \in \mathbb{R}^k$ within an $\ell_2$ error of $O(\sqrt{\frac{(k+s)\log d}{d}})$ when $A$ is a random Gaussian matrix.
The Geometric Block Model
Jan 24, 2018
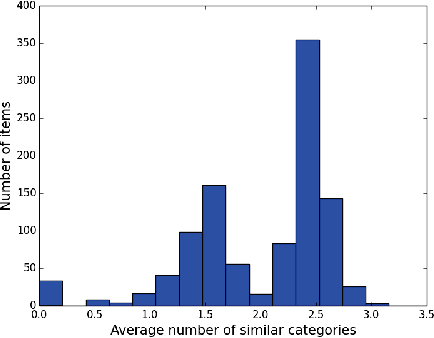

To capture the inherent geometric features of many community detection problems, we propose to use a new random graph model of communities that we call a Geometric Block Model. The geometric block model generalizes the random geometric graphs in the same way that the well-studied stochastic block model generalizes the Erdos-Renyi random graphs. It is also a natural extension of random community models inspired by the recent theoretical and practical advancement in community detection. While being a topic of fundamental theoretical interest, our main contribution is to show that many practical community structures are better explained by the geometric block model. We also show that a simple triangle-counting algorithm to detect communities in the geometric block model is near-optimal. Indeed, even in the regime where the average degree of the graph grows only logarithmically with the number of vertices (sparse-graph), we show that this algorithm performs extremely well, both theoretically and practically. In contrast, the triangle-counting algorithm is far from being optimum for the stochastic block model. We simulate our results on both real and synthetic datasets to show superior performance of both the new model as well as our algorithm.
Query Complexity of Clustering with Side Information
Jun 23, 2017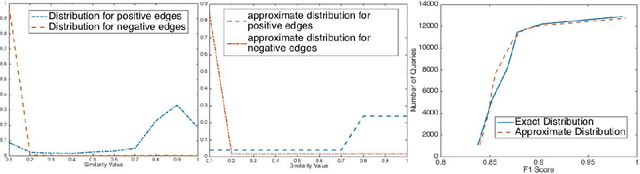
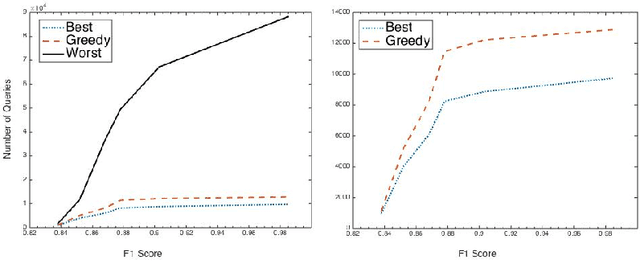
Suppose, we are given a set of $n$ elements to be clustered into $k$ (unknown) clusters, and an oracle/expert labeler that can interactively answer pair-wise queries of the form, "do two elements $u$ and $v$ belong to the same cluster?". The goal is to recover the optimum clustering by asking the minimum number of queries. In this paper, we initiate a rigorous theoretical study of this basic problem of query complexity of interactive clustering, and provide strong information theoretic lower bounds, as well as nearly matching upper bounds. Most clustering problems come with a similarity matrix, which is used by an automated process to cluster similar points together. Our main contribution in this paper is to show the dramatic power of side information aka similarity matrix on reducing the query complexity of clustering. A similarity matrix represents noisy pair-wise relationships such as one computed by some function on attributes of the elements. A natural noisy model is where similarity values are drawn independently from some arbitrary probability distribution $f_+$ when the underlying pair of elements belong to the same cluster, and from some $f_-$ otherwise. We show that given such a similarity matrix, the query complexity reduces drastically from $\Theta(nk)$ (no similarity matrix) to $O(\frac{k^2\log{n}}{\cH^2(f_+\|f_-)})$ where $\cH^2$ denotes the squared Hellinger divergence. Moreover, this is also information-theoretic optimal within an $O(\log{n})$ factor. Our algorithms are all efficient, and parameter free, i.e., they work without any knowledge of $k, f_+$ and $f_-$, and only depend logarithmically with $n$. Along the way, our work also reveals intriguing connection to popular community detection models such as the {\em stochastic block model}, significantly generalizes them, and opens up many venues for interesting future research.
Clustering with Noisy Queries
Jun 22, 2017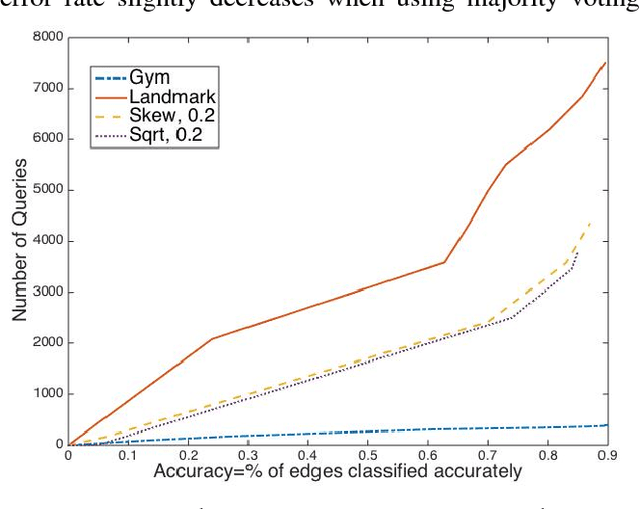
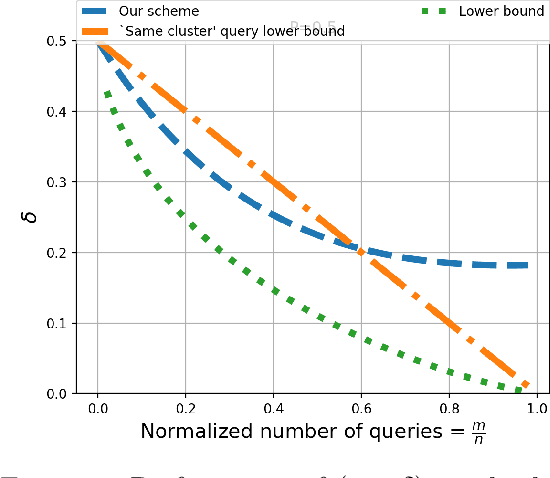
In this paper, we initiate a rigorous theoretical study of clustering with noisy queries (or a faulty oracle). Given a set of $n$ elements, our goal is to recover the true clustering by asking minimum number of pairwise queries to an oracle. Oracle can answer queries of the form : "do elements $u$ and $v$ belong to the same cluster?" -- the queries can be asked interactively (adaptive queries), or non-adaptively up-front, but its answer can be erroneous with probability $p$. In this paper, we provide the first information theoretic lower bound on the number of queries for clustering with noisy oracle in both situations. We design novel algorithms that closely match this query complexity lower bound, even when the number of clusters is unknown. Moreover, we design computationally efficient algorithms both for the adaptive and non-adaptive settings. The problem captures/generalizes multiple application scenarios. It is directly motivated by the growing body of work that use crowdsourcing for {\em entity resolution}, a fundamental and challenging data mining task aimed to identify all records in a database referring to the same entity. Here crowd represents the noisy oracle, and the number of queries directly relates to the cost of crowdsourcing. Another application comes from the problem of {\em sign edge prediction} in social network, where social interactions can be both positive and negative, and one must identify the sign of all pair-wise interactions by querying a few pairs. Furthermore, clustering with noisy oracle is intimately connected to correlation clustering, leading to improvement therein. Finally, it introduces a new direction of study in the popular {\em stochastic block model} where one has an incomplete stochastic block model matrix to recover the clusters.
Low rank approximation and decomposition of large matrices using error correcting codes
Jun 15, 2017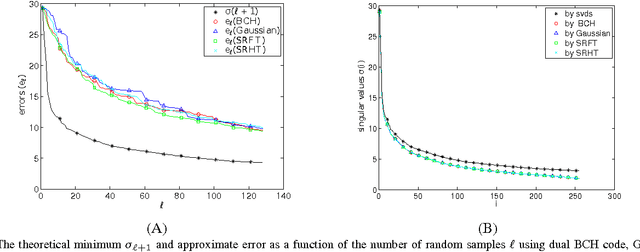
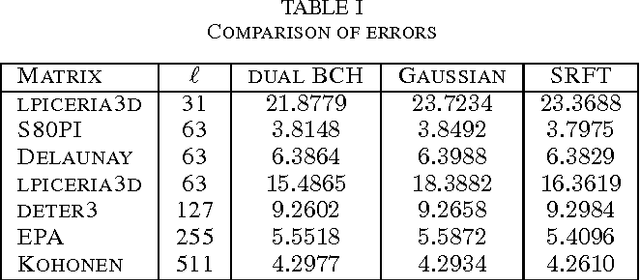
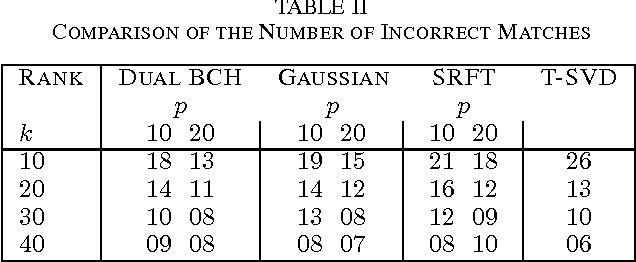
Low rank approximation is an important tool used in many applications of signal processing and machine learning. Recently, randomized sketching algorithms were proposed to effectively construct low rank approximations and obtain approximate singular value decompositions of large matrices. Similar ideas were used to solve least squares regression problems. In this paper, we show how matrices from error correcting codes can be used to find such low rank approximations and matrix decompositions, and extend the framework to linear least squares regression problems. The benefits of using these code matrices are the following: (i) They are easy to generate and they reduce randomness significantly. (ii) Code matrices with mild properties satisfy the subspace embedding property, and have a better chance of preserving the geometry of an entire subspace of vectors. (iii) For parallel and distributed applications, code matrices have significant advantages over structured random matrices and Gaussian random matrices. (iv) Unlike Fourier or Hadamard transform matrices, which require sampling $O(k\log k)$ columns for a rank-$k$ approximation, the log factor is not necessary for certain types of code matrices. That is, $(1+\epsilon)$ optimal Frobenius norm error can be achieved for a rank-$k$ approximation with $O(k/\epsilon)$ samples. (v) Fast multiplication is possible with structured code matrices, so fast approximations can be achieved for general dense input matrices. (vi) For least squares regression problem $\min\|Ax-b\|_2$ where $A\in \mathbb{R}^{n\times d}$, the $(1+\epsilon)$ relative error approximation can be achieved with $O(d/\epsilon)$ samples, with high probability, when certain code matrices are used.