 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARCO: Multi-Agent Real-time Chat Orchestration
Oct 29, 2024Large language model advancements have enabled the development of multi-agent frameworks to tackle complex, real-world problems such as to automate tasks that require interactions with diverse tools, reasoning, and human collaboration. We present MARCO, a Multi-Agent Real-time Chat Orchestration framework for automating tasks using LLMs. MARCO addresses key challenges in utilizing LLMs for complex, multi-step task execution. It incorporates robust guardrails to steer LLM behavior, validate outputs, and recover from errors that stem from inconsistent output formatting, function and parameter hallucination, and lack of domain knowledge. Through extensive experiments we demonstrate MARCO's superior performance with 94.48% and 92.74% accuracy on task execution for Digital Restaurant Service Platform conversations and Retail conversations datasets respectively along with 44.91% improved latency and 33.71% cost reduction. We also report effects of guardrails in performance gain along with comparisons of various LLM models, both open-source and proprietary. The modular and generic design of MARCO allows it to be adapted for automating tasks across domains and to execute complex usecases through multi-turn interactions.
NER-MQMRC: Formulating Named Entity Recognition as Multi Question Machine Reading Comprehension
May 12, 2022
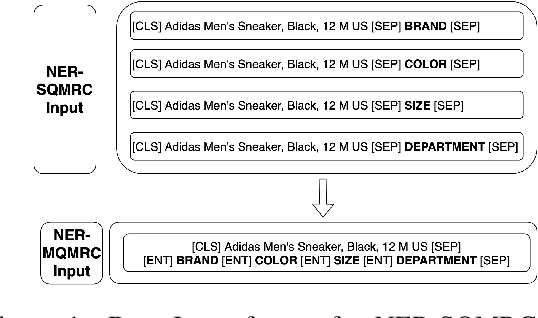
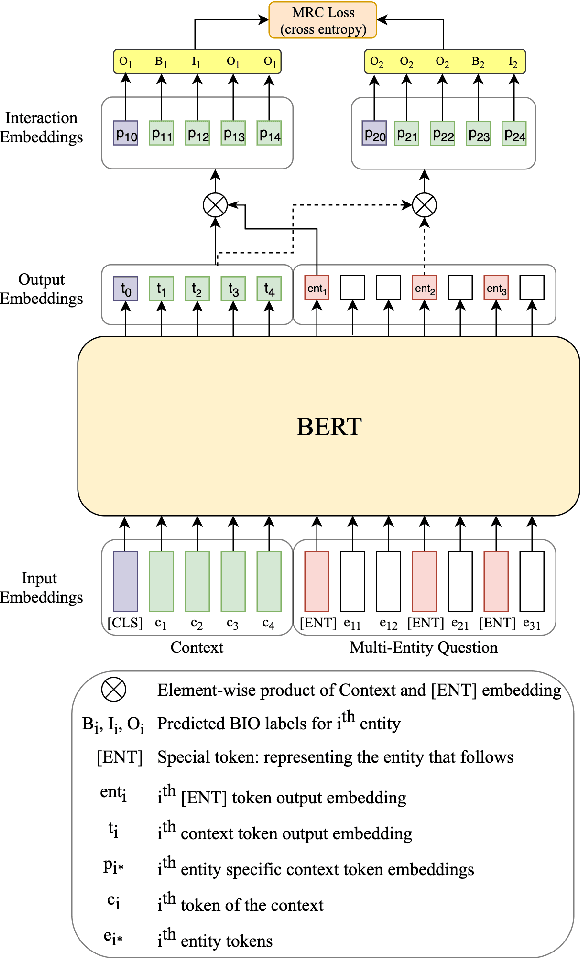
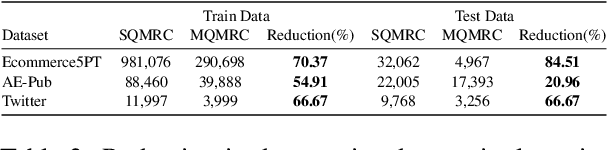
NER has been traditionally formulated as a sequence labeling task. However, there has been recent trend in posing NER as a machine reading comprehension task (Wang et al., 2020; Mengge et al., 2020), where entity name (or other information) is considered as a question, text as the context and entity value in text as answer snippet. These works consider MRC based on a single question (entity) at a time. We propose posing NER as a multi-question MRC task, where multiple questions (one question per entity) are considered at the same time for a single text. We propose a novel BERT-based multi-question MRC (NER-MQMRC) architecture for this formulation. NER-MQMRC architecture considers all entities as input to BERT for learning token embeddings with self-attention and leverages BERT-based entity representation for further improving these token embeddings for NER task. Evaluation on three NER datasets show that our proposed architecture leads to average 2.5 times faster training and 2.3 times faster inference as compared to NER-SQMRC framework based models by considering all entities together in a single pass. Further, we show that our model performance does not degrade compared to single-question based MRC (NER-SQMRC) (Devlin et al., 2019) leading to F1 gain of +0.41%, +0.32% and +0.27% for AE-Pub, Ecommerce5PT and Twitter datasets respectively. We propose this architecture primarily to solve large scale e-commerce attribute (or entity) extraction from unstructured text of a magnitude of 50k+ attributes to be extracted on a scalable production environment with high performance and optimised training and inference runtimes.
Discovering Emotion and Reasoning its Flip in Multi-Party Conversations using Masked Memory Network and Transformer
Mar 24, 2021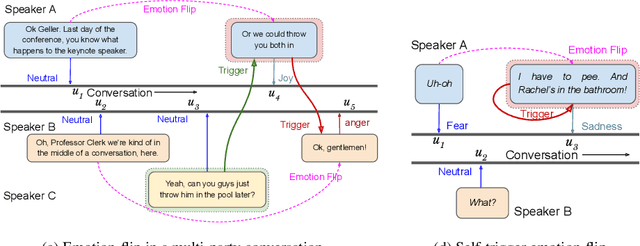
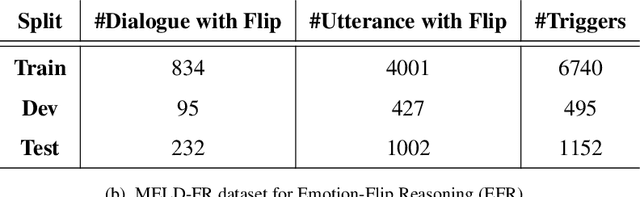
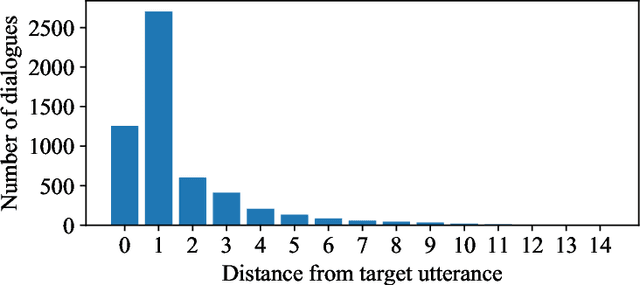
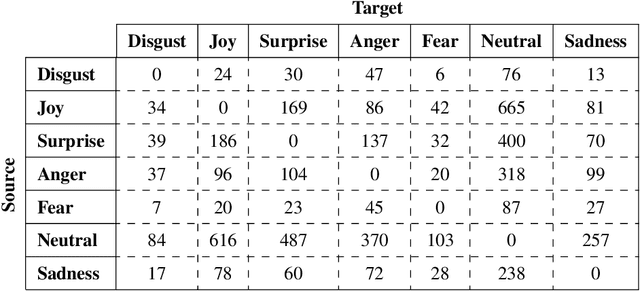
Efficient discovery of emotion states of speakers in a multi-party conversation is highly important to design human-like conversational agents. During the conversation, the cognitive state of a speaker often alters due to certain past utterances, which may lead to a flip in her emotion state. Therefore, discovering the reasons (triggers) behind one's emotion flip during conversation is important to explain the emotion labels of individual utterances. In this paper, along with addressing the task of emotion recognition in conversations (ERC), we introduce a novel task -- Emotion Flip Reasoning (EFR) that aims to identify past utterances which have triggered one's emotion state to flip at a certain time. We propose a masked memory network to address the former and a Transformer-based network for the latter task. To this end, we consider MELD, a benchmark emotion recognition dataset in multi-party conversations for the task of ERC and augment it with new ground-truth labels for EFR. An extensive comparison with four state-of-the-art models suggests improved performances of our models for both the tasks. We further present anecdotal evidences and both qualitative and quantitative error analyses to support the superiority of our models compared to the baselines.
Attention Beam: An Image Captioning Approach
Nov 11, 2020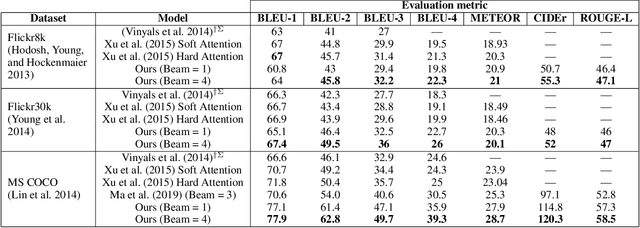
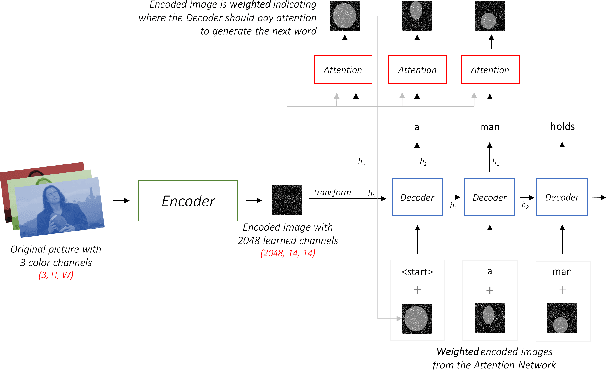
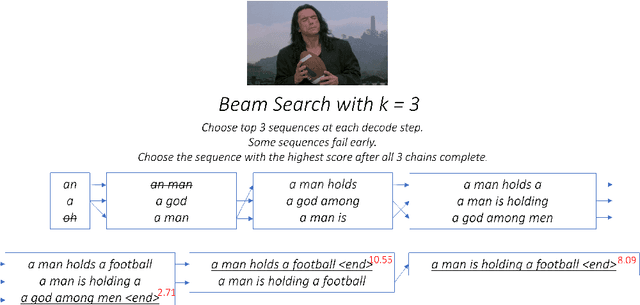
The aim of image captioning is to generate textual description of a given image. Though seemingly an easy task for humans, it is challenging for machines as it requires the ability to comprehend the image (computer vision) and consequently generate a human-like description for the image (natural language understanding). In recent times, encoder-decoder based architectures have achieved state-of-the-art results for image captioning. Here, we present a heuristic of beam search on top of the encoder-decoder based architecture that gives better quality captions on three benchmark datasets: Flickr8k, Flickr30k and MS COCO.