 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Floating Point Overheads for Mixed Precision DNN Accelerators
Jan 27, 2021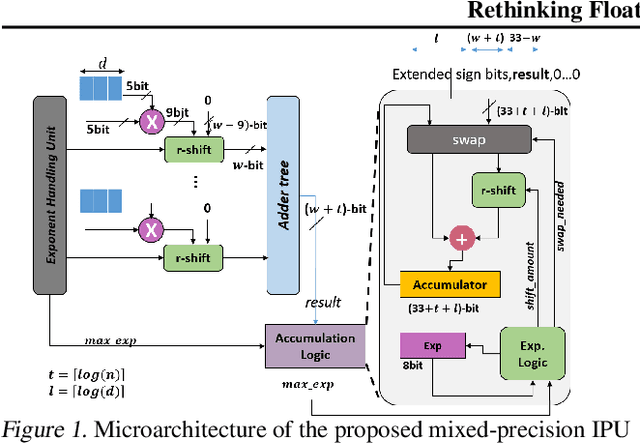
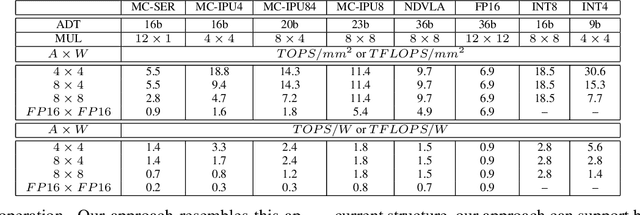


In this paper, we propose a mixed-precision convolution unit architecture which supports different integer and floating point (FP) precisions. The proposed architecture is based on low-bit inner product units and realizes higher precision based on temporal decomposition. We illustrate how to integrate FP computations on integer-based architecture and evaluate overheads incurred by FP arithmetic support. We argue that alignment and addition overhead for FP inner product can be significant since the maximum exponent difference could be up to 58 bits, which results into a large alignment logic. To address this issue, we illustrate empirically that no more than 26-bitproduct bits are required and up to 8-bit of alignment is sufficient in most inference cases. We present novel optimizations based on the above observations to reduce the FP arithmetic hardware overheads. Our empirical results, based on simulation and hardware implementation, show significant reduction in FP16 overhead. Over typical mixed precision implementation, the proposed architecture achieves area improvements of up to 25% in TFLOPS/mm2and up to 46% in TOPS/mm2with power efficiency improvements of up to 40% in TFLOPS/Wand up to 63% in TOPS/W.
Campfire: Compressible, Regularization-Free, Structured Sparse Training for Hardware Accelerators
Jan 13, 2020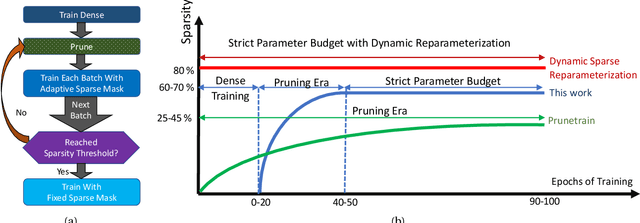
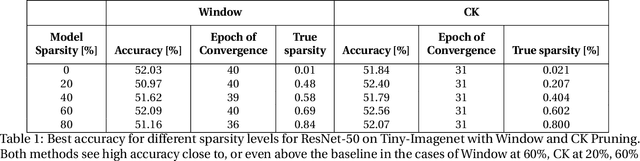
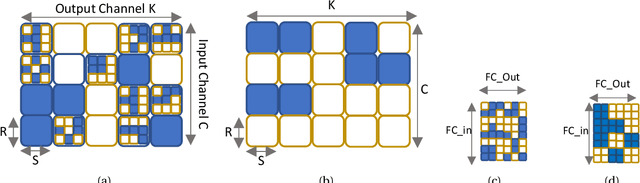
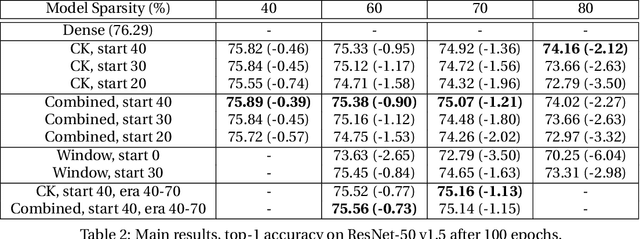
This paper studies structured sparse training of CNNs with a gradual pruning technique that leads to fixed, sparse weight matrices after a set number of epochs. We simplify the structure of the enforced sparsity so that it reduces overhead caused by regularization. The proposed training methodology Campfire explores pruning at granularities within a convolutional kernel and filter. We study various tradeoffs with respect to pruning duration, level of sparsity, and learning rate configuration. We show that our method creates a sparse version of ResNet-50 and ResNet-50 v1.5 on full ImageNet while remaining within a negligible <1% margin of accuracy loss. To ensure that this type of sparse training does not harm the robustness of the network, we also demonstrate how the network behaves in the presence of adversarial attacks. Our results show that with 70% target sparsity, over 75% top-1 accuracy is achievable.
CATERPILLAR: Coarse Grain Reconfigurable Architecture for Accelerating the Training of Deep Neural Networks
Jun 08, 2017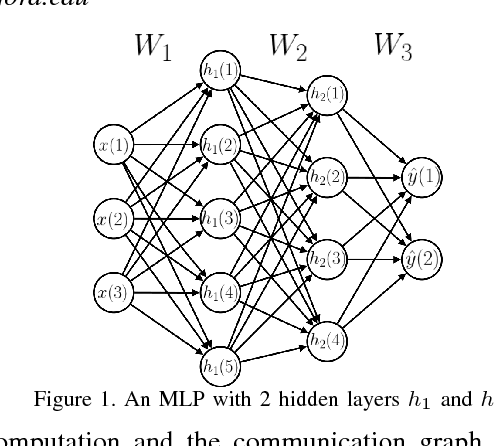
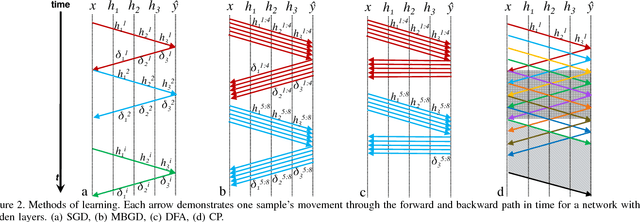
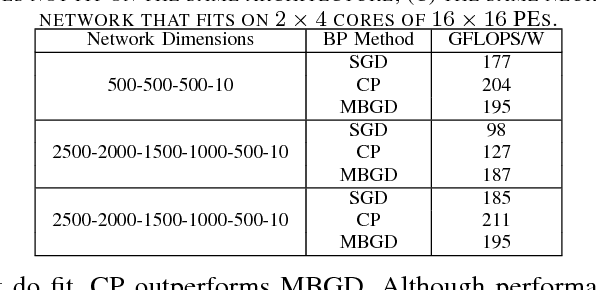
Accelerating the inference of a trained DNN is a well studied subject. In this paper we switch the focus to the training of DNNs. The training phase is compute intensive, demands complicated data communication, and contains multiple levels of data dependencies and parallelism. This paper presents an algorithm/architecture space exploration of efficient accelerators to achieve better network convergence rates and higher energy efficiency for training DNNs. We further demonstrate that an architecture with hierarchical support for collective communication semantics provides flexibility in training various networks performing both stochastic and batched gradient descent based techniques. Our results suggest that smaller networks favor non-batched techniques while performance for larger networks is higher using batched operations. At 45nm technology, CATERPILLAR achieves performance efficiencies of 177 GFLOPS/W at over 80% utilization for SGD training on small networks and 211 GFLOPS/W at over 90% utilization for pipelined SGD/CP training on larger networks using a total area of 103.2 mm$^2$ and 178.9 mm$^2$ respectively.
A Systematic Approach to Blocking Convolutional Neural Networks
Jun 14, 2016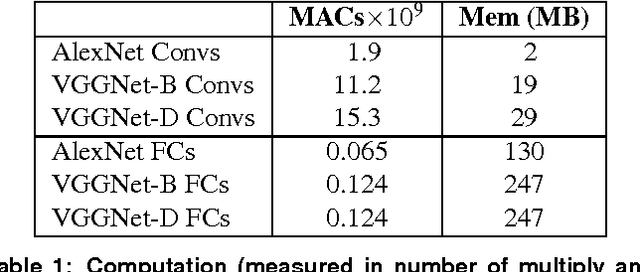
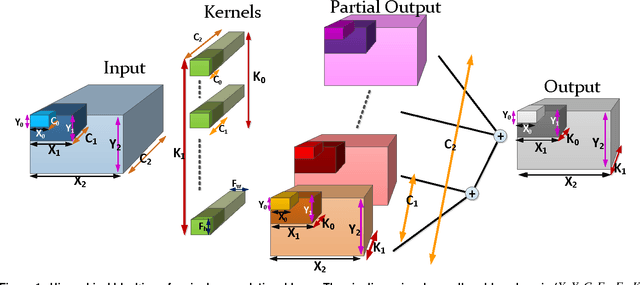
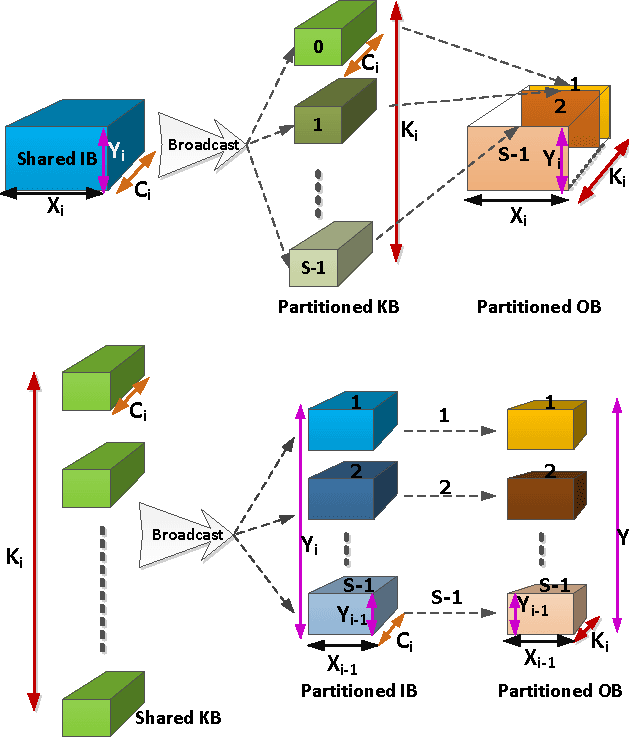

Convolutional Neural Networks (CNNs) are the state of the art solution for many computer vision problems, and many researchers have explored optimized implementations. Most implementations heuristically block the computation to deal with the large data sizes and high data reuse of CNNs. This paper explores how to block CNN computations for memory locality by creating an analytical model for CNN-like loop nests. Using this model we automatically derive optimized blockings for common networks that improve the energy efficiency of custom hardware implementations by up to an order of magnitude. Compared to traditional CNN CPU implementations based on highly-tuned, hand-optimized BLAS libraries,our x86 programs implementing the optimal blocking reduce the number of memory accesses by up to 90%.
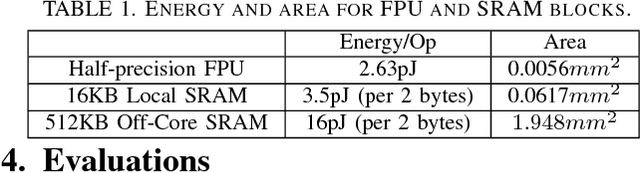
EIE: Efficient Inference Engine on Compressed Deep Neural Network
May 03, 2016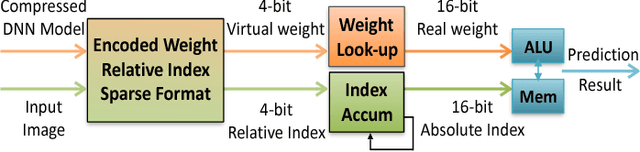
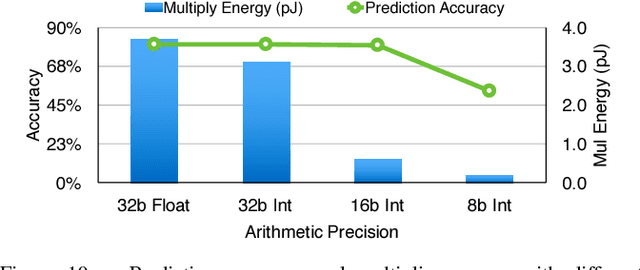


State-of-the-art deep neural networks (DNNs) have hundreds of millions of connections and are both computationally and memory intensive, making them difficult to deploy on embedded systems with limited hardware resources and power budgets. While custom hardware helps the computation, fetching weights from DRAM is two orders of magnitude more expensive than ALU operations, and dominates the required power. Previously proposed 'Deep Compression' makes it possible to fit large DNNs (AlexNet and VGGNet) fully in on-chip SRAM. This compression is achieved by pruning the redundant connections and having multiple connections share the same weight. We propose an energy efficient inference engine (EIE) that performs inference on this compressed network model and accelerates the resulting sparse matrix-vector multiplication with weight sharing. Going from DRAM to SRAM gives EIE 120x energy saving; Exploiting sparsity saves 10x; Weight sharing gives 8x; Skipping zero activations from ReLU saves another 3x. Evaluated on nine DNN benchmarks, EIE is 189x and 13x faster when compared to CPU and GPU implementations of the same DNN without compression. EIE has a processing power of 102GOPS/s working directly on a compressed network, corresponding to 3TOPS/s on an uncompressed network, and processes FC layers of AlexNet at 1.88x10^4 frames/sec with a power dissipation of only 600mW. It is 24,000x and 3,400x more energy efficient than a CPU and GPU respectively. Compared with DaDianNao, EIE has 2.9x, 19x and 3x better throughput, energy efficiency and area efficiency.