 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking complex-valued deep neural networks for monaural speech enhancement
Jan 11, 2023



Despite multiple efforts made towards adopting complex-valued deep neural networks (DNNs), it remains an open question whether complex-valued DNNs are generally more effective than real-valued DNNs for monaural speech enhancement. This work is devoted to presenting a critical assessment by systematically examining complex-valued DNNs against their real-valued counterparts. Specifically, we investigate complex-valued DNN atomic units, including linear layers, convolutional layers, long short-term memory (LSTM), and gated linear units. By comparing complex- and real-valued versions of fundamental building blocks in the recently developed gated convolutional recurrent network (GCRN), we show how different mechanisms for basic blocks affect the performance. We also find that the use of complex-valued operations hinders the model capacity when the model size is small. In addition, we examine two recent complex-valued DNNs, i.e. deep complex convolutional recurrent network (DCCRN) and deep complex U-Net (DCUNET). Evaluation results show that both DNNs produce identical performance to their real-valued counterparts while requiring much more computation. Based on these comprehensive comparisons, we conclude that complex-valued DNNs do not provide a performance gain over their real-valued counterparts for monaural speech enhancement, and thus are less desirable due to their higher computational costs.
LA-VocE: Low-SNR Audio-visual Speech Enhancement using Neural Vocoders
Nov 20, 2022Audio-visual speech enhancement aims to extract clean speech from a noisy environment by leveraging not only the audio itself but also the target speaker's lip movements. This approach has been shown to yield improvements over audio-only speech enhancement, particularly for the removal of interfering speech. Despite recent advances in speech synthesis, most audio-visual approaches continue to use spectral mapping/masking to reproduce the clean audio, often resulting in visual backbones added to existing speech enhancement architectures. In this work, we propose LA-VocE, a new two-stage approach that predicts mel-spectrograms from noisy audio-visual speech via a transformer-based architecture, and then converts them into waveform audio using a neural vocoder (HiFi-GAN). We train and evaluate our framework on thousands of speakers and 11+ different languages, and study our model's ability to adapt to different levels of background noise and speech interference. Our experiments show that LA-VocE outperforms existing methods according to multiple metrics, particularly under very noisy scenarios.
Leveraging Heteroscedastic Uncertainty in Learning Complex Spectral Mapping for Single-channel Speech Enhancement
Nov 16, 2022



Most speech enhancement (SE) models learn a point estimate, and do not make use of uncertainty estimation in the learning process. In this paper, we show that modeling heteroscedastic uncertainty by minimizing a multivariate Gaussian negative log-likelihood (NLL) improves SE performance at no extra cost. During training, our approach augments a model learning complex spectral mapping with a temporary submodel to predict the covariance of the enhancement error at each time-frequency bin. Due to unrestricted heteroscedastic uncertainty, the covariance introduces an undersampling effect, detrimental to SE performance. To mitigate undersampling, our approach inflates the uncertainty lower bound and weights each loss component with their uncertainty, effectively compensating severely undersampled components with more penalties. Our multivariate setting reveals common covariance assumptions such as scalar and diagonal matrices. By weakening these assumptions, we show that the NLL achieves superior performance compared to popular losses including the mean squared error (MSE), mean absolute error (MAE), and scale-invariant signal-to-distortion ratio (SI-SDR).
Improving Speech Enhancement through Fine-Grained Speech Characteristics
Jul 11, 2022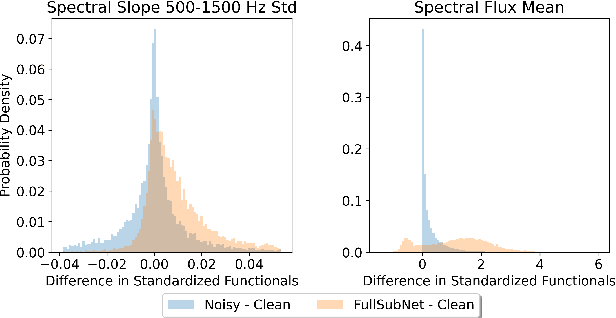
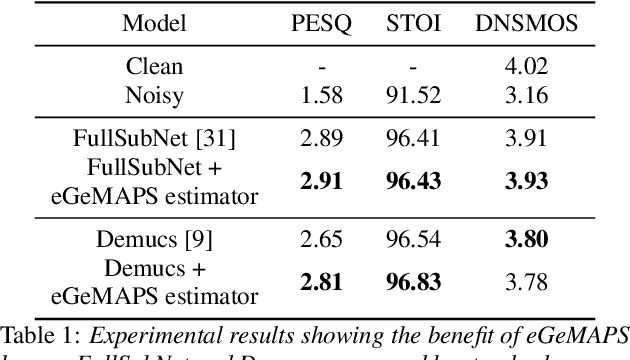
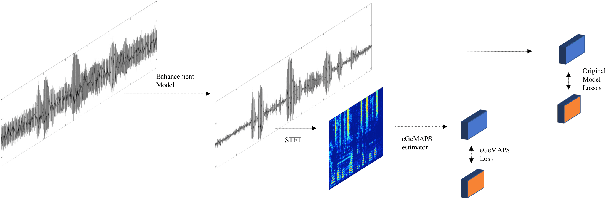
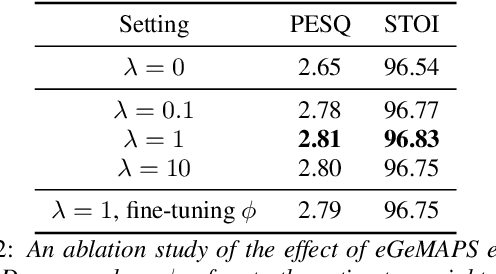
While deep learning based speech enhancement systems have made rapid progress in improving the quality of speech signals, they can still produce outputs that contain artifacts and can sound unnatural. We propose a novel approach to speech enhancement aimed at improving perceptual quality and naturalness of enhanced signals by optimizing for key characteristics of speech. We first identify key acoustic parameters that have been found to correlate well with voice quality (e.g. jitter, shimmer, and spectral flux) and then propose objective functions which are aimed at reducing the difference between clean speech and enhanced speech with respect to these features. The full set of acoustic features is the extended Geneva Acoustic Parameter Set (eGeMAPS), which includes 25 different attributes associated with perception of speech. Given the non-differentiable nature of these feature computation, we first build differentiable estimators of the eGeMAPS and then use them to fine-tune existing speech enhancement systems. Our approach is generic and can be applied to any existing deep learning based enhancement systems to further improve the enhanced speech signals. Experimental results conducted on the Deep Noise Suppression (DNS) Challenge dataset shows that our approach can improve the state-of-the-art deep learning based enhancement systems.
SAQAM: Spatial Audio Quality Assessment Metric
Jun 24, 2022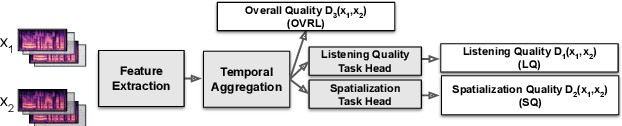

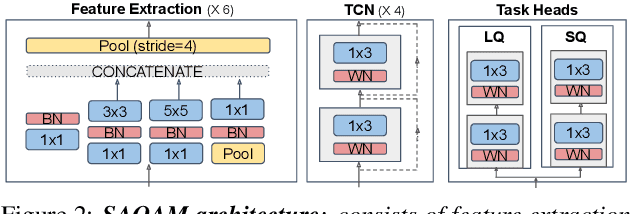

Audio quality assessment is critical for assessing the perceptual realism of sounds. However, the time and expense of obtaining ''gold standard'' human judgments limit the availability of such data. For AR&VR, good perceived sound quality and localizability of sources are among the key elements to ensure complete immersion of the user. Our work introduces SAQAM which uses a multi-task learning framework to assess listening quality (LQ) and spatialization quality (SQ) between any given pair of binaural signals without using any subjective data. We model LQ by training on a simulated dataset of triplet human judgments, and SQ by utilizing activation-level distances from networks trained for direction of arrival (DOA) estimation. We show that SAQAM correlates well with human responses across four diverse datasets. Since it is a deep network, the metric is differentiable, making it suitable as a loss function for other tasks. For example, simply replacing an existing loss with our metric yields improvement in a speech-enhancement network.
Speech Quality Assessment through MOS using Non-Matching References
Jun 24, 2022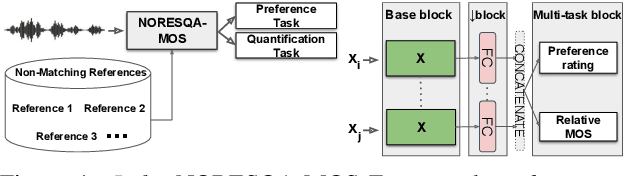
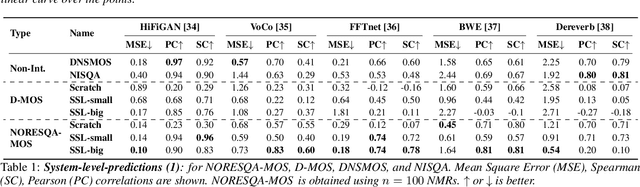
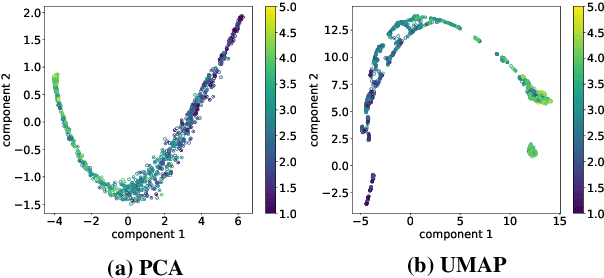
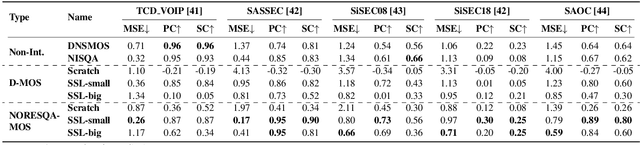
Human judgments obtained through Mean Opinion Scores (MOS) are the most reliable way to assess the quality of speech signals. However, several recent attempts to automatically estimate MOS using deep learning approaches lack robustness and generalization capabilities, limiting their use in real-world applications. In this work, we present a novel framework, NORESQA-MOS, for estimating the MOS of a speech signal. Unlike prior works, our approach uses non-matching references as a form of conditioning to ground the MOS estimation by neural networks. We show that NORESQA-MOS provides better generalization and more robust MOS estimation than previous state-of-the-art methods such as DNSMOS and NISQA, even though we use a smaller training set. Moreover, we also show that our generic framework can be combined with other learning methods such as self-supervised learning and can further supplement the benefits from these methods.
RemixIT: Continual self-training of speech enhancement models via bootstrapped remixing
Feb 22, 2022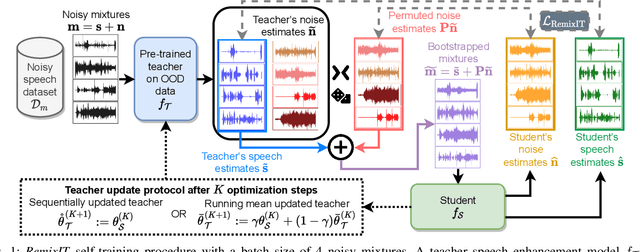
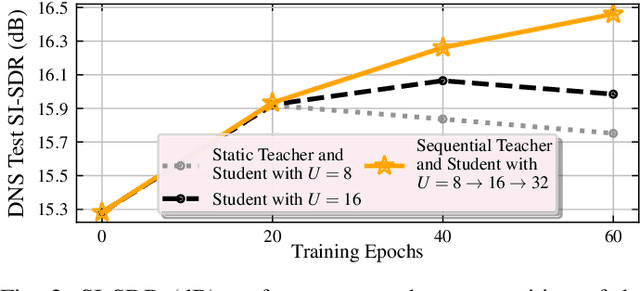
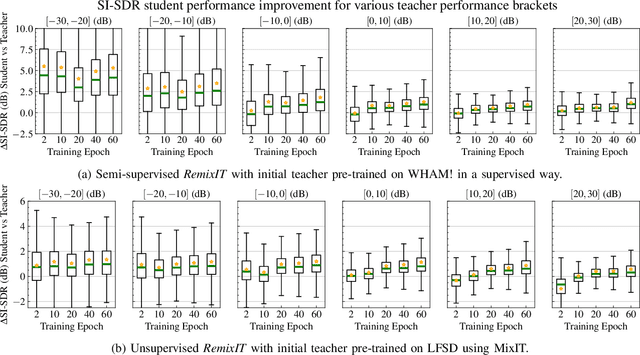
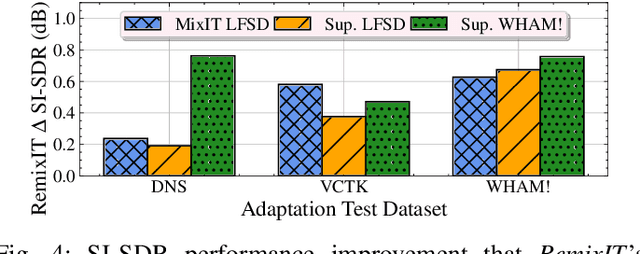
We present RemixIT, a simple yet effective self-supervised method for training speech enhancement without the need of a single isolated in-domain speech nor a noise waveform. Our approach overcomes limitations of previous methods which make them dependent on clean in-domain target signals and thus, sensitive to any domain mismatch between train and test samples. RemixIT is based on a continuous self-training scheme in which a pre-trained teacher model on out-of-domain data infers estimated pseudo-target signals for in-domain mixtures. Then, by permuting the estimated clean and noise signals and remixing them together, we generate a new set of bootstrapped mixtures and corresponding pseudo-targets which are used to train the student network. Vice-versa, the teacher periodically refines its estimates using the updated parameters of the latest student models. Experimental results on multiple speech enhancement datasets and tasks not only show the superiority of our method over prior approaches but also showcase that RemixIT can be combined with any separation model as well as be applied towards any semi-supervised and unsupervised domain adaptation task. Our analysis, paired with empirical evidence, sheds light on the inside functioning of our self-training scheme wherein the student model keeps obtaining better performance while observing severely degraded pseudo-targets.
Curriculum optimization for low-resource speech recognition
Feb 17, 2022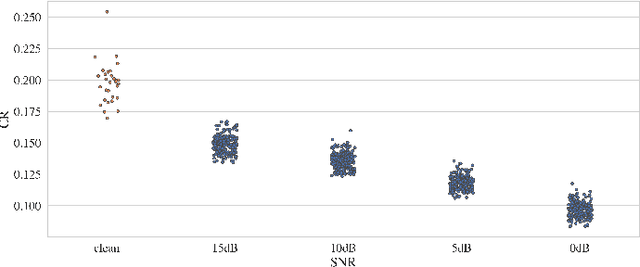
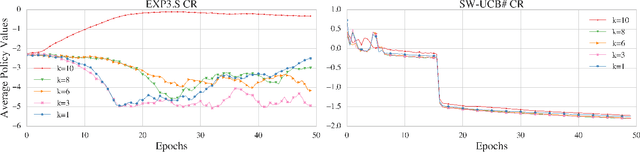
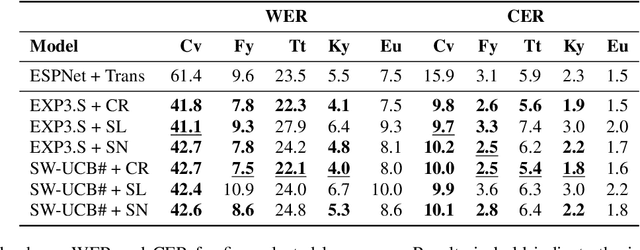
Modern end-to-end speech recognition models show astonishing results in transcribing audio signals into written text. However, conventional data feeding pipelines may be sub-optimal for low-resource speech recognition, which still remains a challenging task. We propose an automated curriculum learning approach to optimize the sequence of training examples based on both the progress of the model while training and prior knowledge about the difficulty of the training examples. We introduce a new difficulty measure called compression ratio that can be used as a scoring function for raw audio in various noise conditions. The proposed method improves speech recognition Word Error Rate performance by up to 33% relative over the baseline system
The impact of removing head movements on audio-visual speech enhancement
Feb 02, 2022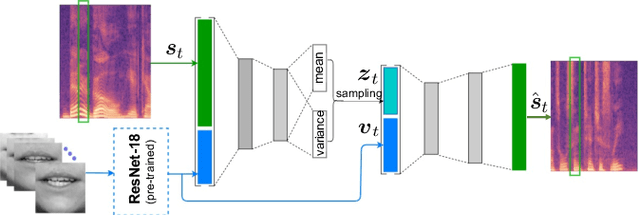
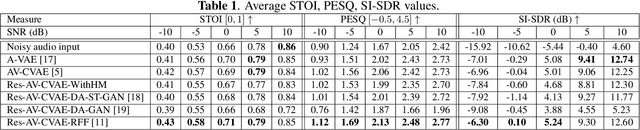
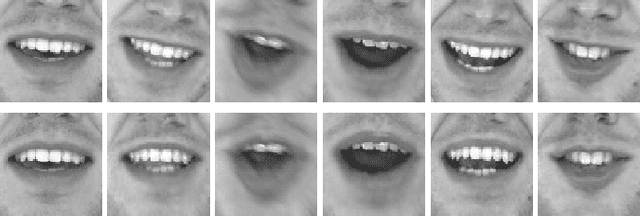
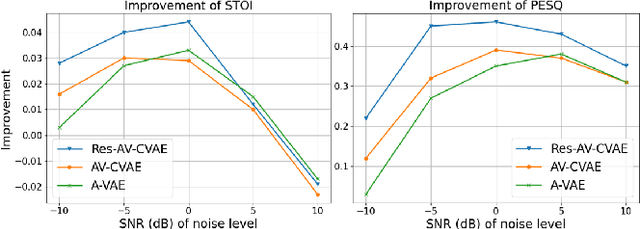
This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today's learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.
NICE-Beam: Neural Integrated Covariance Estimators for Time-Varying Beamformers
Dec 08, 2021
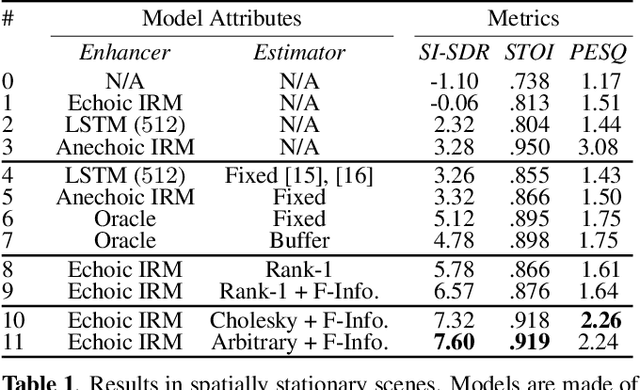
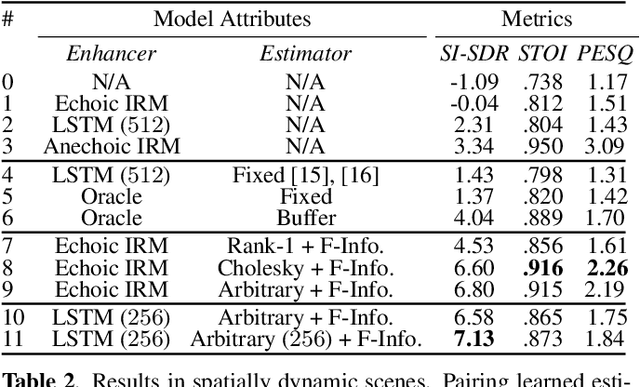

Estimating a time-varying spatial covariance matrix for a beamforming algorithm is a challenging task, especially for wearable devices, as the algorithm must compensate for time-varying signal statistics due to rapid pose-changes. In this paper, we propose Neural Integrated Covariance Estimators for Beamformers, NICE-Beam. NICE-Beam is a general technique for learning how to estimate time-varying spatial covariance matrices, which we apply to joint speech enhancement and dereverberation. It is based on training a neural network module to non-linearly track and leverage scene information across time. We integrate our solution into a beamforming pipeline, which enables simple training, faster than real-time inference, and a variety of test-time adaptation options. We evaluate the proposed model against a suite of baselines in scenes with both stationary and moving microphones. Our results show that the proposed method can outperform a hand-tuned estimator, despite the hand-tuned estimator using oracle source separation knowledge.