 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual N-Grams from Web Data
Aug 06, 2017
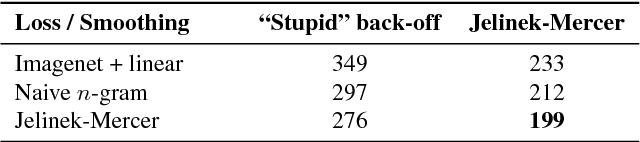


Real-world image recognition systems need to recognize tens of thousands of classes that constitute a plethora of visual concepts. The traditional approach of annotating thousands of images per class for training is infeasible in such a scenario, prompting the use of webly supervised data. This paper explores the training of image-recognition systems on large numbers of images and associated user comments. In particular, we develop visual n-gram models that can predict arbitrary phrases that are relevant to the content of an image. Our visual n-gram models are feed-forward convolutional networks trained using new loss functions that are inspired by n-gram models commonly used in language modeling. We demonstrate the merits of our models in phrase prediction, phrase-based image retrieval, relating images and captions, and zero-shot transfer.
Optimizing the Latent Space of Generative Networks
Jul 18, 2017
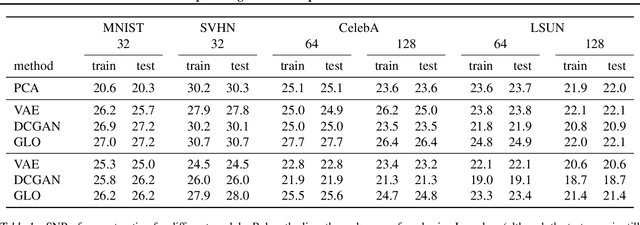


Generative Adversarial Networks (GANs) have been shown to be able to sample impressively realistic images. GAN training consists of a saddle point optimization problem that can be thought of as an adversarial game between a generator which produces the images, and a discriminator, which judges if the images are real. Both the generator and the discriminator are commonly parametrized as deep convolutional neural networks. The goal of this paper is to disentangle the contribution of the optimization procedure and the network parametrization to the success of GANs. To this end we introduce and study Generative Latent Optimization (GLO), a framework to train a generator without the need to learn a discriminator, thus avoiding challenging adversarial optimization problems. We show experimentally that GLO enjoys many of the desirable properties of GANs: learning from large data, synthesizing visually-appealing samples, interpolating meaningfully between samples, and performing linear arithmetic with noise vectors.
Enriching Word Vectors with Subword Information
Jun 19, 2017Continuous word representations, trained on large unlabeled corpora are useful for many natural language processing tasks. Popular models that learn such representations ignore the morphology of words, by assigning a distinct vector to each word. This is a limitation, especially for languages with large vocabularies and many rare words. In this paper, we propose a new approach based on the skipgram model, where each word is represented as a bag of character $n$-grams. A vector representation is associated to each character $n$-gram; words being represented as the sum of these representations. Our method is fast, allowing to train models on large corpora quickly and allows us to compute word representations for words that did not appear in the training data. We evaluate our word representations on nine different languages, both on word similarity and analogy tasks. By comparing to recently proposed morphological word representations, we show that our vectors achieve state-of-the-art performance on these tasks.
Efficient softmax approximation for GPUs
Jun 19, 2017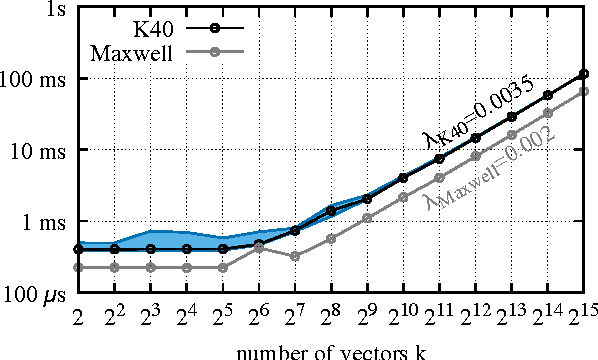
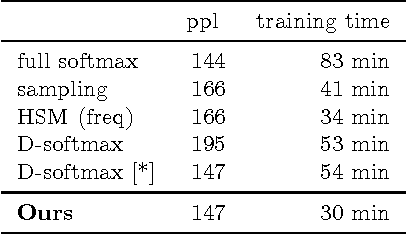
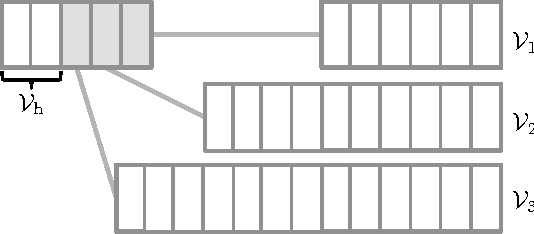
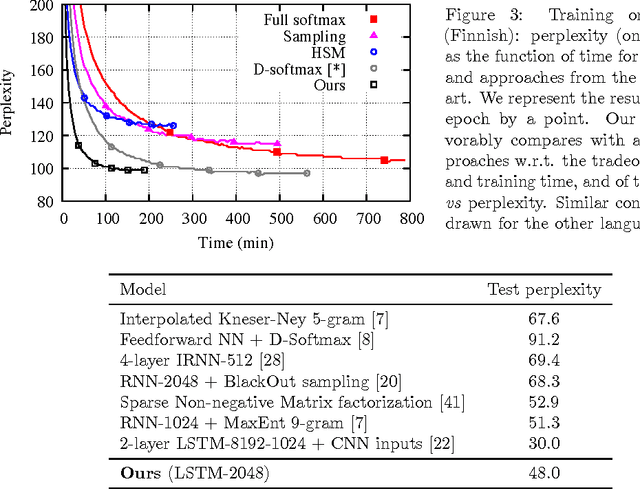
We propose an approximate strategy to efficiently train neural network based language models over very large vocabularies. Our approach, called adaptive softmax, circumvents the linear dependency on the vocabulary size by exploiting the unbalanced word distribution to form clusters that explicitly minimize the expectation of computation time. Our approach further reduces the computational time by exploiting the specificities of modern architectures and matrix-matrix vector operations, making it particularly suited for graphical processing units. Our experiments carried out on standard benchmarks, such as EuroParl and One Billion Word, show that our approach brings a large gain in efficiency over standard approximations while achieving an accuracy close to that of the full softmax. The code of our method is available at https://github.com/facebookresearch/adaptive-softmax.
Unsupervised Learning by Predicting Noise
Apr 18, 2017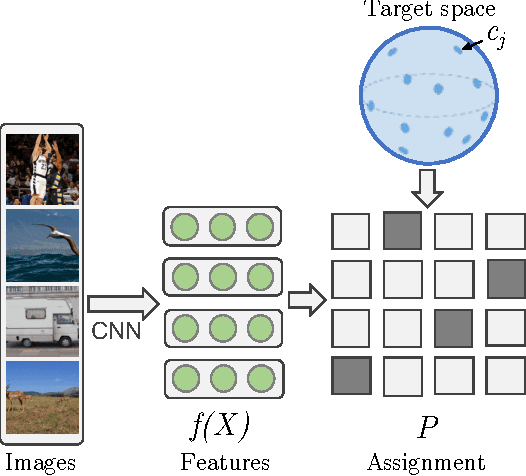

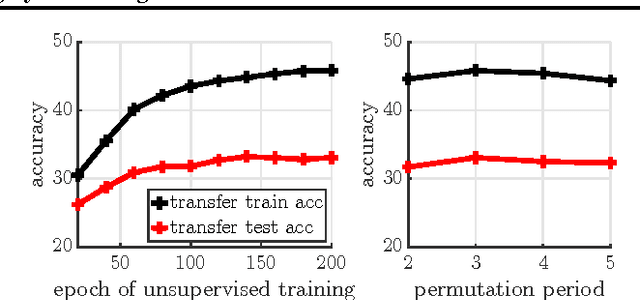
Convolutional neural networks provide visual features that perform remarkably well in many computer vision applications. However, training these networks requires significant amounts of supervision. This paper introduces a generic framework to train deep networks, end-to-end, with no supervision. We propose to fix a set of target representations, called Noise As Targets (NAT), and to constrain the deep features to align to them. This domain agnostic approach avoids the standard unsupervised learning issues of trivial solutions and collapsing of features. Thanks to a stochastic batch reassignment strategy and a separable square loss function, it scales to millions of images. The proposed approach produces representations that perform on par with state-of-the-art unsupervised methods on ImageNet and Pascal VOC.
CommAI: Evaluating the first steps towards a useful general AI
Mar 27, 2017With machine learning successfully applied to new daunting problems almost every day, general AI starts looking like an attainable goal. However, most current research focuses instead on important but narrow applications, such as image classification or machine translation. We believe this to be largely due to the lack of objective ways to measure progress towards broad machine intelligence. In order to fill this gap, we propose here a set of concrete desiderata for general AI, together with a platform to test machines on how well they satisfy such desiderata, while keeping all further complexities to a minimum.
Variable Computation in Recurrent Neural Networks
Mar 02, 2017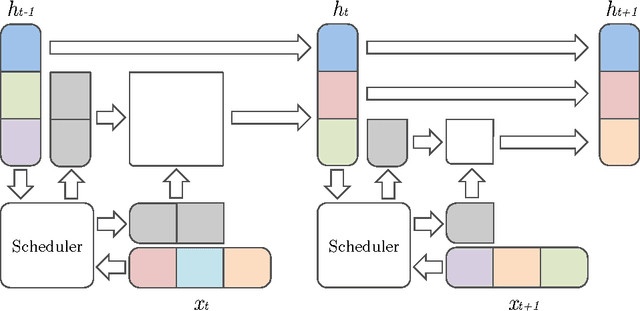


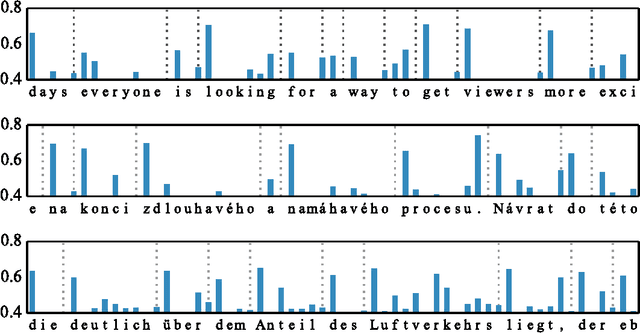
Recurrent neural networks (RNNs) have been used extensively and with increasing success to model various types of sequential data. Much of this progress has been achieved through devising recurrent units and architectures with the flexibility to capture complex statistics in the data, such as long range dependency or localized attention phenomena. However, while many sequential data (such as video, speech or language) can have highly variable information flow, most recurrent models still consume input features at a constant rate and perform a constant number of computations per time step, which can be detrimental to both speed and model capacity. In this paper, we explore a modification to existing recurrent units which allows them to learn to vary the amount of computation they perform at each step, without prior knowledge of the sequence's time structure. We show experimentally that not only do our models require fewer operations, they also lead to better performance overall on evaluation tasks.
Improving Neural Language Models with a Continuous Cache
Dec 13, 2016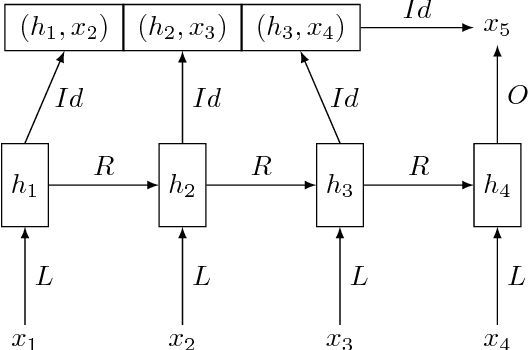

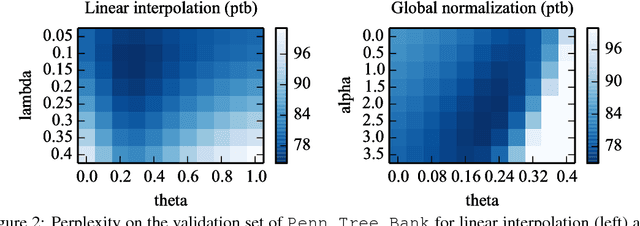

We propose an extension to neural network language models to adapt their prediction to the recent history. Our model is a simplified version of memory augmented networks, which stores past hidden activations as memory and accesses them through a dot product with the current hidden activation. This mechanism is very efficient and scales to very large memory sizes. We also draw a link between the use of external memory in neural network and cache models used with count based language models. We demonstrate on several language model datasets that our approach performs significantly better than recent memory augmented networks.
FastText.zip: Compressing text classification models
Dec 12, 2016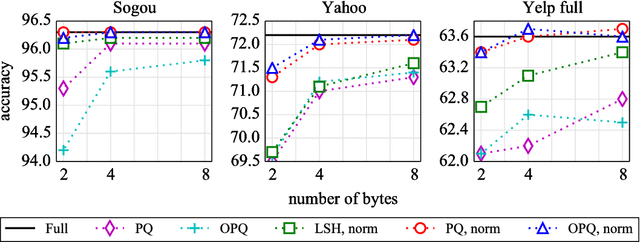
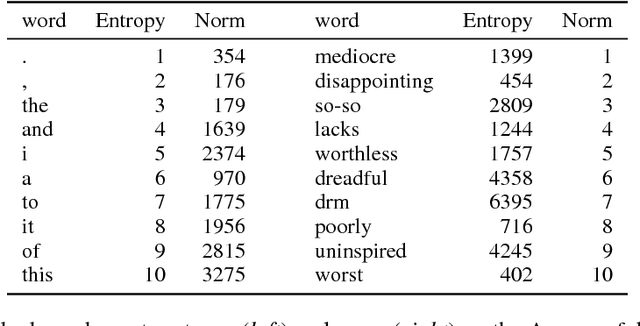
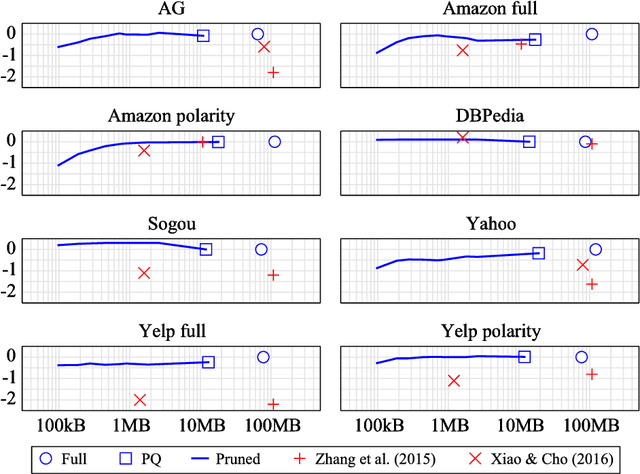
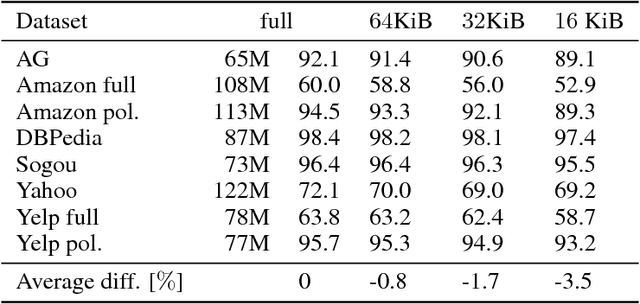
We consider the problem of producing compact architectures for text classification, such that the full model fits in a limited amount of memory. After considering different solutions inspired by the hashing literature, we propose a method built upon product quantization to store word embeddings. While the original technique leads to a loss in accuracy, we adapt this method to circumvent quantization artefacts. Our experiments carried out on several benchmarks show that our approach typically requires two orders of magnitude less memory than fastText while being only slightly inferior with respect to accuracy. As a result, it outperforms the state of the art by a good margin in terms of the compromise between memory usage and accuracy.
Revisiting Visual Question Answering Baselines
Nov 22, 2016
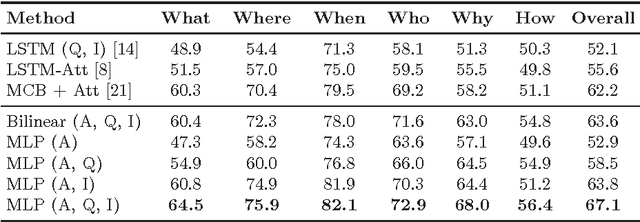
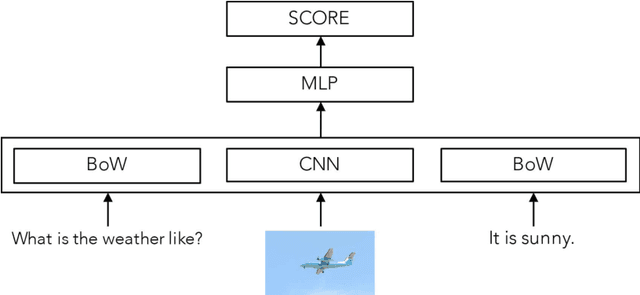
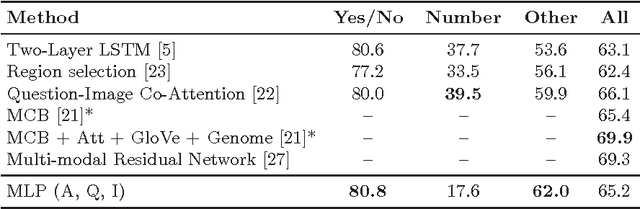
Visual question answering (VQA) is an interesting learning setting for evaluating the abilities and shortcomings of current systems for image understanding. Many of the recently proposed VQA systems include attention or memory mechanisms designed to support "reasoning". For multiple-choice VQA, nearly all of these systems train a multi-class classifier on image and question features to predict an answer. This paper questions the value of these common practices and develops a simple alternative model based on binary classification. Instead of treating answers as competing choices, our model receives the answer as input and predicts whether or not an image-question-answer triplet is correct. We evaluate our model on the Visual7W Telling and the VQA Real Multiple Choice tasks, and find that even simple versions of our model perform competitively. Our best model achieves state-of-the-art performance on the Visual7W Telling task and compares surprisingly well with the most complex systems proposed for the VQA Real Multiple Choice task. We explore variants of the model and study its transferability between both datasets. We also present an error analysis of our model that suggests a key problem of current VQA systems lies in the lack of visual grounding of concepts that occur in the questions and answers. Overall, our results suggest that the performance of current VQA systems is not significantly better than that of systems designed to exploit dataset biases.