 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Forest Mixture Bound for Block-Free Parallel Inference
May 17, 2018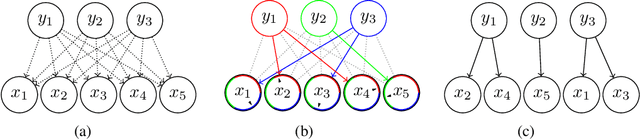
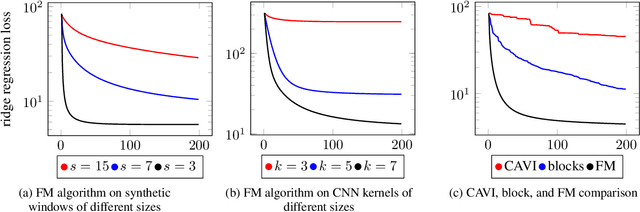
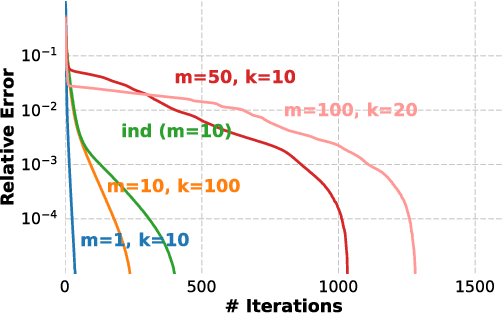
Coordinate ascent variational inference is an important algorithm for inference in probabilistic models, but it is slow because it updates only a single variable at a time. Block coordinate methods perform inference faster by updating blocks of variables in parallel. However, the speed and stability of these algorithms depends on how the variables are partitioned into blocks. In this paper, we give a stable parallel algorithm for inference in deep exponential families that doesn't require the variables to be partitioned into blocks. We achieve this by lower bounding the ELBO by a new objective we call the forest mixture bound (FM bound) that separates the inference problem for variables within a hidden layer. We apply this to the simple case when all random variables are Gaussian and show empirically that the algorithm converges faster for models that are inherently more forest-like.
Auto-Encoding Total Correlation Explanation
Feb 16, 2018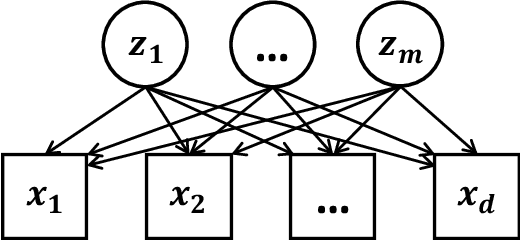
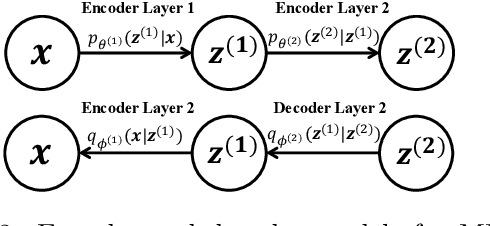

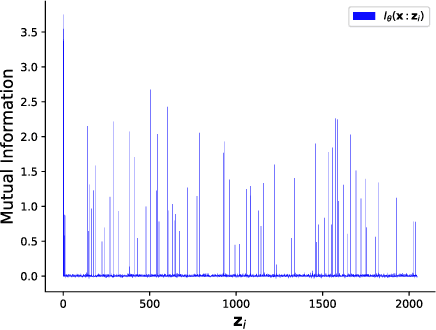
Advances in unsupervised learning enable reconstruction and generation of samples from complex distributions, but this success is marred by the inscrutability of the representations learned. We propose an information-theoretic approach to characterizing disentanglement and dependence in representation learning using multivariate mutual information, also called total correlation. The principle of total Cor-relation Ex-planation (CorEx) has motivated successful unsupervised learning applications across a variety of domains, but under some restrictive assumptions. Here we relax those restrictions by introducing a flexible variational lower bound to CorEx. Surprisingly, we find that this lower bound is equivalent to the one in variational autoencoders (VAE) under certain conditions. This information-theoretic view of VAE deepens our understanding of hierarchical VAE and motivates a new algorithm, AnchorVAE, that makes latent codes more interpretable through information maximization and enables generation of richer and more realistic samples.
Stochastic Learning of Nonstationary Kernels for Natural Language Modeling
Feb 01, 2018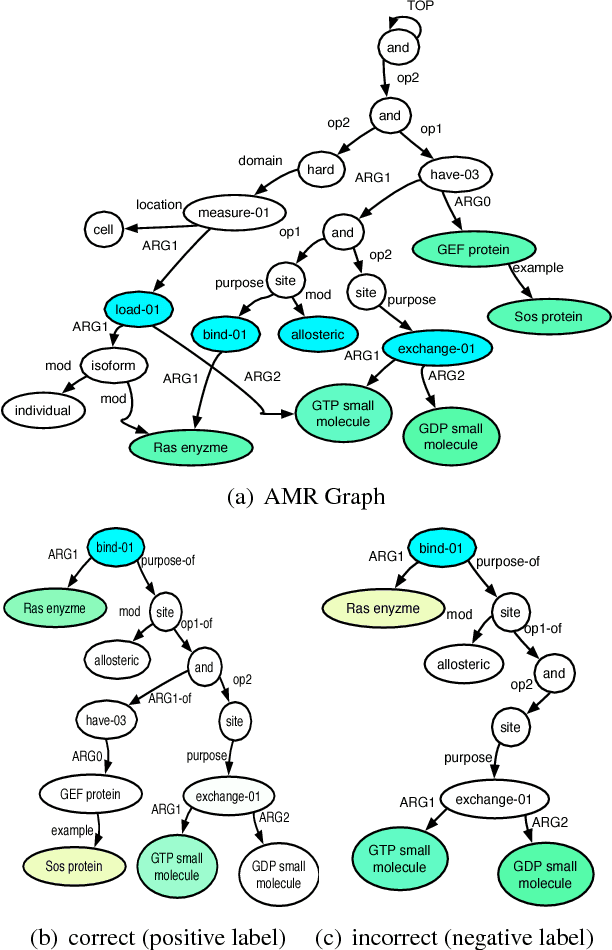
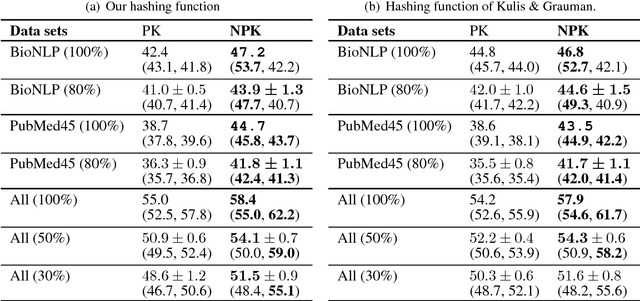
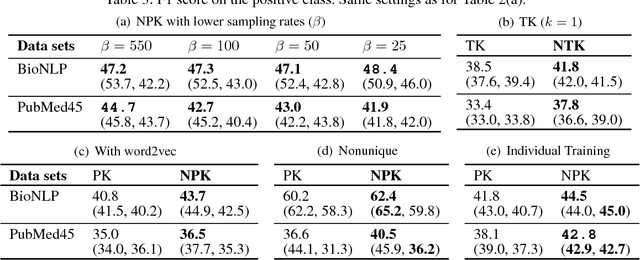
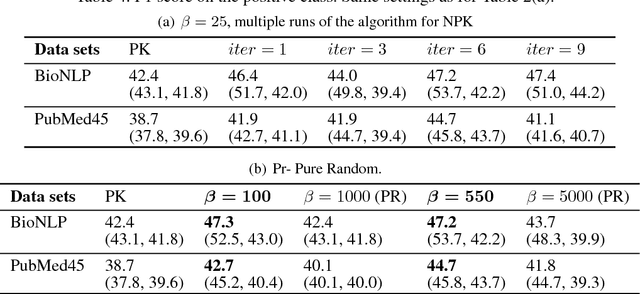
Natural language processing often involves computations with semantic or syntactic graphs to facilitate sophisticated reasoning based on structural relationships. While convolution kernels provide a powerful tool for comparing graph structure based on node (word) level relationships, they are difficult to customize and can be computationally expensive. We propose a generalization of convolution kernels, with a nonstationary model, for better expressibility of natural languages in supervised settings. For a scalable learning of the parameters introduced with our model, we propose a novel algorithm that leverages stochastic sampling on k-nearest neighbor graphs, along with approximations based on locality-sensitive hashing. We demonstrate the advantages of our approach on a challenging real-world (structured inference) problem of automatically extracting biological models from the text of scientific papers.
Low Complexity Gaussian Latent Factor Models and a Blessing of Dimensionality
Jan 19, 2018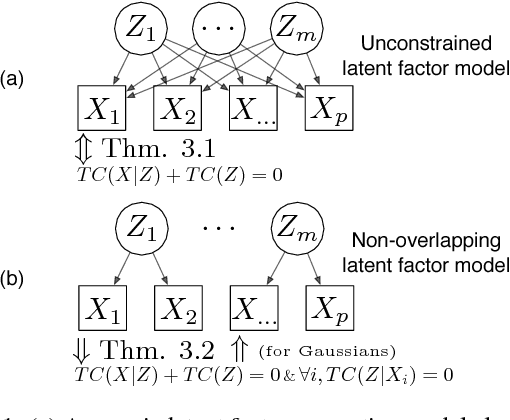
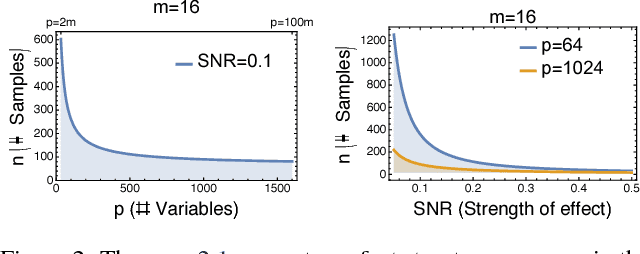
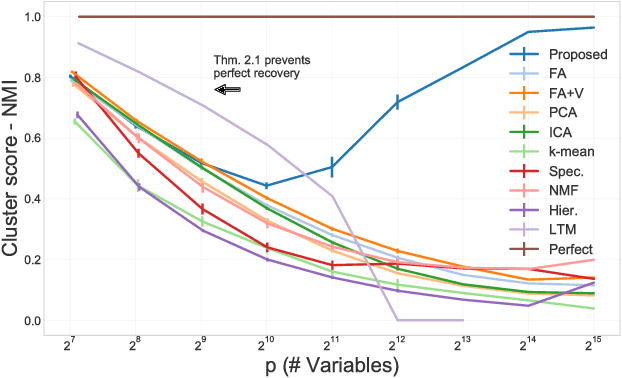
Learning the structure of graphical models from data usually incurs a heavy curse of dimensionality that renders this problem intractable in many real-world situations. The rare cases where the curse becomes a blessing provide insight into the limits of the efficiently computable and augment the scarce options for treating very under-sampled, high-dimensional data. We study a special class of Gaussian latent factor models where each (non-iid) observed variable depends on at most one of a set of latent variables. We derive information-theoretic lower bounds on the sample complexity for structure recovery that suggest complexity actually decreases as the dimensionality increases. Contrary to this prediction, we observe that existing structure recovery methods deteriorate with increasing dimension. Therefore, we design a new approach to learning Gaussian latent factor models that benefits from dimensionality. Our approach relies on an unconstrained information-theoretic objective whose global optima correspond to structured latent factor generative models. In addition to improved structure recovery, we also show that we are able to outperform state-of-the-art approaches for covariance estimation on both synthetic and real data in the very under-sampled, high-dimensional regime.
Disentangled Representations via Synergy Minimization
Oct 10, 2017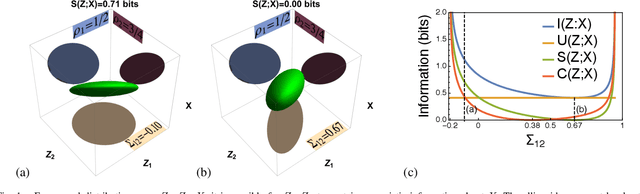

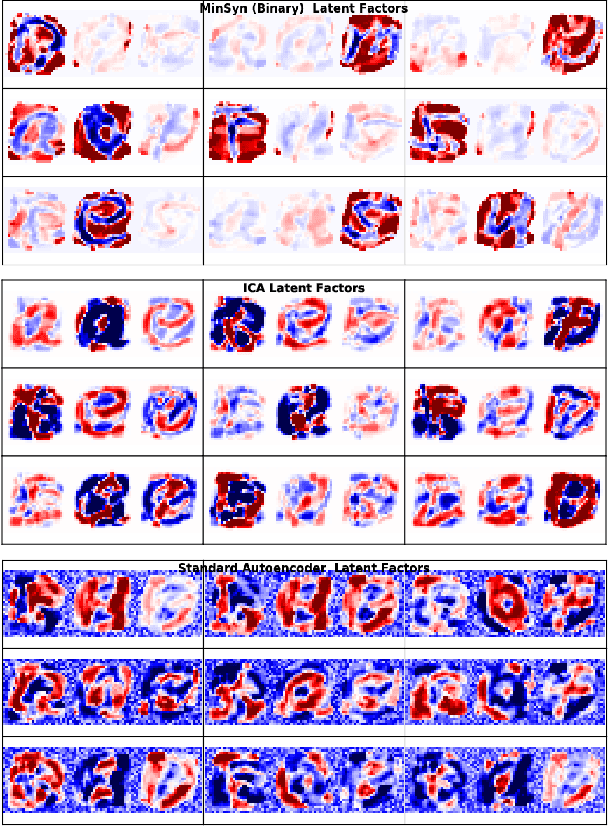

Scientists often seek simplified representations of complex systems to facilitate prediction and understanding. If the factors comprising a representation allow us to make accurate predictions about our system, but obscuring any subset of the factors destroys our ability to make predictions, we say that the representation exhibits informational synergy. We argue that synergy is an undesirable feature in learned representations and that explicitly minimizing synergy can help disentangle the true factors of variation underlying data. We explore different ways of quantifying synergy, deriving new closed-form expressions in some cases, and then show how to modify learning to produce representations that are minimally synergistic. We introduce a benchmark task to disentangle separate characters from images of words. We demonstrate that Minimally Synergistic (MinSyn) representations correctly disentangle characters while methods relying on statistical independence fail.
Unifying Local and Global Change Detection in Dynamic Networks
Oct 09, 2017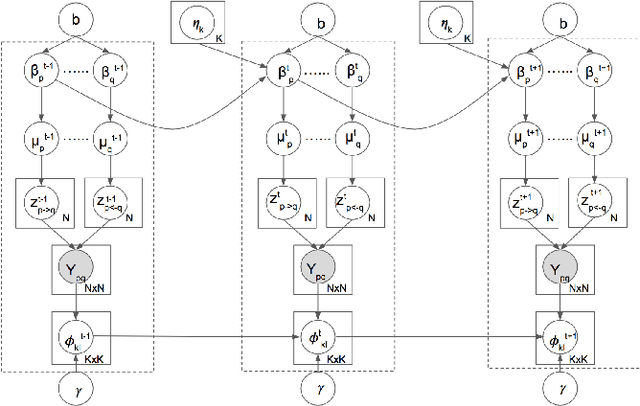
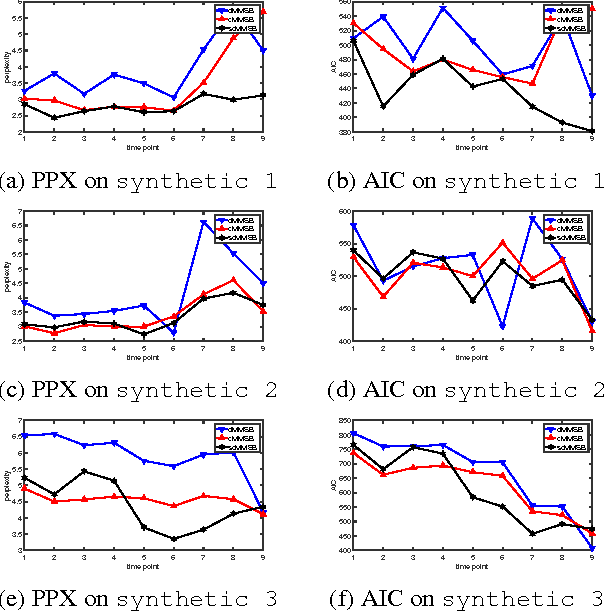


Many real-world networks are complex dynamical systems, where both local (e.g., changing node attributes) and global (e.g., changing network topology) processes unfold over time. Local dynamics may provoke global changes in the network, and the ability to detect such effects could have profound implications for a number of real-world problems. Most existing techniques focus individually on either local or global aspects of the problem or treat the two in isolation from each other. In this paper we propose a novel network model that simultaneously accounts for both local and global dynamics. To the best of our knowledge, this is the first attempt at modeling and detecting local and global change points on dynamic networks via a unified generative framework. Our model is built upon the popular mixed membership stochastic blockmodels (MMSB) with sparse co-evolving patterns. We derive an efficient stochastic gradient Langevin dynamics (SGLD) sampler for our proposed model, which allows it to scale to potentially very large networks. Finally, we validate our model on both synthetic and real-world data and demonstrate its superiority over several baselines.
Sifting Common Information from Many Variables
Jun 16, 2017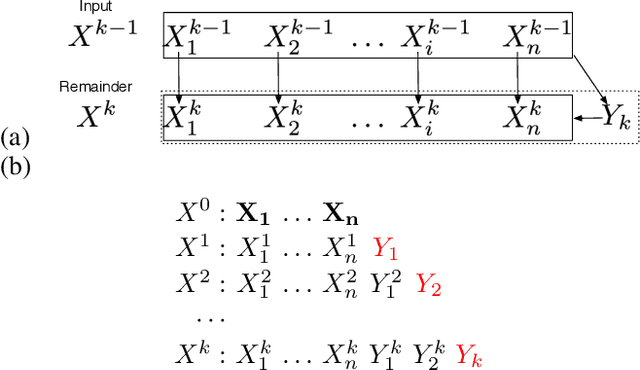
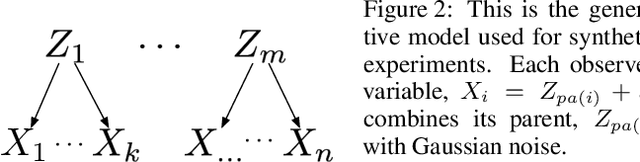
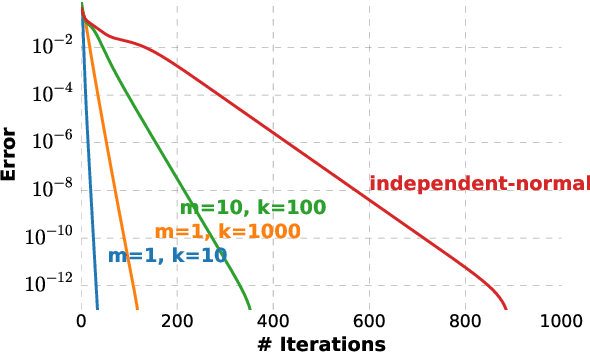
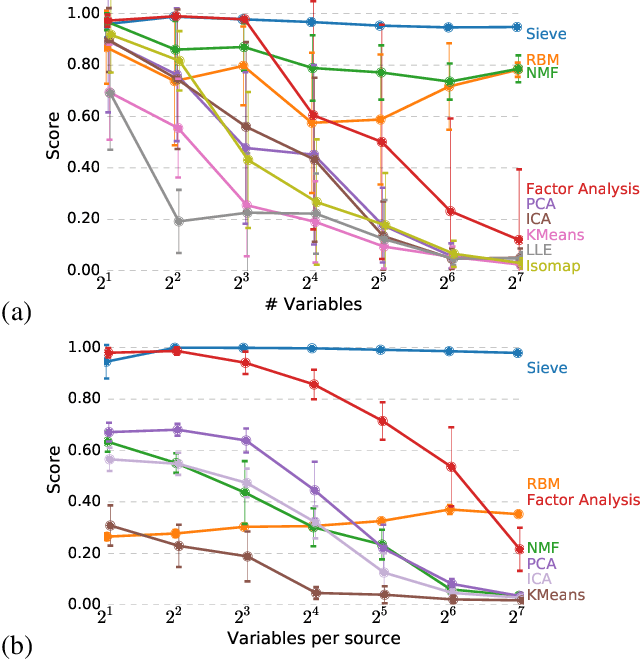
Measuring the relationship between any pair of variables is a rich and active area of research that is central to scientific practice. In contrast, characterizing the common information among any group of variables is typically a theoretical exercise with few practical methods for high-dimensional data. A promising solution would be a multivariate generalization of the famous Wyner common information, but this approach relies on solving an apparently intractable optimization problem. We leverage the recently introduced information sieve decomposition to formulate an incremental version of the common information problem that admits a simple fixed point solution, fast convergence, and complexity that is linear in the number of variables. This scalable approach allows us to demonstrate the usefulness of common information in high-dimensional learning problems. The sieve outperforms standard methods on dimensionality reduction tasks, solves a blind source separation problem that cannot be solved with ICA, and accurately recovers structure in brain imaging data.
Multitask Learning and Benchmarking with Clinical Time Series Data
Mar 22, 2017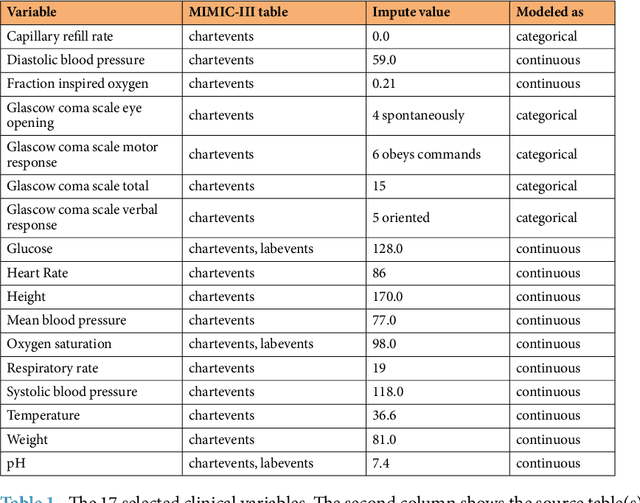
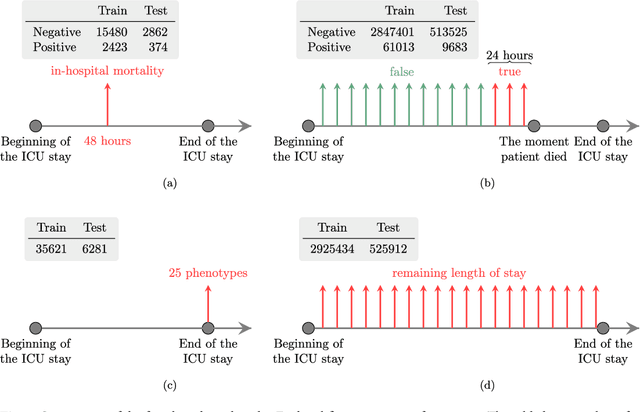
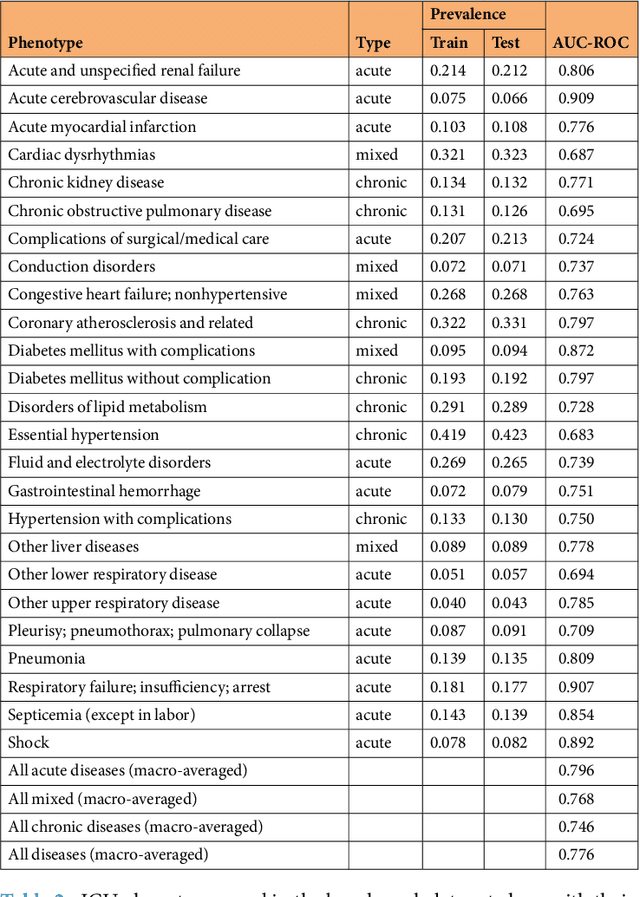
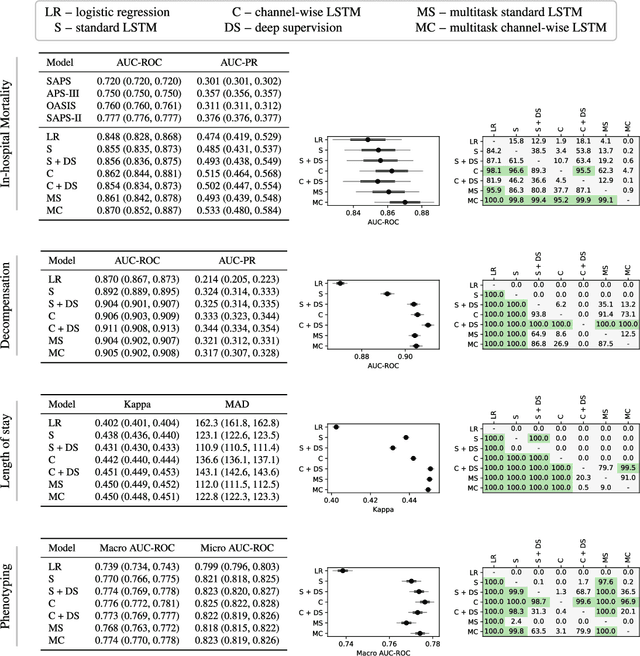
Health care is one of the most exciting frontiers in data mining and machine learning. Successful adoption of electronic health records (EHRs) created an explosion in digital clinical data available for analysis, but progress in machine learning for healthcare research has been difficult to measure because of the absence of publicly available benchmark data sets. To address this problem, we propose four clinical prediction benchmarks using data derived from the publicly available Medical Information Mart for Intensive Care (MIMIC-III) database. These tasks cover a range of clinical problems including modeling risk of mortality, forecasting length of stay, detecting physiologic decline, and phenotype classification. We formulate a heterogeneous multitask problem where the goal is to jointly learn multiple clinically relevant prediction tasks based on the same time series data. To address this problem, we propose a novel recurrent neural network (RNN) architecture that leverages the correlations between the various tasks to learn a better predictive model. We validate the proposed neural architecture on this benchmark, and demonstrate that it outperforms strong baselines, including single task RNNs.
Scalable Link Prediction in Dynamic Networks via Non-Negative Matrix Factorization
Jul 23, 2016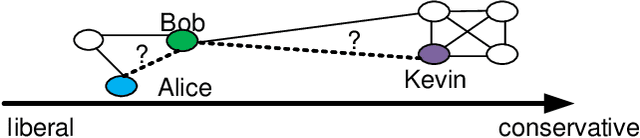

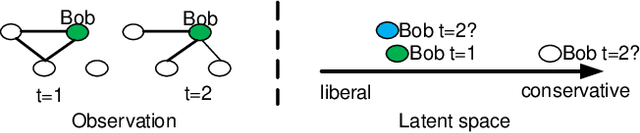
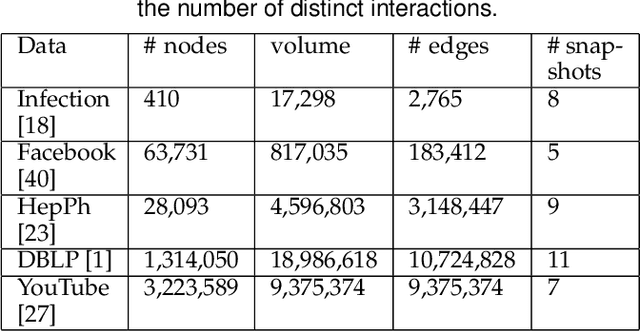
We propose a scalable temporal latent space model for link prediction in dynamic social networks, where the goal is to predict links over time based on a sequence of previous graph snapshots. The model assumes that each user lies in an unobserved latent space and interactions are more likely to form between similar users in the latent space representation. In addition, the model allows each user to gradually move its position in the latent space as the network structure evolves over time. We present a global optimization algorithm to effectively infer the temporal latent space, with a quadratic convergence rate. Two alternative optimization algorithms with local and incremental updates are also proposed, allowing the model to scale to larger networks without compromising prediction accuracy. Empirically, we demonstrate that our model, when evaluated on a number of real-world dynamic networks, significantly outperforms existing approaches for temporal link prediction in terms of both scalability and predictive power.
Toward Interpretable Topic Discovery via Anchored Correlation Explanation
Jun 22, 2016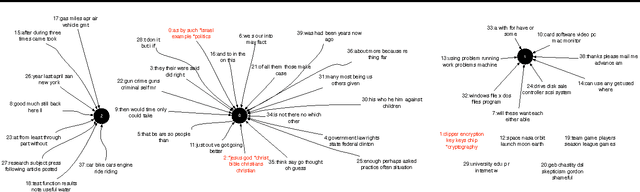
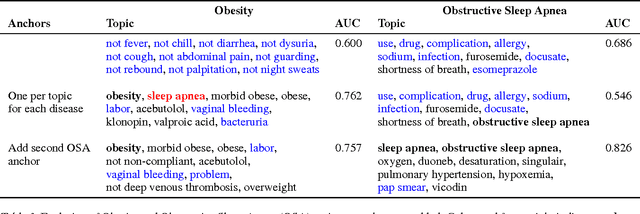


Many predictive tasks, such as diagnosing a patient based on their medical chart, are ultimately defined by the decisions of human experts. Unfortunately, encoding experts' knowledge is often time consuming and expensive. We propose a simple way to use fuzzy and informal knowledge from experts to guide discovery of interpretable latent topics in text. The underlying intuition of our approach is that latent factors should be informative about both correlations in the data and a set of relevance variables specified by an expert. Mathematically, this approach is a combination of the information bottleneck and Total Correlation Explanation (CorEx). We give a preliminary evaluation of Anchored CorEx, showing that it produces more coherent and interpretable topics on two distinct corpora.