 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmFlux: Crowd Flow Analytics with Commodity mmWave MIMO Radar
Jul 09, 2025In this paper, we present a novel framework for extracting underlying crowd motion patterns and inferring crowd semantics using mmWave radar. First, our proposed signal processing pipeline combines optical flow estimation concepts from vision with novel statistical and morphological noise filtering to generate high-fidelity mmWave flow fields - compact 2D vector representations of crowd motion. We then introduce a novel approach that transforms these fields into directed geometric graphs, where edges capture dominant flow currents, vertices mark crowd splitting or merging, and flow distribution is quantified across edges. Finally, we show that by analyzing the local Jacobian and computing the corresponding curl and divergence, we can extract key crowd semantics for both structured and diffused crowds. We conduct 21 experiments on crowds of up to (and including) 20 people across 3 areas, using commodity mmWave radar. Our framework achieves high-fidelity graph reconstruction of the underlying flow structure, even for complex crowd patterns, demonstrating strong spatial alignment and precise quantitative characterization of flow split ratios. Finally, our curl and divergence analysis accurately infers key crowd semantics, e.g., abrupt turns, boundaries where flow directions shift, dispersions, and gatherings. Overall, these findings validate our framework, underscoring its potential for various crowd analytics applications.
Embracing Diffraction: A Paradigm Shift in Wireless Sensing and Communication
May 02, 2025



Wireless signals are integral to modern society, enabling both communication and increasingly, environmental sensing. While various propagation models exist, ranging from empirical methods to full-wave simulations, the phenomenon of electromagnetic diffraction is often treated as a secondary effect or a correction factor. This paper positions diffraction as a fundamentally important and underutilized mechanism that is rich with information about the physical environment. Specifically, diffraction-inducing elements generate distinct signatures that are rich with information about their underlying properties such as their geometries. We then argue that by understanding and exploiting these relationships, diffraction can be harnessed strategically. We introduce a general optimization framework to formalize this concept, illustrating how diffraction can be leveraged for both inverse problems (sensing scene details such as object geometries from measured fields) and forward problems (shaping RF fields for communication objectives by configuring diffracting elements). Focusing primarily on edge diffraction and Keller's Geometrical Theory of Diffraction (GTD), we discuss specific applications in RF sensing for scene understanding and in communications for RF field programming, drawing upon recent work. Overall, this paper lays out a vision for systematically incorporating diffraction into the design and operation of future wireless systems, paving the way for enhanced sensing capabilities and more robust communication strategies.
mmSnap: Bayesian One-Shot Fusion in a Self-Calibrated mmWave Radar Network
May 01, 2025



We present mmSnap, a collaborative RF sensing framework using multiple radar nodes, and demonstrate its feasibility and efficacy using commercially available mmWave MIMO radars. Collaborative fusion requires network calibration, or estimates of the relative poses (positions and orientations) of the sensors. We experimentally validate a self-calibration algorithm developed in our prior work, which estimates relative poses in closed form by least squares matching of target tracks within the common field of view (FoV). We then develop and demonstrate a Bayesian framework for one-shot fusion of measurements from multiple calibrated nodes, which yields instantaneous estimates of position and velocity vectors that match smoothed estimates from multi-frame tracking. Our experiments, conducted outdoors with two radar nodes tracking a moving human target, validate the core assumptions required to develop a broader set of capabilities for networked sensing with opportunistically deployed nodes.
Crowd Size Estimation for Non-Uniform Spatial Distributions with mmWave Radar
Oct 11, 2024



Sensing with RF signals such as mmWave radar has gained considerable interest in recent years. This is particularly relevant to 6G networks, which aim to integrate sensing and communication (ISAC) capabilities for enhanced functionality. The contextual information provided by such sensing, whether collected by standalone non-ISAC units or integrated within ISAC, can not only optimize cellular network assets but can also serve as a valuable tool for a wide range of applications beyond network optimization. In this context, we present a novel methodology for crowd size estimation using monostatic mmWave radar, which is capable of accurately counting large crowds that are unevenly distributed across space. Our estimation approach relies on the rigorous derivation of occlusion probabilities, which are then used to mathematically characterize the probability distributions that describe the number of agents visible to the radar as a function of the crowd size. We then estimate the true crowd size by comparing these derived mathematical models to the empirical distribution of the number of visible agents detected by the radar. This method requires minimal sensing capabilities (e.g., angle-of-arrival information is not needed), thus being well suited for either a dedicated mmWave radar or an ISAC system. Extensive numerical simulations validate our methodology, demonstrating strong performance across diverse spatial distributions and for crowd sizes of up to (and including) 30 agents. We achieve a mean absolute error (MAE) of 0.48 agents, significantly outperforming a baseline which assumes that the agents are uniformly distributed in the area. Overall, our approach holds significant promise for a variety of applications including network resource allocation, crowd management, and urban planning.
Challenges and Thrills of Legal Arguments
Jun 06, 2020
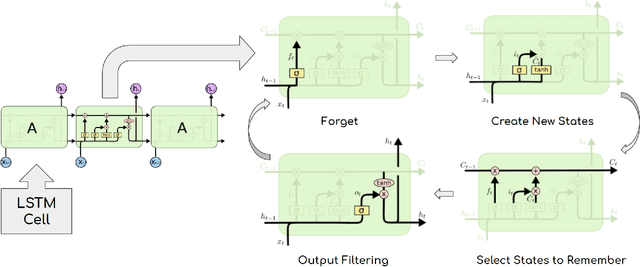
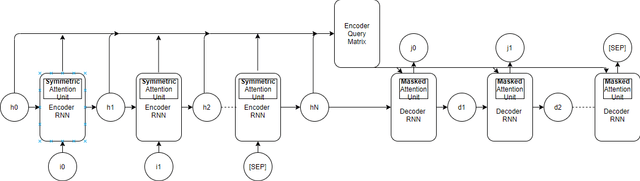
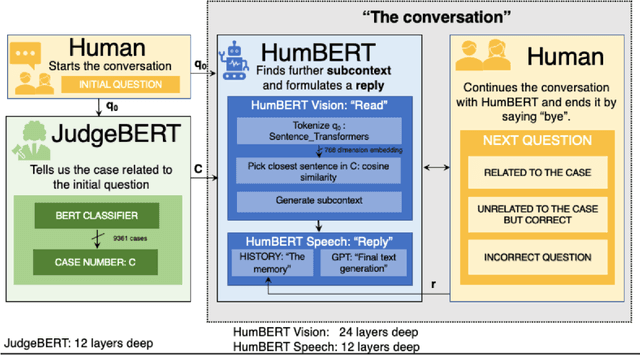
State-of-the-art attention based models, mostly centered around the transformer architecture, solve the problem of sequence-to-sequence translation using the so-called scaled dot-product attention. While this technique is highly effective for estimating inter-token attention, it does not answer the question of inter-sequence attention when we deal with conversation-like scenarios. We propose an extension, HumBERT, that attempts to perform continuous contextual argument generation using locally trained transformers.