 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrativeBridge: Enhancing Video Captioning with Causal-Temporal Narrative
Jun 10, 2024



Existing video captioning benchmarks and models lack coherent representations of causal-temporal narrative, which is sequences of events linked through cause and effect, unfolding over time and driven by characters or agents. This lack of narrative restricts models' ability to generate text descriptions that capture the causal and temporal dynamics inherent in video content. To address this gap, we propose NarrativeBridge, an approach comprising of: (1) a novel Causal-Temporal Narrative (CTN) captions benchmark generated using a large language model and few-shot prompting, explicitly encoding cause-effect temporal relationships in video descriptions, evaluated automatically to ensure caption quality and relevance; and (2) a dedicated Cause-Effect Network (CEN) architecture with separate encoders for capturing cause and effect dynamics independently, enabling effective learning and generation of captions with causal-temporal narrative. Extensive experiments demonstrate that CEN is more accurate in articulating the causal and temporal aspects of video content than the second best model (GIT): 17.88 and 17.44 CIDEr on the MSVD and MSR-VTT datasets, respectively. The proposed framework understands and generates nuanced text descriptions with intricate causal-temporal narrative structures present in videos, addressing a critical limitation in video captioning. For project details, visit https://narrativebridge.github.io/.
CoLeaF: A Contrastive-Collaborative Learning Framework for Weakly Supervised Audio-Visual Video Parsing
May 17, 2024



Weakly supervised audio-visual video parsing (AVVP) methods aim to detect audible-only, visible-only, and audible-visible events using only video-level labels. Existing approaches tackle this by leveraging unimodal and cross-modal contexts. However, we argue that while cross-modal learning is beneficial for detecting audible-visible events, in the weakly supervised scenario, it negatively impacts unaligned audible or visible events by introducing irrelevant modality information. In this paper, we propose CoLeaF, a novel learning framework that optimizes the integration of cross-modal context in the embedding space such that the network explicitly learns to combine cross-modal information for audible-visible events while filtering them out for unaligned events. Additionally, as videos often involve complex class relationships, modelling them improves performance. However, this introduces extra computational costs into the network. Our framework is designed to leverage cross-class relationships during training without incurring additional computations at inference. Furthermore, we propose new metrics to better evaluate a method's capabilities in performing AVVP. Our extensive experiments demonstrate that CoLeaF significantly improves the state-of-the-art results by an average of 1.9% and 2.4% F-score on the LLP and UnAV-100 datasets, respectively.
S3R-Net: A Single-Stage Approach to Self-Supervised Shadow Removal
Apr 18, 2024



In this paper we present S3R-Net, the Self-Supervised Shadow Removal Network. The two-branch WGAN model achieves self-supervision relying on the unify-and-adaptphenomenon - it unifies the style of the output data and infers its characteristics from a database of unaligned shadow-free reference images. This approach stands in contrast to the large body of supervised frameworks. S3R-Net also differentiates itself from the few existing self-supervised models operating in a cycle-consistent manner, as it is a non-cyclic, unidirectional solution. The proposed framework achieves comparable numerical scores to recent selfsupervised shadow removal models while exhibiting superior qualitative performance and keeping the computational cost low.
ViscoNet: Bridging and Harmonizing Visual and Textual Conditioning for ControlNet
Dec 05, 2023



This paper introduces ViscoNet, a novel method that enhances text-to-image human generation models with visual prompting. Unlike existing methods that rely on lengthy text descriptions to control the image structure, ViscoNet allows users to specify the visual appearance of the target object with a reference image. ViscoNet disentangles the object's appearance from the image background and injects it into a pre-trained latent diffusion model (LDM) model via a ControlNet branch. This way, ViscoNet mitigates the style mode collapse problem and enables precise and flexible visual control. We demonstrate the effectiveness of ViscoNet on human image generation, where it can manipulate visual attributes and artistic styles with text and image prompts. We also show that ViscoNet can learn visual conditioning from small and specific object domains while preserving the generative power of the LDM backbone.
CAD -- Contextual Multi-modal Alignment for Dynamic AVQA
Oct 27, 2023In the context of Audio Visual Question Answering (AVQA) tasks, the audio visual modalities could be learnt on three levels: 1) Spatial, 2) Temporal, and 3) Semantic. Existing AVQA methods suffer from two major shortcomings; the audio-visual (AV) information passing through the network isn't aligned on Spatial and Temporal levels; and, inter-modal (audio and visual) Semantic information is often not balanced within a context; this results in poor performance. In this paper, we propose a novel end-to-end Contextual Multi-modal Alignment (CAD) network that addresses the challenges in AVQA methods by i) introducing a parameter-free stochastic Contextual block that ensures robust audio and visual alignment on the Spatial level; ii) proposing a pre-training technique for dynamic audio and visual alignment on Temporal level in a self-supervised setting, and iii) introducing a cross-attention mechanism to balance audio and visual information on Semantic level. The proposed novel CAD network improves the overall performance over the state-of-the-art methods on average by 9.4% on the MUSIC-AVQA dataset. We also demonstrate that our proposed contributions to AVQA can be added to the existing methods to improve their performance without additional complexity requirements.
PAT: Position-Aware Transformer for Dense Multi-Label Action Detection
Aug 09, 2023



We present PAT, a transformer-based network that learns complex temporal co-occurrence action dependencies in a video by exploiting multi-scale temporal features. In existing methods, the self-attention mechanism in transformers loses the temporal positional information, which is essential for robust action detection. To address this issue, we (i) embed relative positional encoding in the self-attention mechanism and (ii) exploit multi-scale temporal relationships by designing a novel non hierarchical network, in contrast to the recent transformer-based approaches that use a hierarchical structure. We argue that joining the self-attention mechanism with multiple sub-sampling processes in the hierarchical approaches results in increased loss of positional information. We evaluate the performance of our proposed approach on two challenging dense multi-label benchmark datasets, and show that PAT improves the current state-of-the-art result by 1.1% and 0.6% mAP on the Charades and MultiTHUMOS datasets, respectively, thereby achieving the new state-of-the-art mAP at 26.5% and 44.6%, respectively. We also perform extensive ablation studies to examine the impact of the different components of our proposed network.
UPGPT: Universal Diffusion Model for Person Image Generation, Editing and Pose Transfer
Apr 18, 2023Existing person image generative models can do either image generation or pose transfer but not both. We propose a unified diffusion model, UPGPT to provide a universal solution to perform all the person image tasks - generative, pose transfer, and editing. With fine-grained multimodality and disentanglement capabilities, our approach offers fine-grained control over the generation and the editing process of images using a combination of pose, text, and image, all without needing a semantic segmentation mask which can be challenging to obtain or edit. We also pioneer the parameterized body SMPL model in pose-guided person image generation to demonstrate new capability - simultaneous pose and camera view interpolation while maintaining a person's appearance. Results on the benchmark DeepFashion dataset show that UPGPT is the new state-of-the-art while simultaneously pioneering new capabilities of edit and pose transfer in human image generation.
SEM-POS: Grammatically and Semantically Correct Video Captioning
Apr 04, 2023



Generating grammatically and semantically correct captions in video captioning is a challenging task. The captions generated from the existing methods are either word-by-word that do not align with grammatical structure or miss key information from the input videos. To address these issues, we introduce a novel global-local fusion network, with a Global-Local Fusion Block (GLFB) that encodes and fuses features from different parts of speech (POS) components with visual-spatial features. We use novel combinations of different POS components - 'determinant + subject', 'auxiliary verb', 'verb', and 'determinant + object' for supervision of the POS blocks - Det + Subject, Aux Verb, Verb, and Det + Object respectively. The novel global-local fusion network together with POS blocks helps align the visual features with language description to generate grammatically and semantically correct captions. Extensive qualitative and quantitative experiments on benchmark MSVD and MSRVTT datasets demonstrate that the proposed approach generates more grammatically and semantically correct captions compared to the existing methods, achieving the new state-of-the-art. Ablations on the POS blocks and the GLFB demonstrate the impact of the contributions on the proposed method.
Pose Guided Multi-person Image Generation From Text
Mar 09, 2022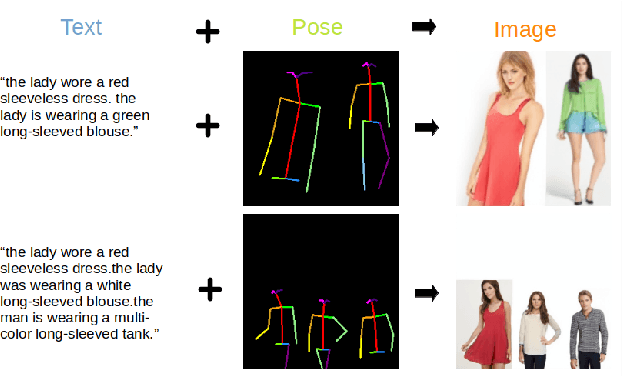
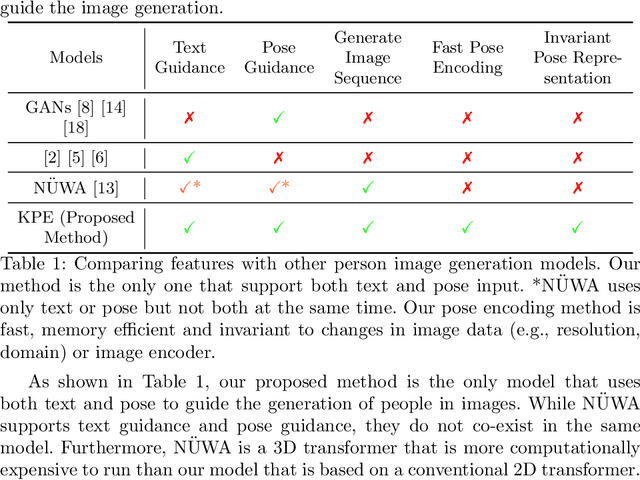
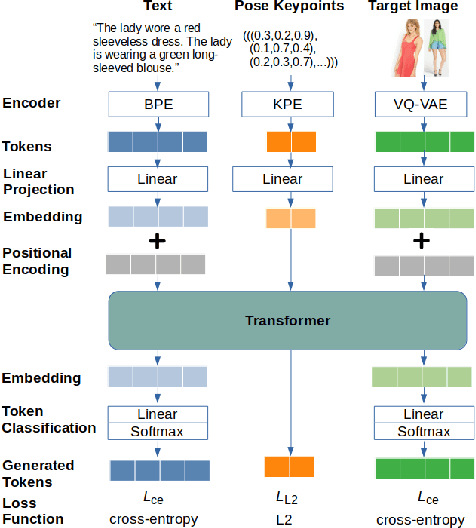
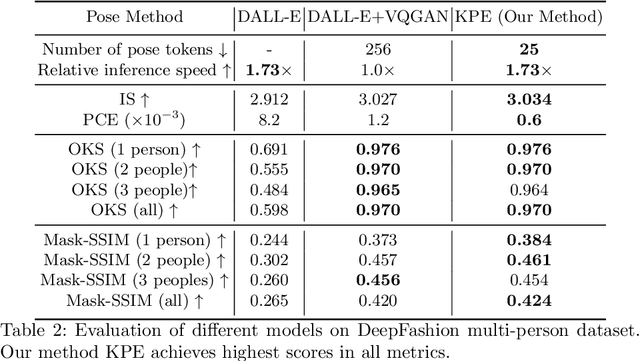
Transformers have recently been shown to generate high quality images from texts. However, existing methods struggle to create high fidelity full-body images, especially multiple people. A person's pose has a high degree of freedom that is difficult to describe using words only; this creates errors in the generated image, such as incorrect body proportions and pose. We propose a pose-guided text-to-image model, using pose as an additional input constraint. Using the proposed Keypoint Pose Encoding (KPE) to encode human pose into low dimensional representation, our model can generate novel multi-person images accurately representing the pose and text descriptions provided, with minimal errors. We demonstrate that KPE is invariant to changes in the target image domain and image resolution; we show results on the Deepfashion dataset and create a new multi-person Deepfashion dataset to demonstrate the multi-capabilities of our approach.
SILT: Self-supervised Lighting Transfer Using Implicit Image Decomposition
Oct 25, 2021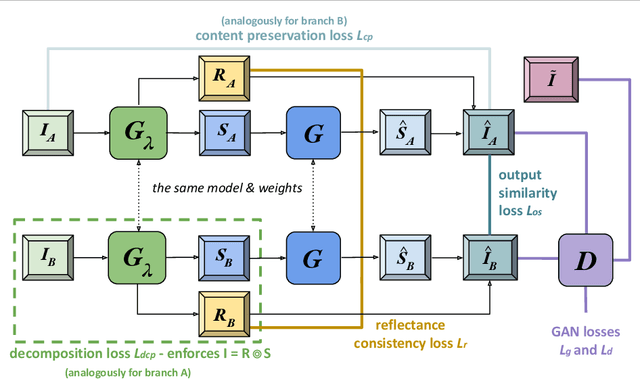
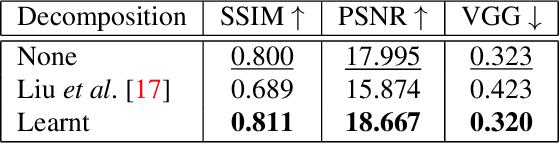
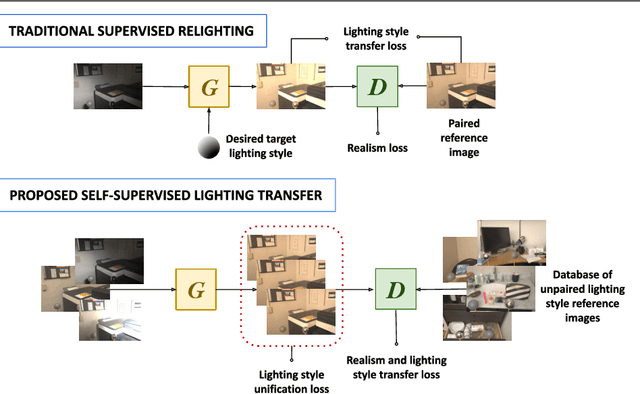
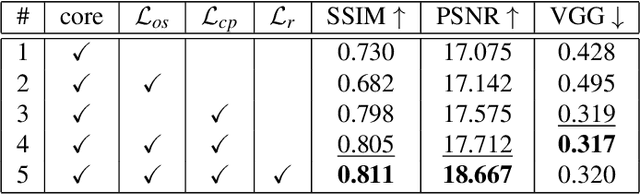
We present SILT, a Self-supervised Implicit Lighting Transfer method. Unlike previous research on scene relighting, we do not seek to apply arbitrary new lighting configurations to a given scene. Instead, we wish to transfer the lighting style from a database of other scenes, to provide a uniform lighting style regardless of the input. The solution operates as a two-branch network that first aims to map input images of any arbitrary lighting style to a unified domain, with extra guidance achieved through implicit image decomposition. We then remap this unified input domain using a discriminator that is presented with the generated outputs and the style reference, i.e. images of the desired illumination conditions. Our method is shown to outperform supervised relighting solutions across two different datasets without requiring lighting supervision.