 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMBRACE: Shaping Inclusive Opinion Representation by Aligning Implicit Conversations with Social Norms
Jul 27, 2025Shaping inclusive representations that embrace diversity and ensure fair participation and reflections of values is at the core of many conversation-based models. However, many existing methods rely on surface inclusion using mention of user demographics or behavioral attributes of social groups. Such methods overlook the nuanced, implicit expression of opinion embedded in conversations. Furthermore, the over-reliance on overt cues can exacerbate misalignment and reinforce harmful or stereotypical representations in model outputs. Thus, we took a step back and recognized that equitable inclusion needs to account for the implicit expression of opinion and use the stance of responses to validate the normative alignment. This study aims to evaluate how opinions are represented in NLP or computational models by introducing an alignment evaluation framework that foregrounds implicit, often overlooked conversations and evaluates the normative social views and discourse. Our approach models the stance of responses as a proxy for the underlying opinion, enabling a considerate and reflective representation of diverse social viewpoints. We evaluate the framework using both (i) positive-unlabeled (PU) online learning with base classifiers, and (ii) instruction-tuned language models to assess post-training alignment. Through this, we provide a lens on how implicit opinions are (mis)represented and offer a pathway toward more inclusive model behavior.
Covert Bias: The Severity of Social Views' Unalignment Towards Implicit and Explicit Opinion
Aug 15, 2024While various approaches have recently been studied for bias identification, little is known about how implicit language that does not explicitly convey a viewpoint affects bias amplification in large language models.To examine the severity of bias toward a view, we evaluated the performance of two downstream tasks where the implicit and explicit knowledge of social groups were used. First, we present a stress test evaluation by using a biased model in edge cases of excessive bias scenarios. Then, we evaluate how LLMs calibrate linguistically in response to both implicit and explicit opinions when they are aligned with conflicting viewpoints. Our findings reveal a discrepancy in LLM performance in identifying implicit and explicit opinions, with a general tendency of bias toward explicit opinions of opposing stances. Moreover, the bias-aligned models generate more cautious responses using uncertainty phrases compared to the unaligned (zero-shot) base models. The direct, incautious responses of the unaligned models suggest a need for further refinement of decisiveness by incorporating uncertainty markers to enhance their reliability, especially on socially nuanced topics with high subjectivity.
Re-Ranking Words to Improve Interpretability of Automatically Generated Topics
Mar 29, 2019

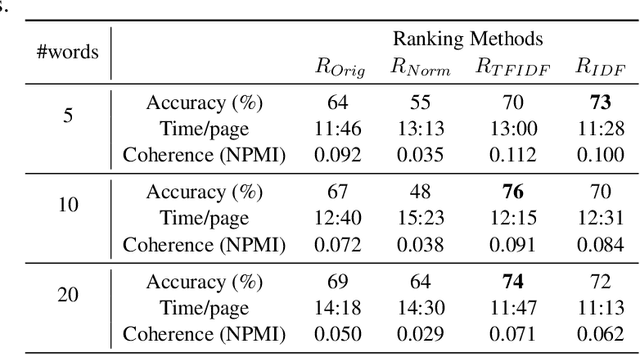
Topics models, such as LDA, are widely used in Natural Language Processing. Making their output interpretable is an important area of research with applications to areas such as the enhancement of exploratory search interfaces and the development of interpretable machine learning models. Conventionally, topics are represented by their n most probable words, however, these representations are often difficult for humans to interpret. This paper explores the re-ranking of topic words to generate more interpretable topic representations. A range of approaches are compared and evaluated in two experiments. The first uses crowdworkers to associate topics represented by different word rankings with related documents. The second experiment is an automatic approach based on a document retrieval task applied on multiple domains. Results in both experiments demonstrate that re-ranking words improves topic interpretability and that the most effective re-ranking schemes were those which combine information about the importance of words both within topics and their relative frequency in the entire corpus. In addition, close correlation between the results of the two evaluation approaches suggests that the automatic method proposed here could be used to evaluate re-ranking methods without the need for human judgements.