 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking
Feb 15, 2022
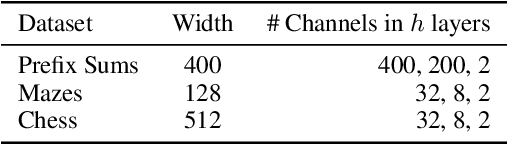


Machine learning systems perform well on pattern matching tasks, but their ability to perform algorithmic or logical reasoning is not well understood. One important reasoning capability is logical extrapolation, in which models trained only on small/simple reasoning problems can synthesize complex algorithms that scale up to large/complex problems at test time. Logical extrapolation can be achieved through recurrent systems, which can be iterated many times to solve difficult reasoning problems. We observe that this approach fails to scale to highly complex problems because behavior degenerates when many iterations are applied -- an issue we refer to as "overthinking." We propose a recall architecture that keeps an explicit copy of the problem instance in memory so that it cannot be forgotten. We also employ a progressive training routine that prevents the model from learning behaviors that are specific to iteration number and instead pushes it to learn behaviors that can be repeated indefinitely. These innovations prevent the overthinking problem, and enable recurrent systems to solve extremely hard logical extrapolation tasks, some requiring over 100K convolutional layers, without overthinking.
Datasets for Studying Generalization from Easy to Hard Examples
Aug 13, 2021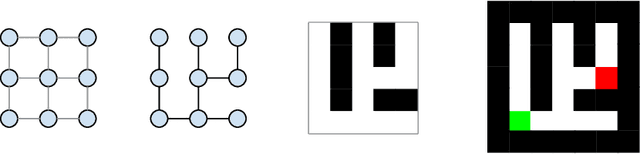
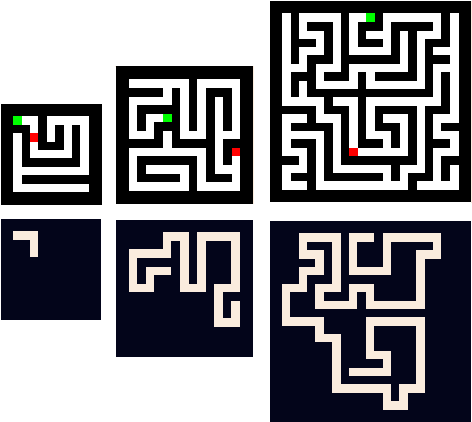
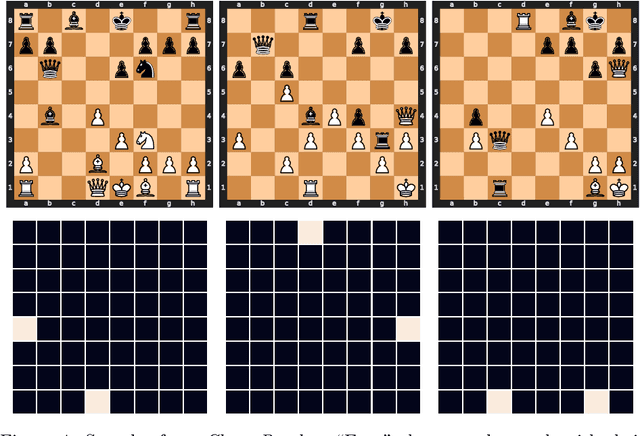
We describe new datasets for studying generalization from easy to hard examples.
MetaBalance: High-Performance Neural Networks for Class-Imbalanced Data
Jun 17, 2021
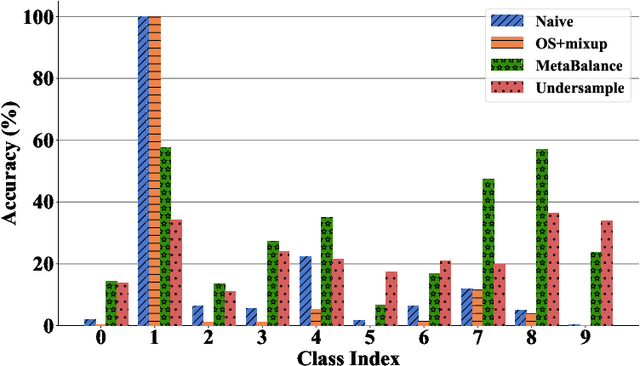
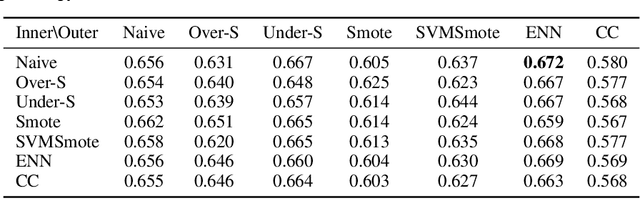
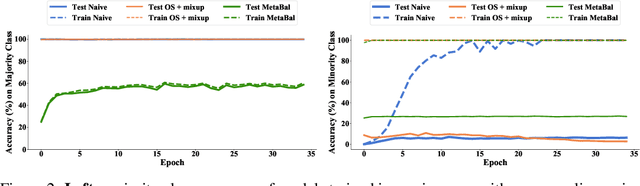
Class-imbalanced data, in which some classes contain far more samples than others, is ubiquitous in real-world applications. Standard techniques for handling class-imbalance usually work by training on a re-weighted loss or on re-balanced data. Unfortunately, training overparameterized neural networks on such objectives causes rapid memorization of minority class data. To avoid this trap, we harness meta-learning, which uses both an ''outer-loop'' and an ''inner-loop'' loss, each of which may be balanced using different strategies. We evaluate our method, MetaBalance, on image classification, credit-card fraud detection, loan default prediction, and facial recognition tasks with severely imbalanced data, and we find that MetaBalance outperforms a wide array of popular re-sampling strategies.
Preventing Unauthorized Use of Proprietary Data: Poisoning for Secure Dataset Release
Mar 05, 2021



Large organizations such as social media companies continually release data, for example user images. At the same time, these organizations leverage their massive corpora of released data to train proprietary models that give them an edge over their competitors. These two behaviors can be in conflict as an organization wants to prevent competitors from using their own data to replicate the performance of their proprietary models. We solve this problem by developing a data poisoning method by which publicly released data can be minimally modified to prevent others from train-ing models on it. Moreover, our method can be used in an online fashion so that companies can protect their data in real time as they release it.We demonstrate the success of our approach onImageNet classification and on facial recognition.
PAG-Net: Progressive Attention Guided Depth Super-resolution Network
Nov 22, 2019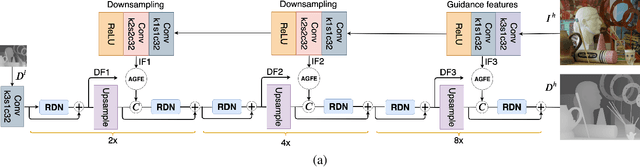
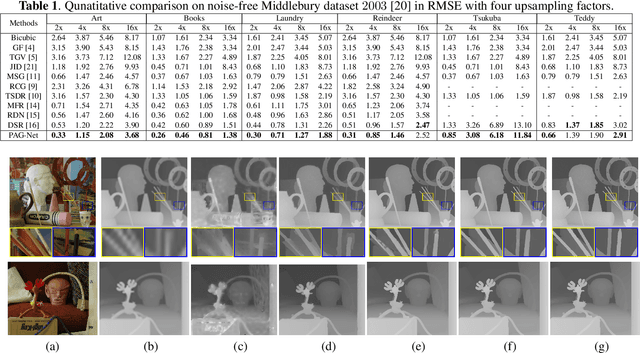
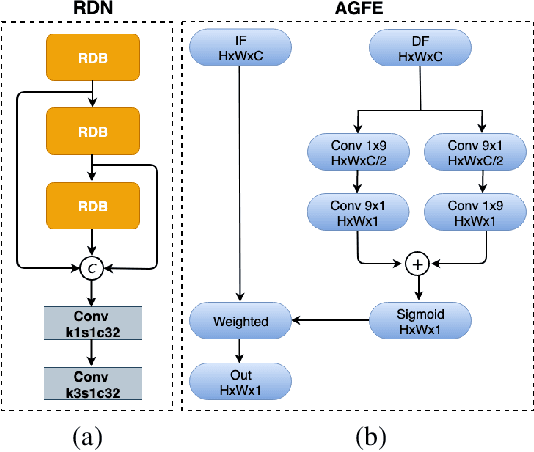

In this paper, we propose a novel method for the challenging problem of guided depth map super-resolution, called PAGNet. It is based on residual dense networks and involves the attention mechanism to suppress the texture copying problem arises due to improper guidance by RGB images. The attention module mainly involves providing the spatial attention to guidance image based on the depth features. We evaluate the proposed trained models on test dataset and provide comparisons with the state-of-the-art depth super-resolution methods.