 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSession-Aware Query Auto-completion using Extreme Multi-label Ranking
Dec 09, 2020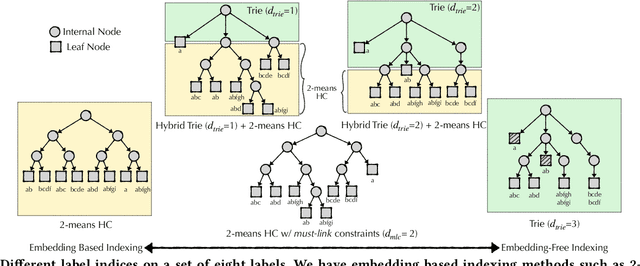
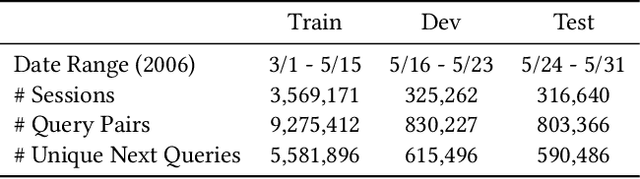
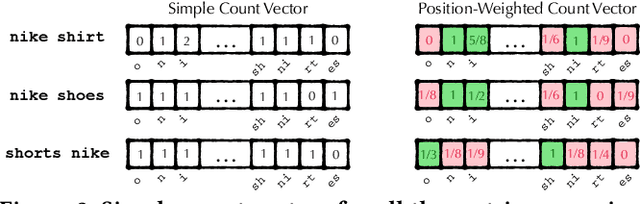
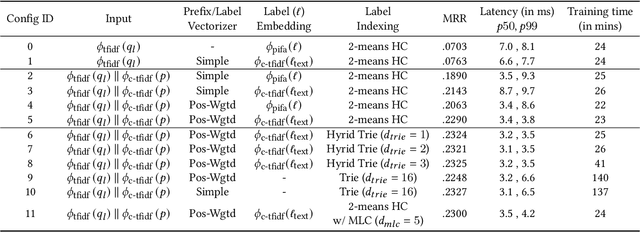
Query auto-completion is a fundamental feature in search engines where the task is to suggest plausible completions of a prefix typed in the search bar. Previous queries in the user session can provide useful context for the user's intent and can be leveraged to suggest auto-completions that are more relevant while adhering to the user's prefix. Such session-aware query auto-completions can be generated by sequence-to-sequence models; however, these generative approaches often do not meet the stringent latency requirements of responding to each user keystroke. Moreover, there is a danger of showing non-sensical queries in a generative approach. Another solution is to pre-compute a relatively small subset of relevant queries for common prefixes and rank them based on the context. However, such an approach would fail if no relevant queries for the current context are present in the pre-computed set. In this paper, we provide a solution to this problem: we take the novel approach of modeling session-aware query auto-completion as an eXtreme Multi-Label Ranking (XMR) problem where the input is the previous query in the session and the user's current prefix, while the output space is the set of millions of queries entered by users in the recent past. We adapt a popular XMR algorithm for this purpose by proposing several modifications to the key steps in the algorithm. The proposed modifications yield a 230% improvement in terms of Mean Reciprocal Rank over the baseline XMR approach on a public search logs dataset. Our approach meets the stringent latency requirements for auto-complete systems while leveraging session information in making suggestions. We show that session context leads to significant improvements in the quality of query auto-completions; in particular, for short prefixes with up to 3 characters, we see a 32% improvement over baselines that meet latency requirements.
Recovery of sparse linear classifiers from mixture of responses
Nov 07, 2020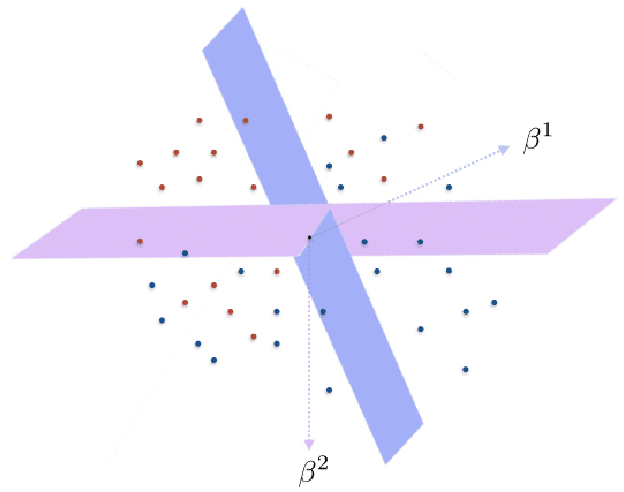
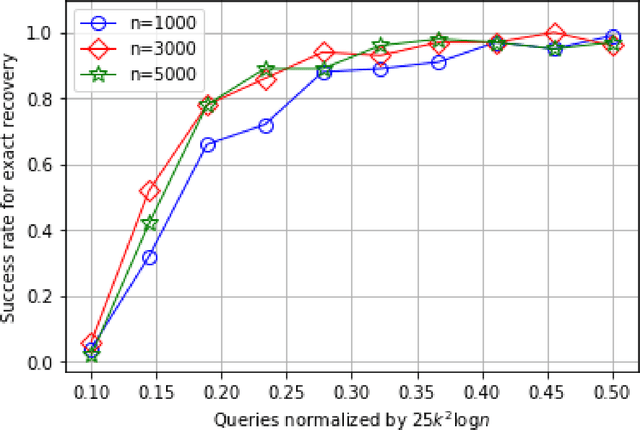
In the problem of learning a mixture of linear classifiers, the aim is to learn a collection of hyperplanes from a sequence of binary responses. Each response is a result of querying with a vector and indicates the side of a randomly chosen hyperplane from the collection the query vector belongs to. This model provides a rich representation of heterogeneous data with categorical labels and has only been studied in some special settings. We look at a hitherto unstudied problem of query complexity upper bound of recovering all the hyperplanes, especially for the case when the hyperplanes are sparse. This setting is a natural generalization of the extreme quantization problem known as 1-bit compressed sensing. Suppose we have a set of $\ell$ unknown $k$-sparse vectors. We can query the set with another vector $\boldsymbol{a}$, to obtain the sign of the inner product of $\boldsymbol{a}$ and a randomly chosen vector from the $\ell$-set. How many queries are sufficient to identify all the $\ell$ unknown vectors? This question is significantly more challenging than both the basic 1-bit compressed sensing problem (i.e., $\ell=1$ case) and the analogous regression problem (where the value instead of the sign is provided). We provide rigorous query complexity results (with efficient algorithms) for this problem.
Recovery of Sparse Signals from a Mixture of Linear Samples
Jul 14, 2020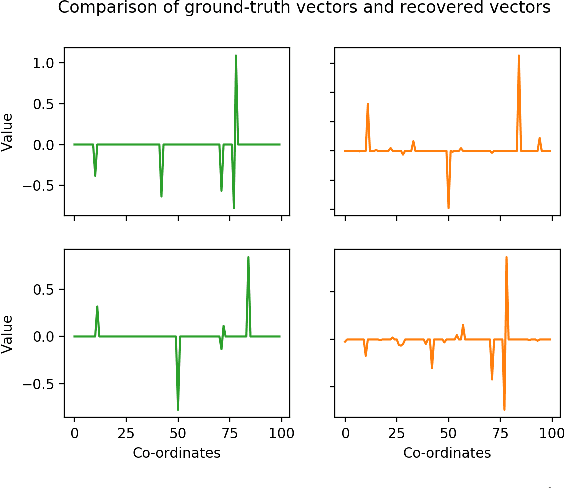
Mixture of linear regressions is a popular learning theoretic model that is used widely to represent heterogeneous data. In the simplest form, this model assumes that the labels are generated from either of two different linear models and mixed together. Recent works of Yin et al. and Krishnamurthy et al., 2019, focus on an experimental design setting of model recovery for this problem. It is assumed that the features can be designed and queried with to obtain their label. When queried, an oracle randomly selects one of the two different sparse linear models and generates a label accordingly. How many such oracle queries are needed to recover both of the models simultaneously? This question can also be thought of as a generalization of the well-known compressed sensing problem (Cand\`es and Tao, 2005, Donoho, 2006). In this work, we address this query complexity problem and provide efficient algorithms that improves on the previously best known results.
Multilabel Classification by Hierarchical Partitioning and Data-dependent Grouping
Jun 24, 2020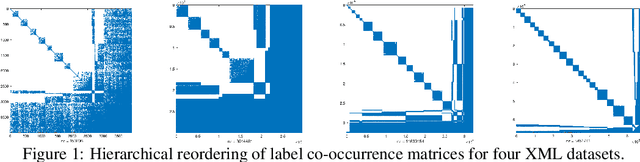
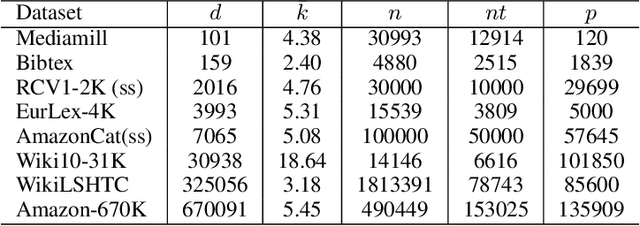
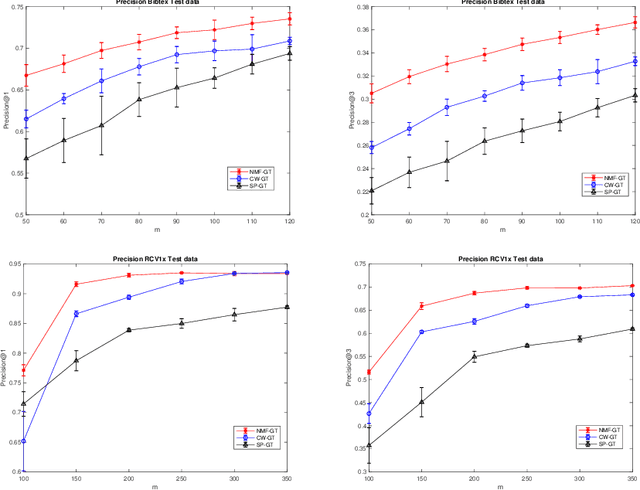
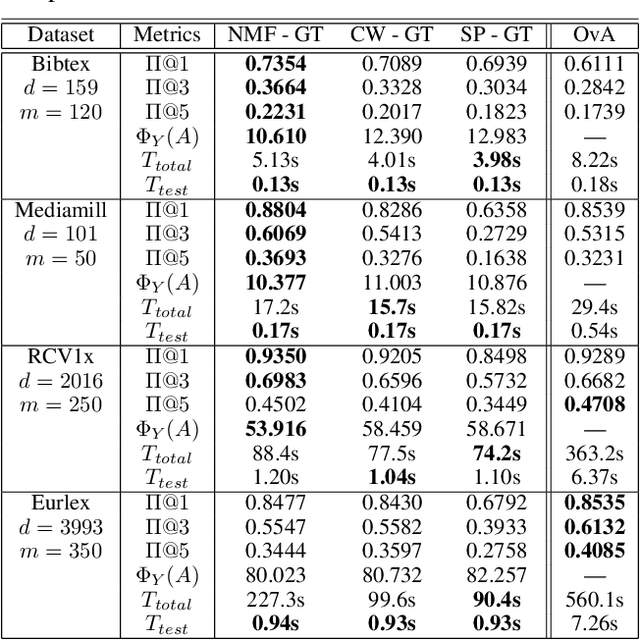
In modern multilabel classification problems, each data instance belongs to a small number of classes from a large set of classes. In other words, these problems involve learning very sparse binary label vectors. Moreover, in large-scale problems, the labels typically have certain (unknown) hierarchy. In this paper we exploit the sparsity of label vectors and the hierarchical structure to embed them in low-dimensional space using label groupings. Consequently, we solve the classification problem in a much lower dimensional space and then obtain labels in the original space using an appropriately defined lifting. Our method builds on the work of (Ubaru & Mazumdar, 2017), where the idea of group testing was also explored for multilabel classification. We first present a novel data-dependent grouping approach, where we use a group construction based on a low-rank Nonnegative Matrix Factorization (NMF) of the label matrix of training instances. The construction also allows us, using recent results, to develop a fast prediction algorithm that has a logarithmic runtime in the number of labels. We then present a hierarchical partitioning approach that exploits the label hierarchy in large scale problems to divide up the large label space and create smaller sub-problems, which can then be solved independently via the grouping approach. Numerical results on many benchmark datasets illustrate that, compared to other popular methods, our proposed methods achieve competitive accuracy with significantly lower computational costs.
Distributed Newton Can Communicate Less and Resist Byzantine Workers
Jun 15, 2020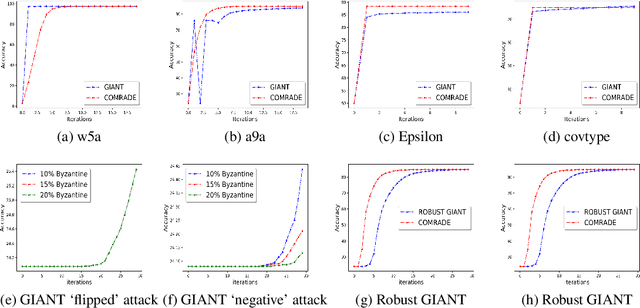
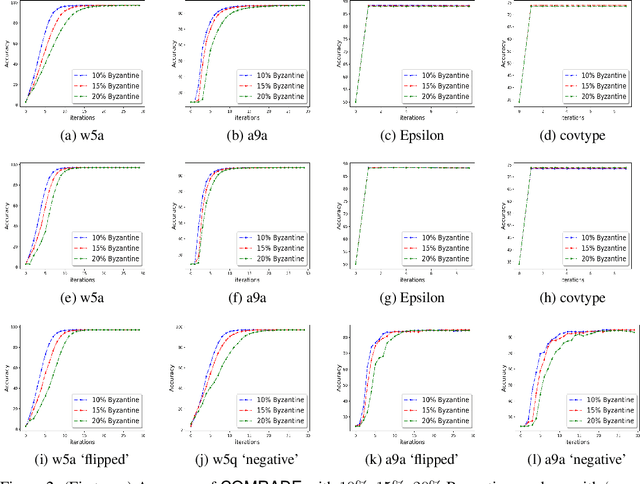
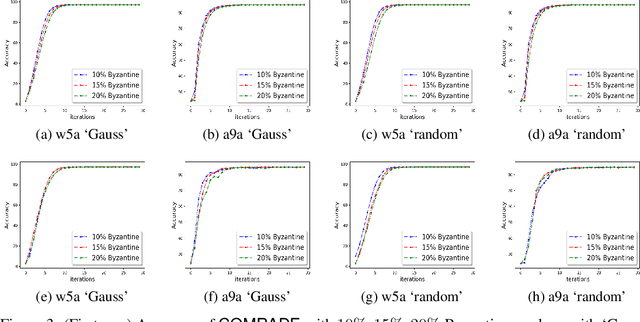
We develop a distributed second order optimization algorithm that is communication-efficient as well as robust against Byzantine failures of the worker machines. We propose COMRADE (COMunication-efficient and Robust Approximate Distributed nEwton), an iterative second order algorithm, where the worker machines communicate only once per iteration with the center machine. This is in sharp contrast with the state-of-the-art distributed second order algorithms like GIANT [34] and DINGO[7], where the worker machines send (functions of) local gradient and Hessian sequentially; thus ending up communicating twice with the center machine per iteration. Moreover, we show that the worker machines can further compress the local information before sending it to the center. In addition, we employ a simple norm based thresholding rule to filter-out the Byzantine worker machines. We establish the linear-quadratic rate of convergence of COMRADE and establish that the communication savings and Byzantine resilience result in only a small statistical error rate for arbitrary convex loss functions. To the best of our knowledge, this is the first work that addresses the issue of Byzantine resilience in second order distributed optimization. Furthermore, we validate our theoretical results with extensive experiments on synthetic and benchmark LIBSVM [5] data-sets and demonstrate convergence guarantees.
Reliable Distributed Clustering with Redundant Data Assignment
Feb 20, 2020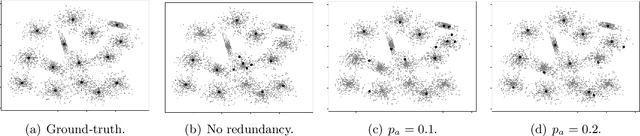
In this paper, we present distributed generalized clustering algorithms that can handle large scale data across multiple machines in spite of straggling or unreliable machines. We propose a novel data assignment scheme that enables us to obtain global information about the entire data even when some machines fail to respond with the results of the assigned local computations. The assignment scheme leads to distributed algorithms with good approximation guarantees for a variety of clustering and dimensionality reduction problems.
Algebraic and Analytic Approaches for Parameter Learning in Mixture Models
Jan 19, 2020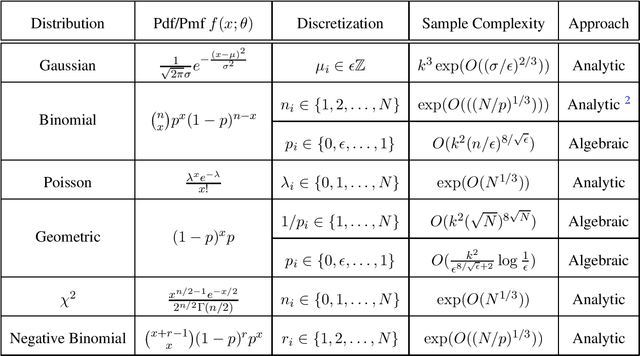
We present two different approaches for parameter learning in several mixture models in one dimension. Our first approach uses complex-analytic methods and applies to Gaussian mixtures with shared variance, binomial mixtures with shared success probability, and Poisson mixtures, among others. An example result is that $\exp(O(N^{1/3}))$ samples suffice to exactly learn a mixture of $k<N$ Poisson distributions, each with integral rate parameters bounded by $N$. Our second approach uses algebraic and combinatorial tools and applies to binomial mixtures with shared trial parameter $N$ and differing success parameters, as well as to mixtures of geometric distributions. Again, as an example, for binomial mixtures with $k$ components and success parameters discretized to resolution $\epsilon$, $O(k^2(N/\epsilon)^{8/\sqrt{\epsilon}})$ samples suffice to exactly recover the parameters. For some of these distributions, our results represent the first guarantees for parameter estimation.
Communication-Efficient and Byzantine-Robust Distributed Learning
Nov 21, 2019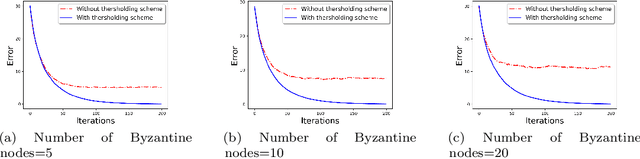
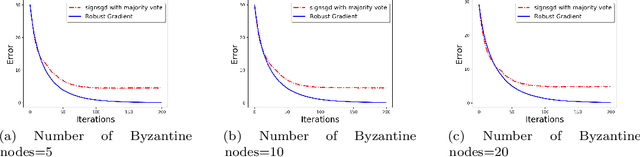
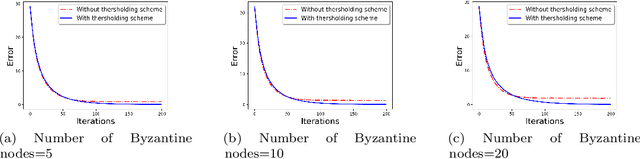
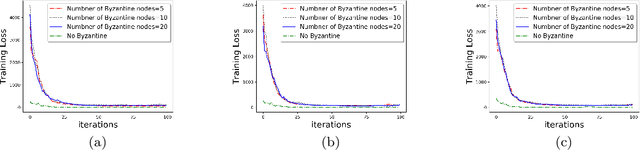
We develop a communication-efficient distributed learning algorithm that is robust against Byzantine worker machines. We propose and analyze a distributed gradient-descent algorithm that performs a simple thresholding based on gradient norms to mitigate Byzantine failures. We show the (statistical) error-rate of our algorithm matches that of [YCKB18], which uses more complicated schemes (like coordinate-wise median or trimmed mean) and thus optimal. Furthermore, for communication efficiency, we consider a generic class of {\delta}-approximate compressors from [KRSJ19] that encompasses sign-based compressors and top-k sparsification. Our algorithm uses compressed gradients and gradient norms for aggregation and Byzantine removal respectively. We establish the statistical error rate of the algorithm for arbitrary (convex or non-convex) smooth loss function. We show that, in the regime when the compression factor {\delta} is constant and the dimension of the parameter space is fixed, the rate of convergence is not affected by the compression operation, and hence we effectively get the compression for free. Moreover, we extend the compressed gradient descent algorithm with error feedback proposed in [KRSJ19] for the distributed setting. We have experimentally validated our results and shown good performance in convergence for convex (least-square regression) and non-convex (neural network training) problems.
vqSGD: Vector Quantized Stochastic Gradient Descent
Nov 18, 2019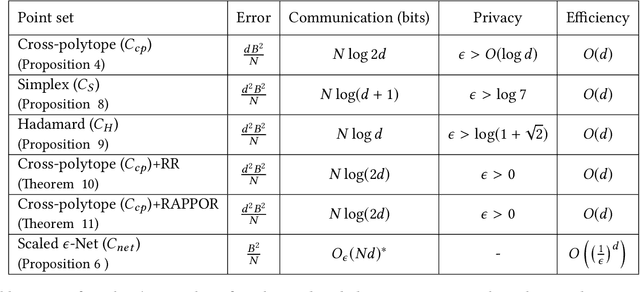
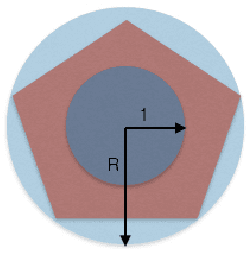

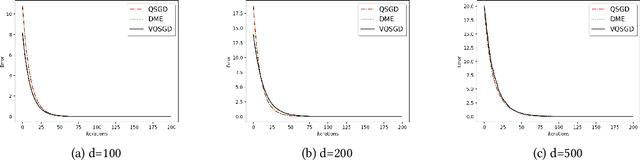
In this work, we present a family of vector quantization schemes vqSGD (Vector-Quantized Stochastic Gradient Descent) that provide asymptotic reduction in the communication cost with convergence guarantees in distributed computation and learning settings. In particular, we consider a randomized scheme, based on convex hull of a point set, that returns an unbiased estimator of a d-dimensional gradient vector with bounded variance. We provide multiple efficient instances of our scheme that require only O(logd) bits of communication. Further, we show that vqSGD also provides strong privacy guarantees. Experimentally, we show vqSGD performs equally well compared to other state-of-the-art quantization schemes, while substantially reducing the communication cost.
Sample Complexity of Learning Mixtures of Sparse Linear Regressions
Oct 30, 2019In the problem of learning mixtures of linear regressions, the goal is to learn a collection of signal vectors from a sequence of (possibly noisy) linear measurements, where each measurement is evaluated on an unknown signal drawn uniformly from this collection. This setting is quite expressive and has been studied both in terms of practical applications and for the sake of establishing theoretical guarantees. In this paper, we consider the case where the signal vectors are sparse; this generalizes the popular compressed sensing paradigm. We improve upon the state-of-the-art results as follows: In the noisy case, we resolve an open question of Yin et al. (IEEE Transactions on Information Theory, 2019) by showing how to handle collections of more than two vectors and present the first robust reconstruction algorithm, i.e., if the signals are not perfectly sparse, we still learn a good sparse approximation of the signals. In the noiseless case, as well as in the noisy case, we show how to circumvent the need for a restrictive assumption required in the previous work. Our techniques are quite different from those in the previous work: for the noiseless case, we rely on a property of sparse polynomials and for the noisy case, we provide new connections to learning Gaussian mixtures and use ideas from the theory of error-correcting codes.