 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Machines that Trust: AI Agents Learn to Trust in the Trust Game
Dec 20, 2023Widely considered a cornerstone of human morality, trust shapes many aspects of human social interactions. In this work, we present a theoretical analysis of the $\textit{trust game}$, the canonical task for studying trust in behavioral and brain sciences, along with simulation results supporting our analysis. Specifically, leveraging reinforcement learning (RL) to train our AI agents, we systematically investigate learning trust under various parameterizations of this task. Our theoretical analysis, corroborated by the simulations results presented, provides a mathematical basis for the emergence of trust in the trust game.
Cognitive Models as Simulators: The Case of Moral Decision-Making
Oct 08, 2022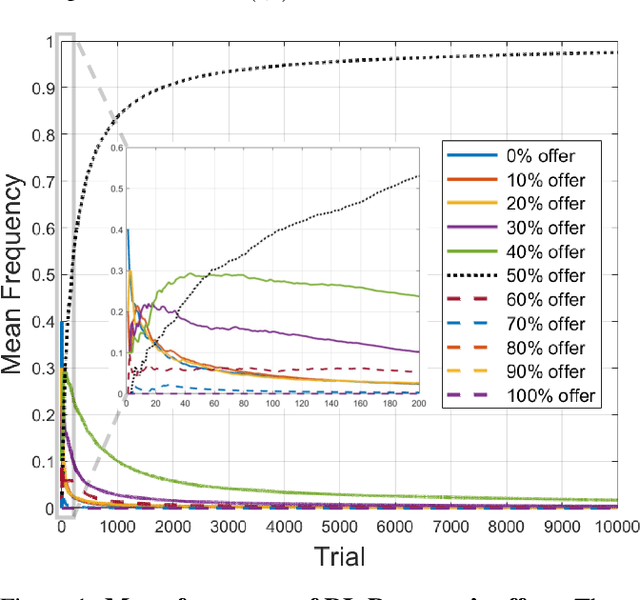
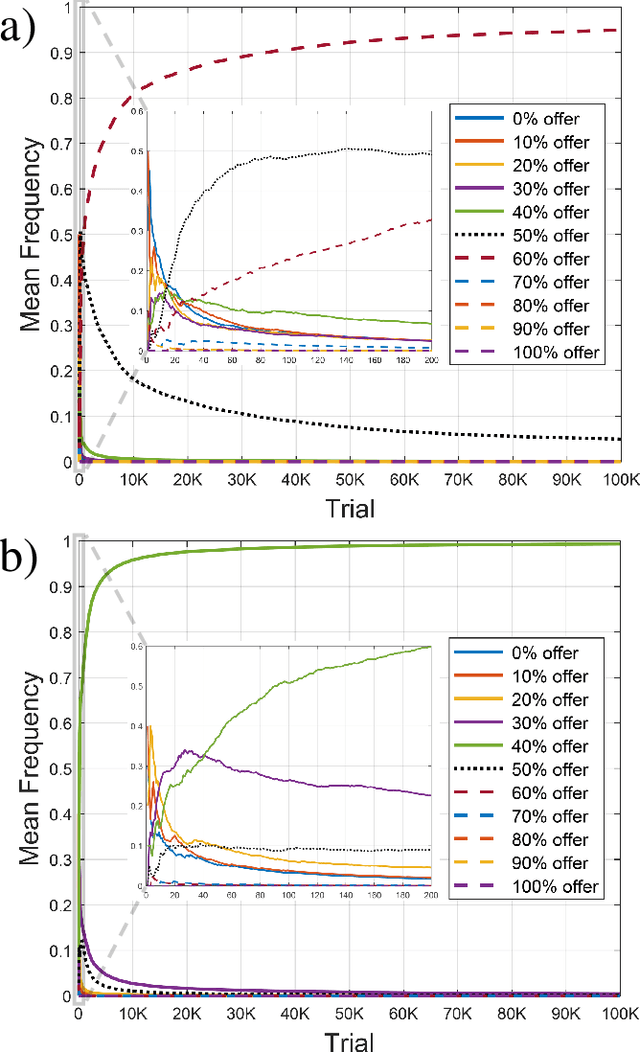
To achieve desirable performance, current AI systems often require huge amounts of training data. This is especially problematic in domains where collecting data is both expensive and time-consuming, e.g., where AI systems require having numerous interactions with humans, collecting feedback from them. In this work, we substantiate the idea of $\textit{cognitive models as simulators}$, which is to have AI systems interact with, and collect feedback from, cognitive models instead of humans, thereby making their training process both less costly and faster. Here, we leverage this idea in the context of moral decision-making, by having reinforcement learning (RL) agents learn about fairness through interacting with a cognitive model of the Ultimatum Game (UG), a canonical task in behavioral and brain sciences for studying fairness. Interestingly, these RL agents learn to rationally adapt their behavior depending on the emotional state of their simulated UG responder. Our work suggests that using cognitive models as simulators of humans is an effective approach for training AI systems, presenting an important way for computational cognitive science to make contributions to AI.
Bringing Order to the Cognitive Fallacy Zoo
Oct 15, 2018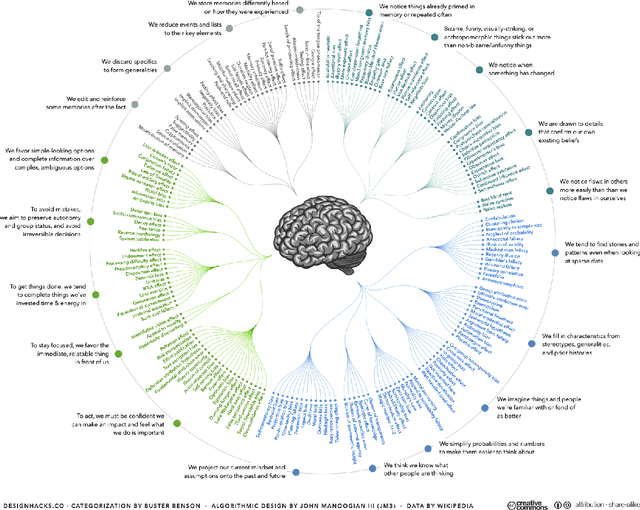
In the eyes of a rationalist like Descartes or Spinoza, human reasoning is flawless, marching toward uncovering ultimate truth. A few centuries later, however, culminating in the work of Kahneman and Tversky, human reasoning was portrayed as anything but flawless, filled with numerous misjudgments, biases, and cognitive fallacies. With further investigations, new cognitive fallacies continually emerged, leading to a state of affairs which can fairly be characterized as the cognitive fallacy zoo! In this largely methodological work, we formally present a principled way to bring order to this zoo. We introduce the idea of establishing implication relationships (IRs) between cognitive fallacies, formally characterizing how one fallacy implies another. IR is analogous to, and partly inspired by, the fundamental concept of reduction in computational complexity theory. We present several examples of IRs involving experimentally well-documented cognitive fallacies: base-rate neglect, availability bias, conjunction fallacy, decoy effect, framing effect, and Allais paradox. We conclude by discussing how our work: (i) allows for identifying those pivotal cognitive fallacies whose investigation would be the most rewarding research agenda, and importantly (ii) permits a systematized, guided research program on cognitive fallacies, motivating influential theoretical as well as experimental avenues of future research.
A Rational Distributed Process-level Account of Independence Judgment
Jan 30, 2018



It is inconceivable how chaotic the world would look to humans, faced with innumerable decisions a day to be made under uncertainty, had they been lacking the capacity to distinguish the relevant from the irrelevant---a capacity which computationally amounts to handling probabilistic independence relations. The highly parallel and distributed computational machinery of the brain suggests that a satisfying process-level account of human independence judgment should also mimic these features. In this work, we present the first rational, distributed, message-passing, process-level account of independence judgment, called $\mathcal{D}^\ast$. Interestingly, $\mathcal{D}^\ast$ shows a curious, but normatively-justified tendency for quick detection of dependencies, whenever they hold. Furthermore, $\mathcal{D}^\ast$ outperforms all the previously proposed algorithms in the AI literature in terms of worst-case running time, and a salient aspect of it is supported by recent work in neuroscience investigating possible implementations of Bayes nets at the neural level. $\mathcal{D}^\ast$ nicely exemplifies how the pursuit of cognitive plausibility can lead to the discovery of state-of-the-art algorithms with appealing properties, and its simplicity makes $\mathcal{D}^\ast$ potentially a good candidate for pedagogical purposes.
Over-representation of Extreme Events in Decision-Making: A Rational Metacognitive Account
Jan 30, 2018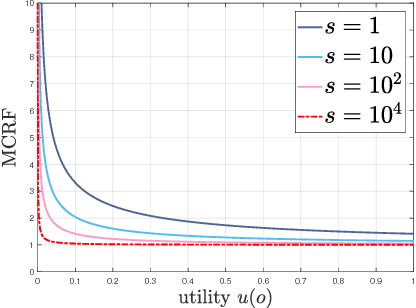
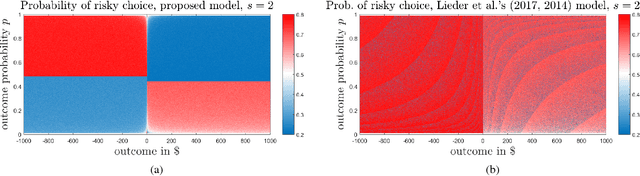
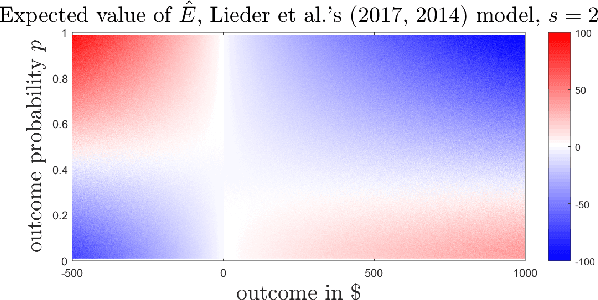
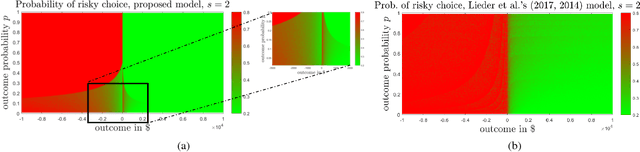
The Availability bias, manifested in the over-representation of extreme eventualities in decision-making, is a well-known cognitive bias, and is generally taken as evidence of human irrationality. In this work, we present the first rational, metacognitive account of the Availability bias, formally articulated at Marr's algorithmic level of analysis. Concretely, we present a normative, metacognitive model of how a cognitive system should over-represent extreme eventualities, depending on the amount of time available at its disposal for decision-making. Our model also accounts for two well-known framing effects in human decision-making under risk---the fourfold pattern of risk preferences in outcome probability (Tversky & Kahneman, 1992) and in outcome magnitude (Markovitz, 1952)---thereby providing the first metacognitively-rational basis for those effects. Empirical evidence, furthermore, confirms an important prediction of our model. Surprisingly, our model is unimaginably robust with respect to its focal parameter. We discuss the implications of our work for studies on human decision-making, and conclude by presenting a counterintuitive prediction of our model, which, if confirmed, would have intriguing implications for human decision-making under risk. To our knowledge, our model is the first metacognitive, resource-rational process model of cognitive biases in decision-making.