 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-RAG: Long Context Multi-step Retrieval via Value-based Embedder Training
Nov 10, 2025Retrieval-Augmented Generation (RAG) methods enhance LLM performance by efficiently filtering relevant context for LLMs, reducing hallucinations and inference cost. However, most existing RAG methods focus on single-step retrieval, which is often insufficient for answering complex questions that require multi-step search. Recently, multi-step retrieval approaches have emerged, typically involving the fine-tuning of small LLMs to perform multi-step retrieval. This type of fine-tuning is highly resource-intensive and does not enable the use of larger LLMs. In this work, we propose Q-RAG, a novel approach that fine-tunes the Embedder model for multi-step retrieval using reinforcement learning (RL). Q-RAG offers a competitive, resource-efficient alternative to existing multi-step retrieval methods for open-domain question answering and achieves state-of-the-art results on the popular long-context benchmarks Babilong and RULER for contexts up to 10M tokens.
AriGraph: Learning Knowledge Graph World Models with Episodic Memory for LLM Agents
Jul 05, 2024



Advancements in generative AI have broadened the potential applications of Large Language Models (LLMs) in the development of autonomous agents. Achieving true autonomy requires accumulating and updating knowledge gained from interactions with the environment and effectively utilizing it. Current LLM-based approaches leverage past experiences using a full history of observations, summarization or retrieval augmentation. However, these unstructured memory representations do not facilitate the reasoning and planning essential for complex decision-making. In our study, we introduce AriGraph, a novel method wherein the agent constructs a memory graph that integrates semantic and episodic memories while exploring the environment. This graph structure facilitates efficient associative retrieval of interconnected concepts, relevant to the agent's current state and goals, thus serving as an effective environmental model that enhances the agent's exploratory and planning capabilities. We demonstrate that our Ariadne LLM agent, equipped with this proposed memory architecture augmented with planning and decision-making, effectively handles complex tasks on a zero-shot basis in the TextWorld environment. Our approach markedly outperforms established methods such as full-history, summarization, and Retrieval-Augmented Generation in various tasks, including the cooking challenge from the First TextWorld Problems competition and novel tasks like house cleaning and puzzle Treasure Hunting.
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Jun 14, 2024



In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20\% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60\% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
In Search of Needles in a 11M Haystack: Recurrent Memory Finds What LLMs Miss
Feb 21, 2024



This paper addresses the challenge of processing long documents using generative transformer models. To evaluate different approaches, we introduce BABILong, a new benchmark designed to assess model capabilities in extracting and processing distributed facts within extensive texts. Our evaluation, which includes benchmarks for GPT-4 and RAG, reveals that common methods are effective only for sequences up to $10^4$ elements. In contrast, fine-tuning GPT-2 with recurrent memory augmentations enables it to handle tasks involving up to $11\times 10^6$ elements. This achievement marks a substantial leap, as it is by far the longest input processed by any neural network model to date, demonstrating a significant improvement in the processing capabilities for long sequences.
Explain My Surprise: Learning Efficient Long-Term Memory by Predicting Uncertain Outcomes
Jul 27, 2022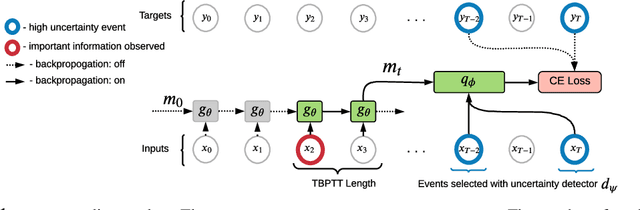
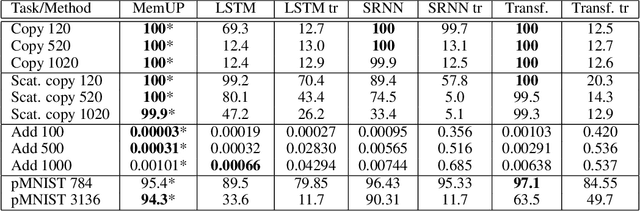
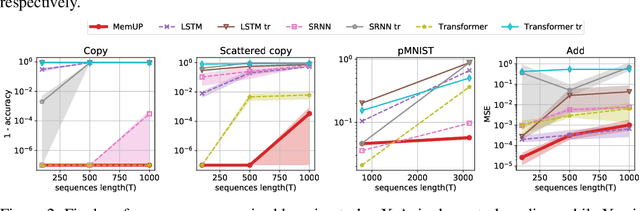
In many sequential tasks, a model needs to remember relevant events from the distant past to make correct predictions. Unfortunately, a straightforward application of gradient based training requires intermediate computations to be stored for every element of a sequence. This requires prohibitively large computing memory if a sequence consists of thousands or even millions elements, and as a result, makes learning of very long-term dependencies infeasible. However, the majority of sequence elements can usually be predicted by taking into account only temporally local information. On the other hand, predictions affected by long-term dependencies are sparse and characterized by high uncertainty given only local information. We propose MemUP, a new training method that allows to learn long-term dependencies without backpropagating gradients through the whole sequence at a time. This method can be potentially applied to any gradient based sequence learning. MemUP implementation for recurrent architectures shows performances better or comparable to baselines while requiring significantly less computing memory.