 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning in Low-rank Orthogonal Subspaces
Oct 22, 2020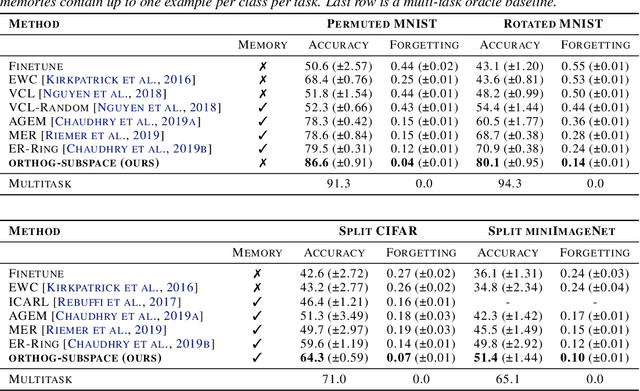

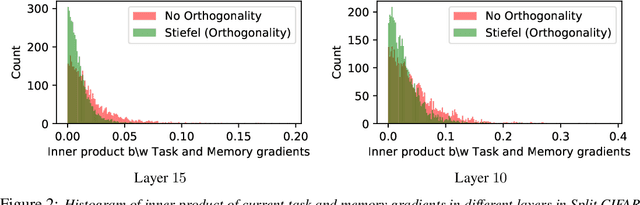
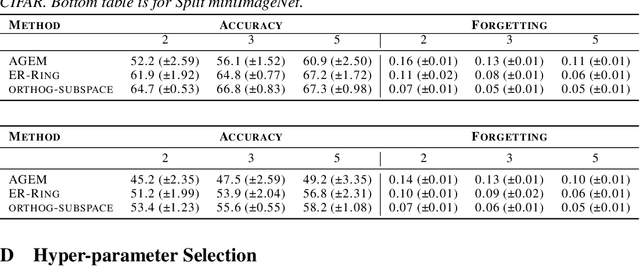
In continual learning (CL), a learner is faced with a sequence of tasks, arriving one after the other, and the goal is to remember all the tasks once the continual learning experience is finished. The prior art in CL uses episodic memory, parameter regularization or extensible network structures to reduce interference among tasks, but in the end, all the approaches learn different tasks in a joint vector space. We believe this invariably leads to interference among different tasks. We propose to learn tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Further, to keep the gradients of different tasks coming from these subspaces orthogonal to each other, we learn isometric mappings by posing network training as an optimization problem over the Stiefel manifold. To the best of our understanding, we report, for the first time, strong results over experience-replay baseline with and without memory on standard classification benchmarks in continual learning. The code is made publicly available.
* The paper is accepted at NeurIPS'20
Using Hindsight to Anchor Past Knowledge in Continual Learning
Feb 19, 2020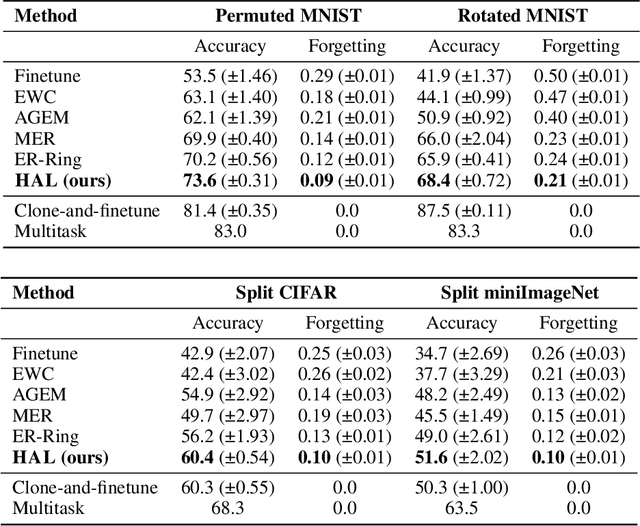
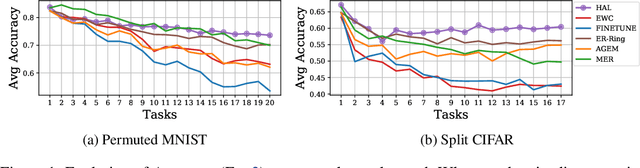
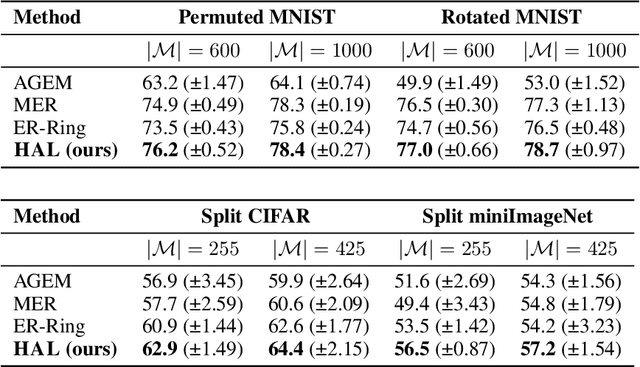
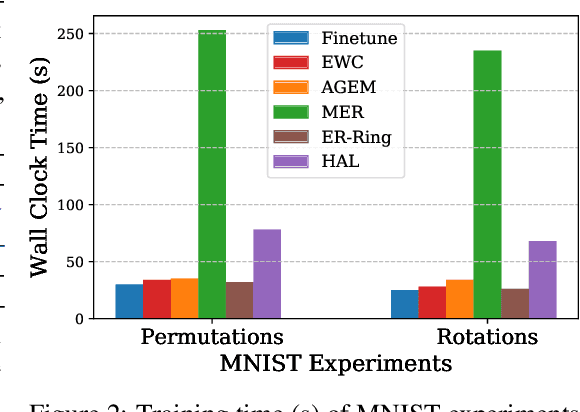
In continual learning, the learner faces a stream of data whose distribution changes over time. Modern neural networks are known to suffer under this setting, as they quickly forget previously acquired knowledge. To address such catastrophic forgetting, many continual learning methods implement different types of experience replay, re-learning on past data stored in a small buffer known as episodic memory. In this work, we complement experience replay with a new objective that we call anchoring, where the learner uses bilevel optimization to update its knowledge on the current task, while keeping intact the predictions on some anchor points of past tasks. These anchor points are learned using gradient-based optimization to maximize forgetting, which is approximated by fine-tuning the currently trained model on the episodic memory of past tasks. Experiments on several supervised learning benchmarks for continual learning demonstrate that our approach improves the standard experience replay in terms of both accuracy and forgetting metrics and for various sizes of episodic memories.
Continual Learning with Tiny Episodic Memories
Mar 20, 2019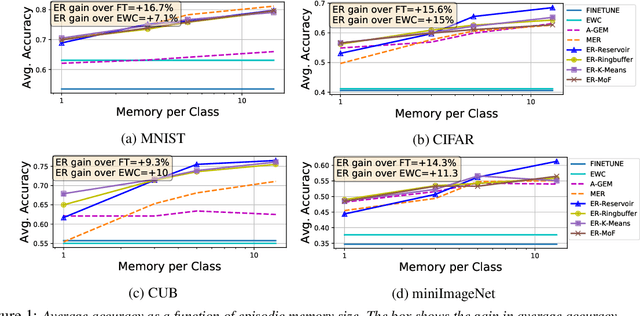
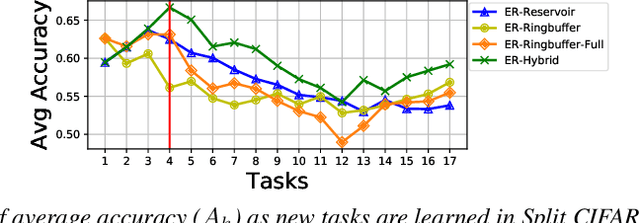

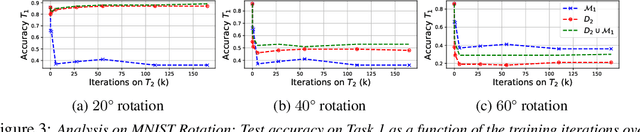
Learning with less supervision is a major challenge in artificial intelligence. One sensible approach to decrease the amount of supervision is to leverage prior experience and transfer knowledge from tasks seen in the past. However, a necessary condition for a successful transfer is the ability to remember how to perform previous tasks. The Continual Learning (CL) setting, whereby an agent learns from a stream of tasks without seeing any example twice, is an ideal framework to investigate how to accrue such knowledge. In this work, we consider supervised learning tasks and methods that leverage a very small episodic memory for continual learning. Through an extensive empirical analysis across four benchmark datasets adapted to CL, we observe that a very simple baseline, which jointly trains on both examples from the current task as well as examples stored in the memory, outperforms state-of-the-art CL approaches with and without episodic memory. Surprisingly, repeated learning over tiny episodic memories does not harm generalization on past tasks, as joint training on data from subsequent tasks acts like a data dependent regularizer. We discuss and evaluate different approaches to write into the memory. Most notably, reservoir sampling works remarkably well across the board, except when the memory size is extremely small. In this case, writing strategies that guarantee an equal representation of all classes work better. Overall, these methods should be considered as a strong baseline candidate when benchmarking new CL approaches
Efficient Lifelong Learning with A-GEM
Jan 09, 2019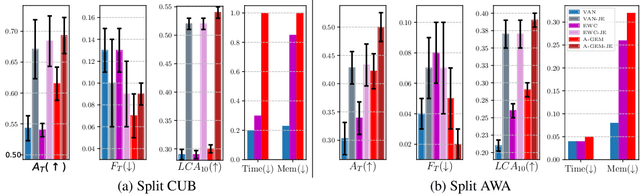
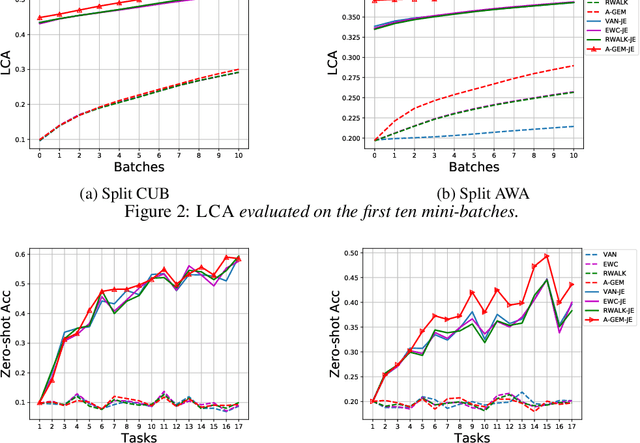
In lifelong learning, the learner is presented with a sequence of tasks, incrementally building a data-driven prior which may be leveraged to speed up learning of a new task. In this work, we investigate the efficiency of current lifelong approaches, in terms of sample complexity, computational and memory cost. Towards this end, we first introduce a new and a more realistic evaluation protocol, whereby learners observe each example only once and hyper-parameter selection is done on a small and disjoint set of tasks, which is not used for the actual learning experience and evaluation. Second, we introduce a new metric measuring how quickly a learner acquires a new skill. Third, we propose an improved version of GEM (Lopez-Paz & Ranzato, 2017), dubbed Averaged GEM (A-GEM), which enjoys the same or even better performance as GEM, while being almost as computationally and memory efficient as EWC (Kirkpatrick et al., 2016) and other regularization-based methods. Finally, we show that all algorithms including A-GEM can learn even more quickly if they are provided with task descriptors specifying the classification tasks under consideration. Our experiments on several standard lifelong learning benchmarks demonstrate that A-GEM has the best trade-off between accuracy and efficiency.
Riemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence
Aug 14, 2018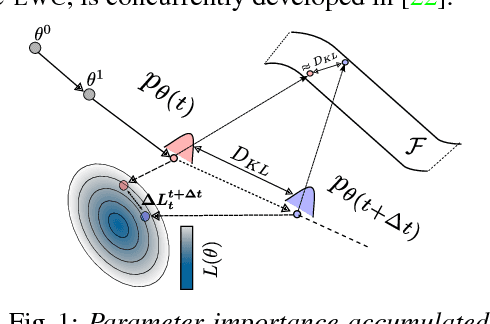
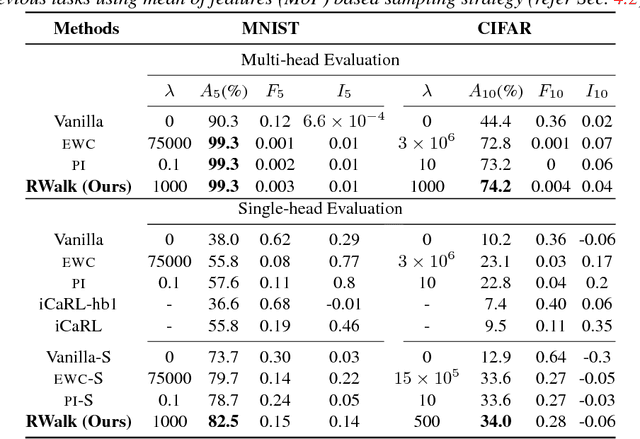
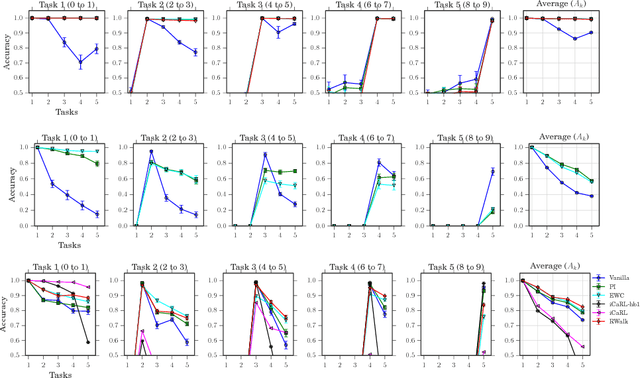
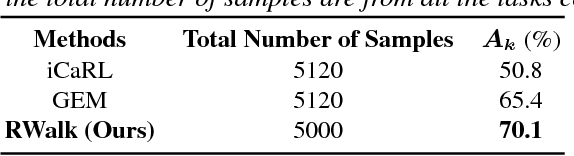
Incremental learning (IL) has received a lot of attention recently, however, the literature lacks a precise problem definition, proper evaluation settings, and metrics tailored specifically for the IL problem. One of the main objectives of this work is to fill these gaps so as to provide a common ground for better understanding of IL. The main challenge for an IL algorithm is to update the classifier whilst preserving existing knowledge. We observe that, in addition to forgetting, a known issue while preserving knowledge, IL also suffers from a problem we call intransigence, inability of a model to update its knowledge. We introduce two metrics to quantify forgetting and intransigence that allow us to understand, analyse, and gain better insights into the behaviour of IL algorithms. We present RWalk, a generalization of EWC++ (our efficient version of EWC [Kirkpatrick2016EWC]) and Path Integral [Zenke2017Continual] with a theoretically grounded KL-divergence based perspective. We provide a thorough analysis of various IL algorithms on MNIST and CIFAR-100 datasets. In these experiments, RWalk obtains superior results in terms of accuracy, and also provides a better trade-off between forgetting and intransigence.
Discovering Class-Specific Pixels for Weakly-Supervised Semantic Segmentation
Jul 18, 2017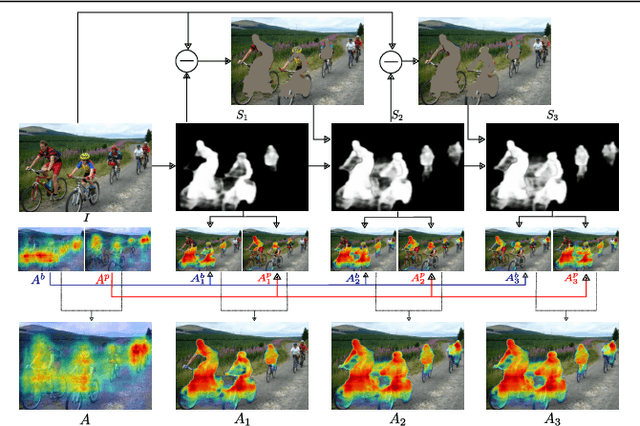
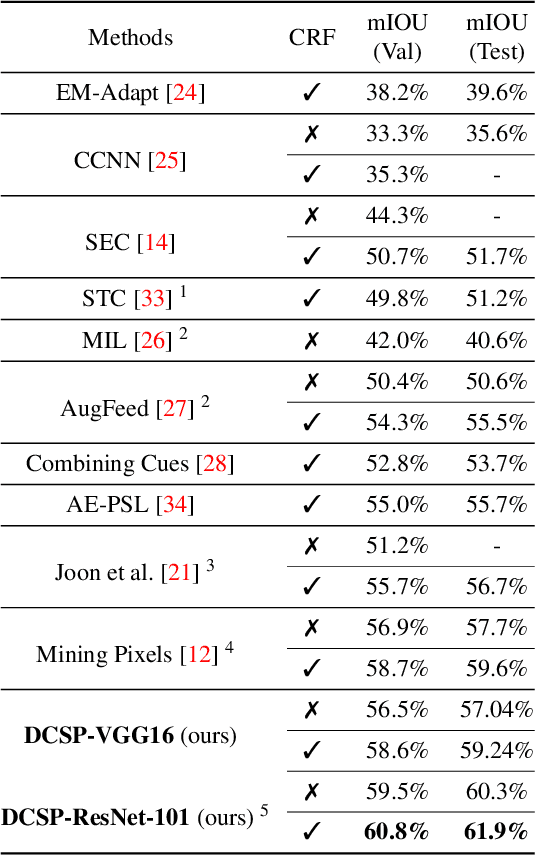
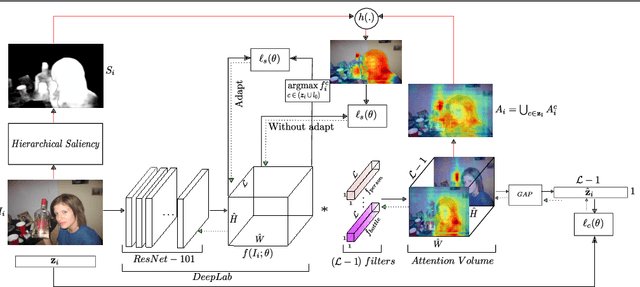

We propose an approach to discover class-specific pixels for the weakly-supervised semantic segmentation task. We show that properly combining saliency and attention maps allows us to obtain reliable cues capable of significantly boosting the performance. First, we propose a simple yet powerful hierarchical approach to discover the class-agnostic salient regions, obtained using a salient object detector, which otherwise would be ignored. Second, we use fully convolutional attention maps to reliably localize the class-specific regions in a given image. We combine these two cues to discover class-specific pixels which are then used as an approximate ground truth for training a CNN. While solving the weakly supervised semantic segmentation task, we ensure that the image-level classification task is also solved in order to enforce the CNN to assign at least one pixel to each object present in the image. Experimentally, on the PASCAL VOC12 val and test sets, we obtain the mIoU of 60.8% and 61.9%, achieving the performance gains of 5.1% and 5.2% compared to the published state-of-the-art results. The code is made publicly available.