 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Density Estimation-Based Markov Models with Hidden State
Jul 30, 2018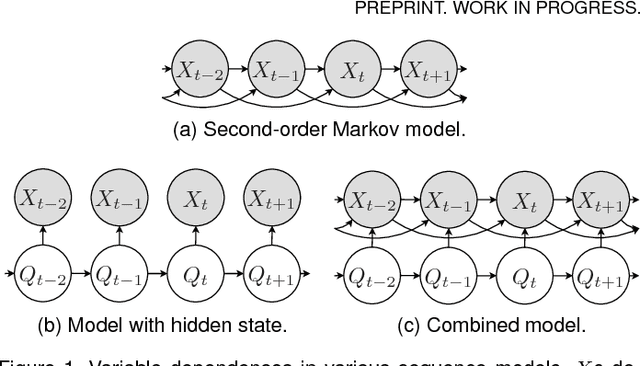
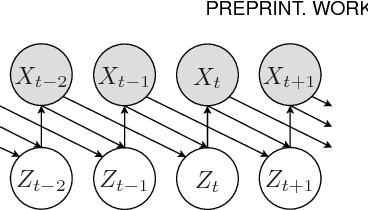
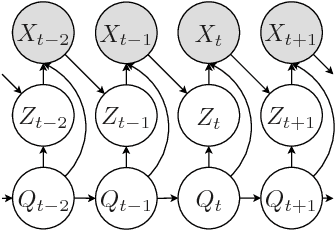
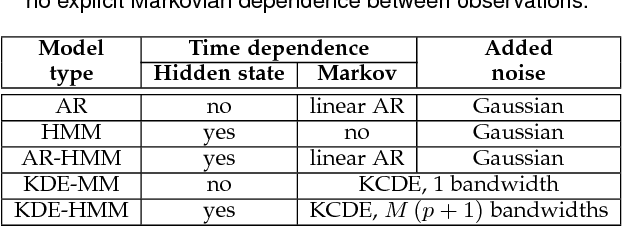
We consider Markov models of stochastic processes where the next-step conditional distribution is defined by a kernel density estimator (KDE), similar to Markov forecast densities and certain time-series bootstrap schemes. The KDE Markov models (KDE-MMs) we discuss are nonlinear, nonparametric, fully probabilistic representations of stationary processes, based on techniques with strong asymptotic consistency properties. The models generate new data by concatenating points from the training data sequences in a context-sensitive manner, together with some additive driving noise. We present novel EM-type maximum-likelihood algorithms for data-driven bandwidth selection in KDE-MMs. Additionally, we augment the KDE-MMs with a hidden state, yielding a new model class, KDE-HMMs. The added state variable captures non-Markovian long memory and signal structure (e.g., slow oscillations), complementing the short-range dependences described by the Markov process. The resulting joint Markov and hidden-Markov structure is appealing for modelling complex real-world processes such as speech signals. We present guaranteed-ascent EM-update equations for model parameters in the case of Gaussian kernels, as well as relaxed update formulas that greatly accelerate training in practice. Experiments demonstrate increased held-out set probability for KDE-HMMs on several challenging natural and synthetic data series, compared to traditional techniques such as autoregressive models, HMMs, and their combinations.
Nonnegative HMM for Babble Noise Derived from Speech HMM: Application to Speech Enhancement
Sep 16, 2017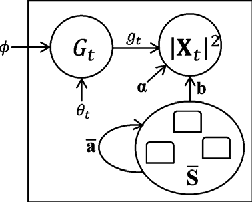
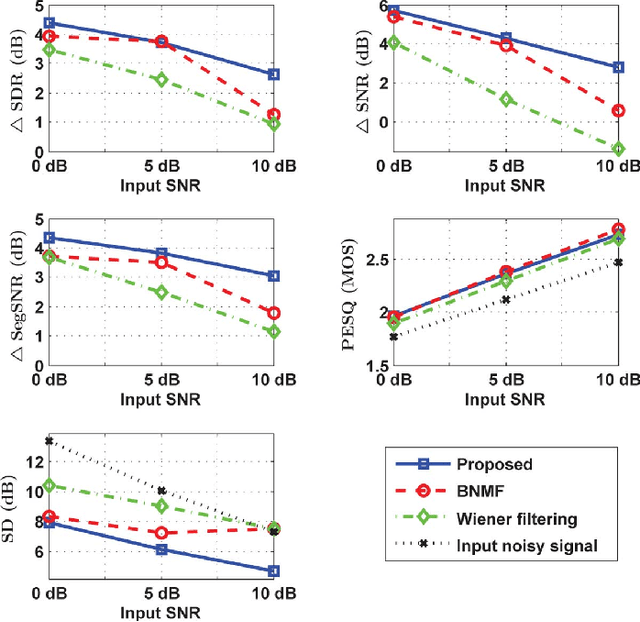
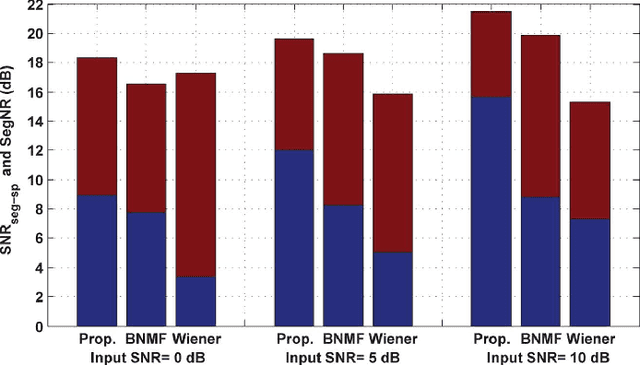
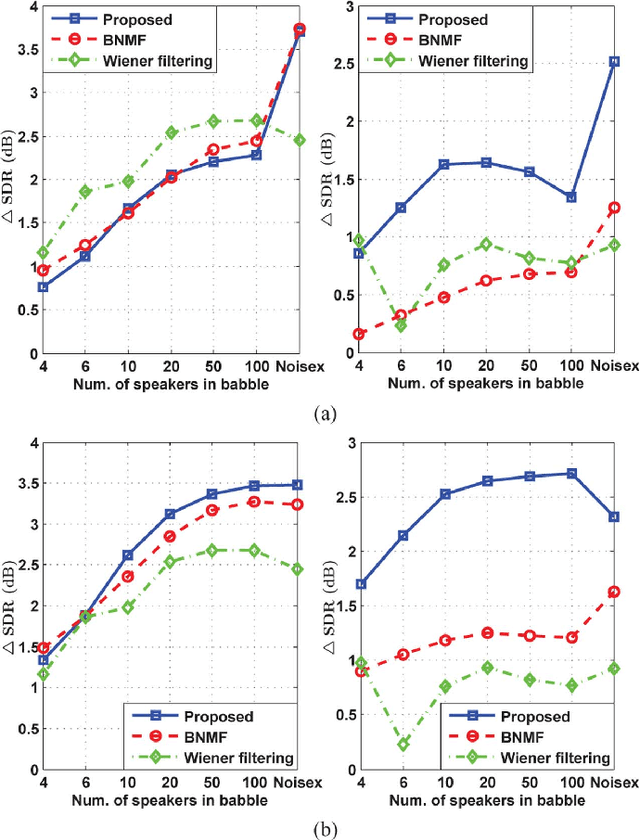
Deriving a good model for multitalker babble noise can facilitate different speech processing algorithms, e.g. noise reduction, to reduce the so-called cocktail party difficulty. In the available systems, the fact that the babble waveform is generated as a sum of N different speech waveforms is not exploited explicitly. In this paper, first we develop a gamma hidden Markov model for power spectra of the speech signal, and then formulate it as a sparse nonnegative matrix factorization (NMF). Second, the sparse NMF is extended by relaxing the sparsity constraint, and a novel model for babble noise (gamma nonnegative HMM) is proposed in which the babble basis matrix is the same as the speech basis matrix, and only the activation factors (weights) of the basis vectors are different for the two signals over time. Finally, a noise reduction algorithm is proposed using the derived speech and babble models. All of the stationary model parameters are estimated using the expectation-maximization (EM) algorithm, whereas the time-varying parameters, i.e. the gain parameters of speech and babble signals, are estimated using a recursive EM algorithm. The objective and subjective listening evaluations show that the proposed babble model and the final noise reduction algorithm significantly outperform the conventional methods.
Supervised and Unsupervised Speech Enhancement Using Nonnegative Matrix Factorization
Sep 15, 2017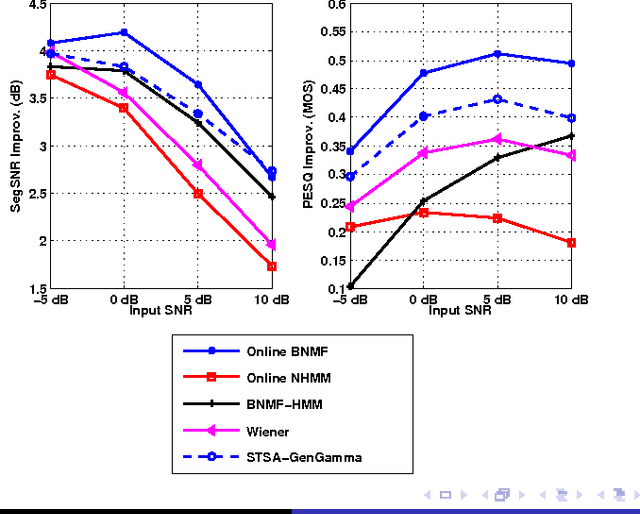
Reducing the interference noise in a monaural noisy speech signal has been a challenging task for many years. Compared to traditional unsupervised speech enhancement methods, e.g., Wiener filtering, supervised approaches, such as algorithms based on hidden Markov models (HMM), lead to higher-quality enhanced speech signals. However, the main practical difficulty of these approaches is that for each noise type a model is required to be trained a priori. In this paper, we investigate a new class of supervised speech denoising algorithms using nonnegative matrix factorization (NMF). We propose a novel speech enhancement method that is based on a Bayesian formulation of NMF (BNMF). To circumvent the mismatch problem between the training and testing stages, we propose two solutions. First, we use an HMM in combination with BNMF (BNMF-HMM) to derive a minimum mean square error (MMSE) estimator for the speech signal with no information about the underlying noise type. Second, we suggest a scheme to learn the required noise BNMF model online, which is then used to develop an unsupervised speech enhancement system. Extensive experiments are carried out to investigate the performance of the proposed methods under different conditions. Moreover, we compare the performance of the developed algorithms with state-of-the-art speech enhancement schemes using various objective measures. Our simulations show that the proposed BNMF-based methods outperform the competing algorithms substantially.
Decorrelation of Neutral Vector Variables: Theory and Applications
May 30, 2017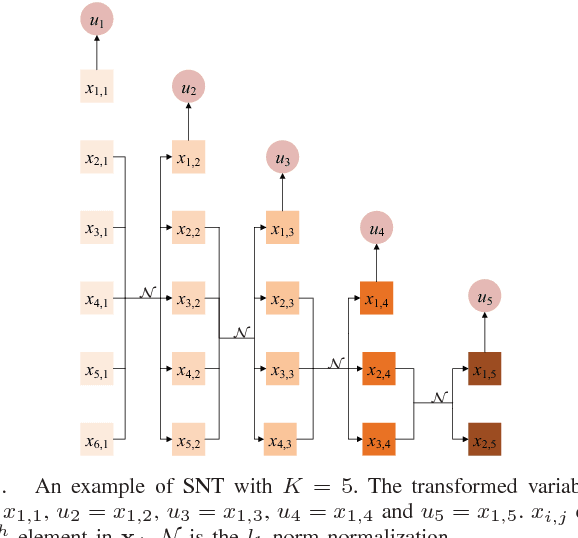
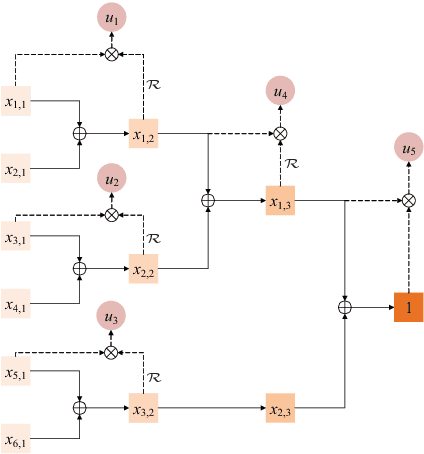
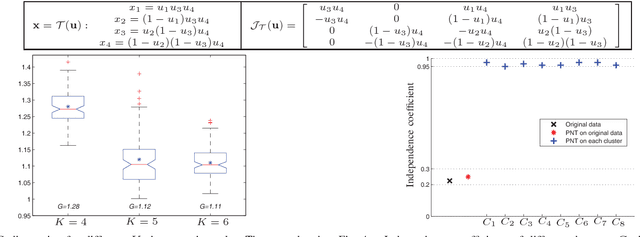
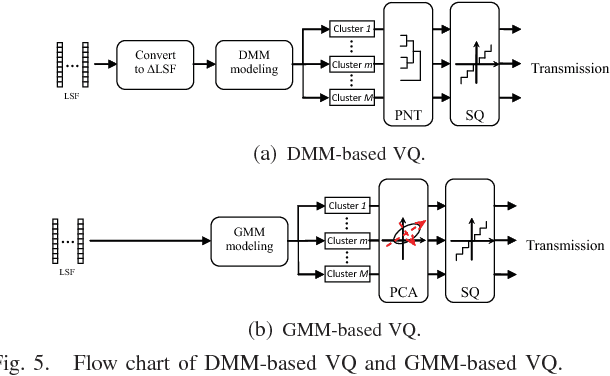
In this paper, we propose novel strategies for neutral vector variable decorrelation. Two fundamental invertible transformations, namely serial nonlinear transformation and parallel nonlinear transformation, are proposed to carry out the decorrelation. For a neutral vector variable, which is not multivariate Gaussian distributed, the conventional principal component analysis (PCA) cannot yield mutually independent scalar variables. With the two proposed transformations, a highly negatively correlated neutral vector can be transformed to a set of mutually independent scalar variables with the same degrees of freedom. We also evaluate the decorrelation performances for the vectors generated from a single Dirichlet distribution and a mixture of Dirichlet distributions. The mutual independence is verified with the distance correlation measurement. The advantages of the proposed decorrelation strategies are intensively studied and demonstrated with synthesized data and practical application evaluations.