 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired-Sampling Contrastive Framework for Joint Physical-Digital Face Attack Detection
Aug 20, 2025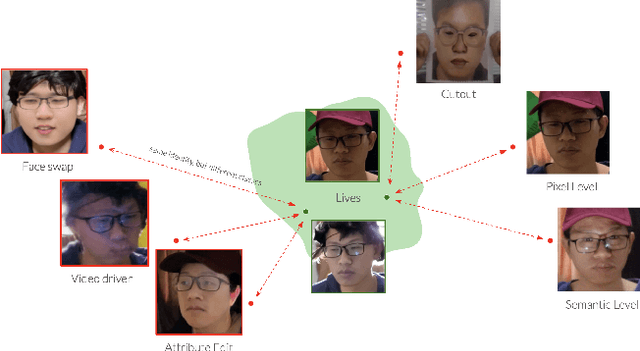
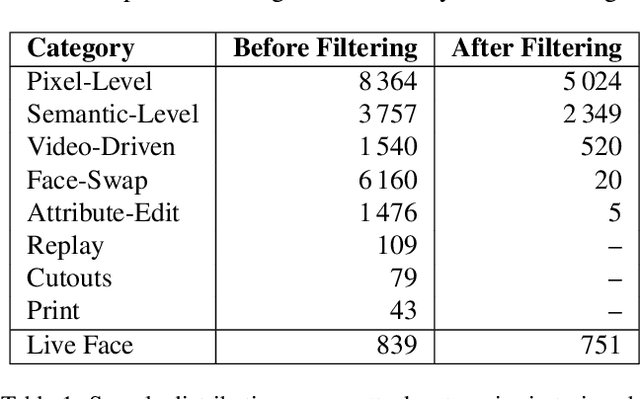

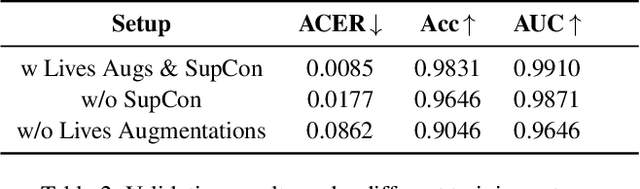
Modern face recognition systems remain vulnerable to spoofing attempts, including both physical presentation attacks and digital forgeries. Traditionally, these two attack vectors have been handled by separate models, each targeting its own artifacts and modalities. However, maintaining distinct detectors increases system complexity and inference latency and leaves systems exposed to combined attack vectors. We propose the Paired-Sampling Contrastive Framework, a unified training approach that leverages automatically matched pairs of genuine and attack selfies to learn modality-agnostic liveness cues. Evaluated on the 6th Face Anti-Spoofing Challenge Unified Physical-Digital Attack Detection benchmark, our method achieves an average classification error rate (ACER) of 2.10 percent, outperforming prior solutions. The framework is lightweight (4.46 GFLOPs) and trains in under one hour, making it practical for real-world deployment. Code and pretrained models are available at https://github.com/xPONYx/iccv2025_deepfake_challenge.
Evaluating AI cyber capabilities with crowdsourced elicitation
May 26, 2025As AI systems become increasingly capable, understanding their offensive cyber potential is critical for informed governance and responsible deployment. However, it's hard to accurately bound their capabilities, and some prior evaluations dramatically underestimated them. The art of extracting maximum task-specific performance from AIs is called "AI elicitation", and today's safety organizations typically conduct it in-house. In this paper, we explore crowdsourcing elicitation efforts as an alternative to in-house elicitation work. We host open-access AI tracks at two Capture The Flag (CTF) competitions: AI vs. Humans (400 teams) and Cyber Apocalypse_ (4000 teams). The AI teams achieve outstanding performance at both events, ranking top-13% and top-21% respectively for a total of \$7500 in bounties. This impressive performance suggests that open-market elicitation may offer an effective complement to in-house elicitation. We propose elicitation bounties as a practical mechanism for maintaining timely, cost-effective situational awareness of emerging AI capabilities. Another advantage of open elicitations is the option to collect human performance data at scale. Applying METR's methodology, we found that AI agents can reliably solve cyber challenges requiring one hour or less of effort from a median human CTF participant.
Hacking CTFs with Plain Agents
Dec 03, 2024



We saturate a high-school-level hacking benchmark with plain LLM agent design. Concretely, we obtain 95% performance on InterCode-CTF, a popular offensive security benchmark, using prompting, tool use, and multiple attempts. This beats prior work by Phuong et al. 2024 (29%) and Abramovich et al. 2024 (72%). Our results suggest that current LLMs have surpassed the high school level in offensive cybersecurity. Their hacking capabilities remain underelicited: our ReAct&Plan prompting strategy solves many challenges in 1-2 turns without complex engineering or advanced harnessing.