 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired-Sampling Contrastive Framework for Joint Physical-Digital Face Attack Detection
Aug 20, 2025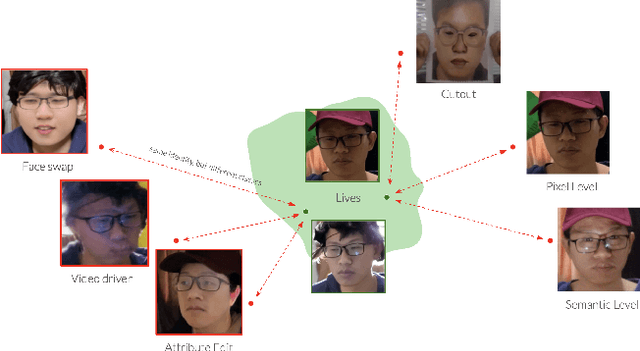
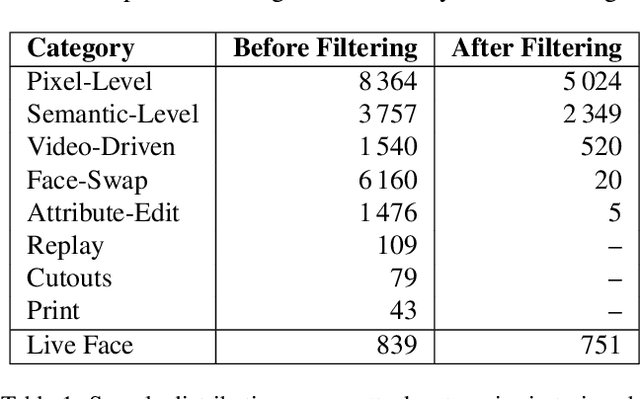

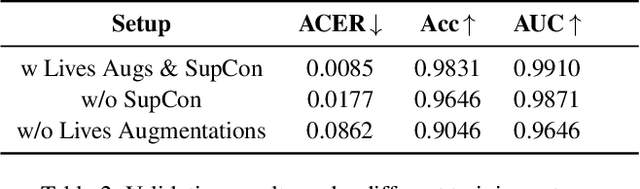
Modern face recognition systems remain vulnerable to spoofing attempts, including both physical presentation attacks and digital forgeries. Traditionally, these two attack vectors have been handled by separate models, each targeting its own artifacts and modalities. However, maintaining distinct detectors increases system complexity and inference latency and leaves systems exposed to combined attack vectors. We propose the Paired-Sampling Contrastive Framework, a unified training approach that leverages automatically matched pairs of genuine and attack selfies to learn modality-agnostic liveness cues. Evaluated on the 6th Face Anti-Spoofing Challenge Unified Physical-Digital Attack Detection benchmark, our method achieves an average classification error rate (ACER) of 2.10 percent, outperforming prior solutions. The framework is lightweight (4.46 GFLOPs) and trains in under one hour, making it practical for real-world deployment. Code and pretrained models are available at https://github.com/xPONYx/iccv2025_deepfake_challenge.
Barriers towards no-reference metrics application to compressed video quality analysis: on the example of no-reference metric NIQE
Aug 29, 2019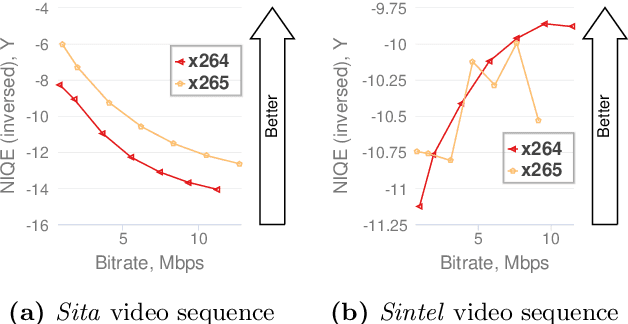
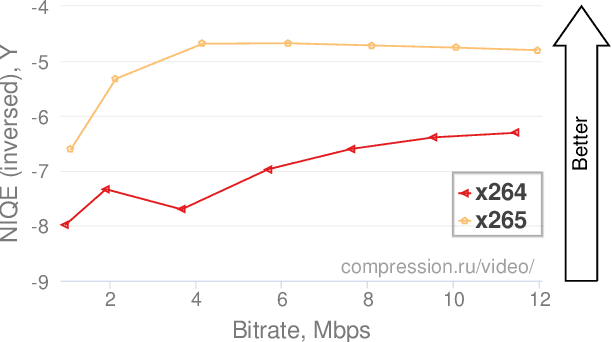

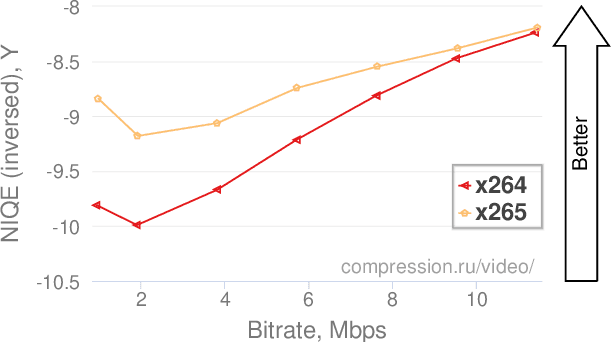
This paper analyses the application of no-reference metric NIQE to the task of video-codec comparison. A number of issues in the metric behaviour on videos was detected and described. The metric has outlying scores on black and solid-coloured frames. The proposed averaging technique for metric quality scores helped to improve the results in some cases. Also, NIQE has low-quality scores for videos with detailed textures and higher scores for videos of lower bitrates due to the blurring of these textures after compression. Although NIQE showed natural results for many tested videos, it is not universal and currently can not be used for video-codec comparisons.