 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPE: Temporal Attention-based Probabilistic human pose and shape Estimation
Apr 29, 2023Reconstructing 3D human pose and shape from monocular videos is a well-studied but challenging problem. Common challenges include occlusions, the inherent ambiguities in the 2D to 3D mapping and the computational complexity of video processing. Existing methods ignore the ambiguities of the reconstruction and provide a single deterministic estimate for the 3D pose. In order to address these issues, we present a Temporal Attention based Probabilistic human pose and shape Estimation method (TAPE) that operates on an RGB video. More specifically, we propose to use a neural network to encode video frames to temporal features using an attention-based neural network. Given these features, we output a per-frame but temporally-informed probability distribution for the human pose using Normalizing Flows. We show that TAPE outperforms state-of-the-art methods in standard benchmarks and serves as an effective video-based prior for optimization-based human pose and shape estimation. Code is available at: https: //github.com/nikosvasilik/TAPE
Graphing the Future: Activity and Next Active Object Prediction using Graph-based Activity Representations
Sep 12, 2022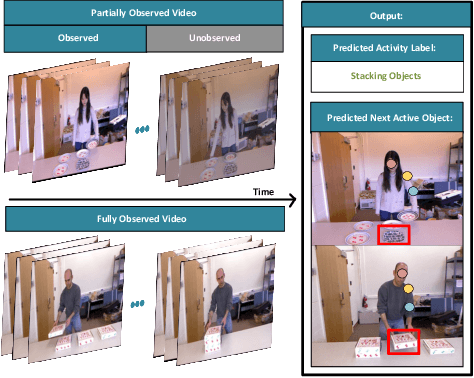

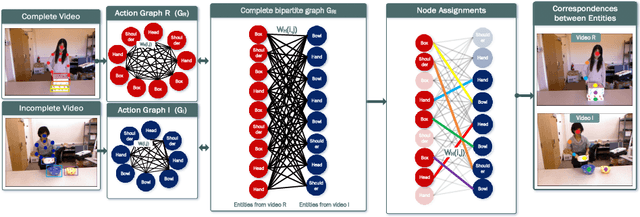
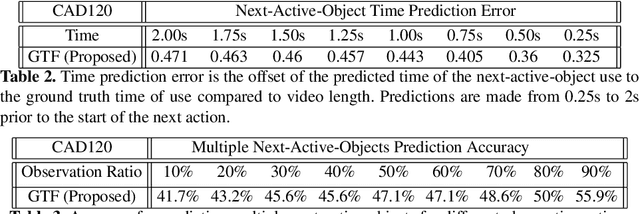
We present a novel approach for the visual prediction of human-object interactions in videos. Rather than forecasting the human and object motion or the future hand-object contact points, we aim at predicting (a)the class of the on-going human-object interaction and (b) the class(es) of the next active object(s) (NAOs), i.e., the object(s) that will be involved in the interaction in the near future as well as the time the interaction will occur. Graph matching relies on the efficient Graph Edit distance (GED) method. The experimental evaluation of the proposed approach was conducted using two well-established video datasets that contain human-object interactions, namely the MSR Daily Activities and the CAD120. High prediction accuracy was obtained for both action prediction and NAO forecasting.
Detecting Object States vs Detecting Objects: A New Dataset and a Quantitative Experimental Study
Dec 15, 2021
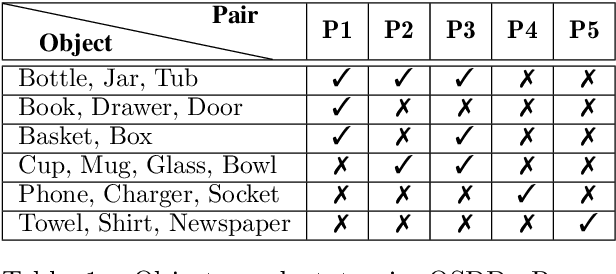

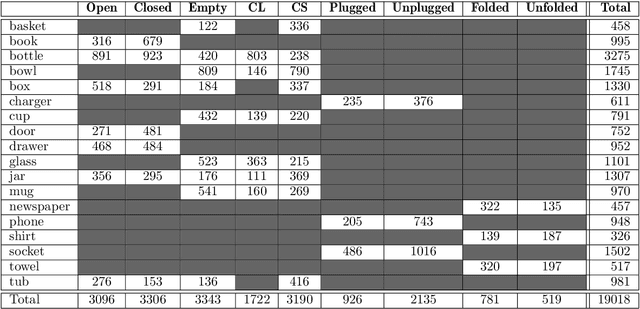
The detection of object states in images (State Detection - SD) is a problem of both theoretical and practical importance and it is tightly interwoven with other important computer vision problems, such as action recognition and affordance detection. It is also highly relevant to any entity that needs to reason and act in dynamic domains, such as robotic systems and intelligent agents. Despite its importance, up to now, the research on this problem has been limited. In this paper, we attempt a systematic study of the SD problem. First, we introduce the Object State Detection Dataset (OSDD), a new publicly available dataset consisting of more than 19,000 annotations for 18 object categories and 9 state classes. Second, using a standard deep learning framework used for Object Detection (OD), we conduct a number of appropriately designed experiments, towards an in-depth study of the behavior of the SD problem. This study enables the setup of a baseline on the performance of SD, as well as its relative performance in comparison to OD, in a variety of scenarios. Overall, the experimental outcomes confirm that SD is harder than OD and that tailored SD methods need to be developed for addressing effectively this significant problem.
PE-former: Pose Estimation Transformer
Dec 09, 2021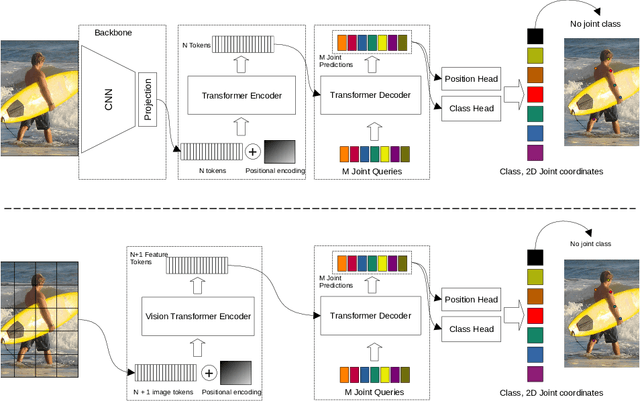
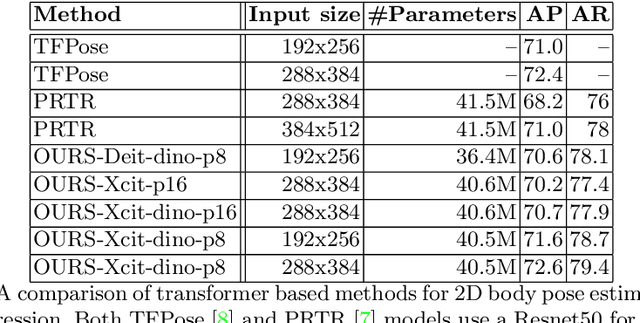
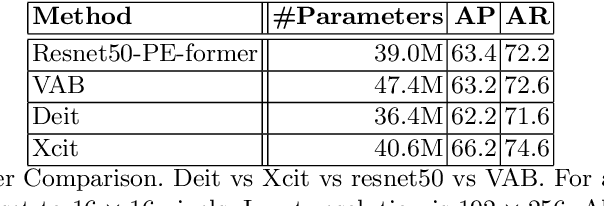
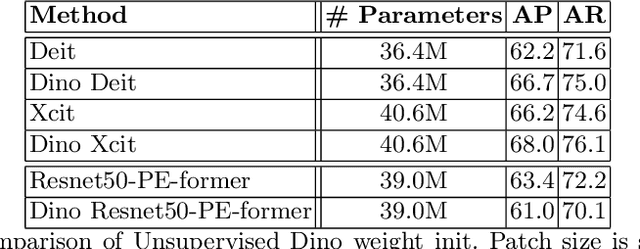
Vision transformer architectures have been demonstrated to work very effectively for image classification tasks. Efforts to solve more challenging vision tasks with transformers rely on convolutional backbones for feature extraction. In this paper we investigate the use of a pure transformer architecture (i.e., one with no CNN backbone) for the problem of 2D body pose estimation. We evaluate two ViT architectures on the COCO dataset. We demonstrate that using an encoder-decoder transformer architecture yields state of the art results on this estimation problem.
Even Faster SNN Simulation with Lazy+Event-driven Plasticity and Shared Atomics
Jul 08, 2021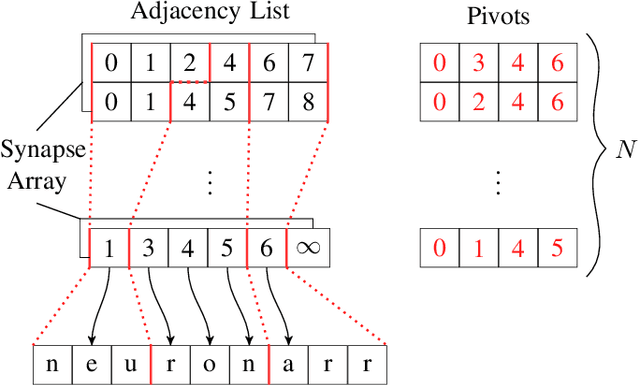


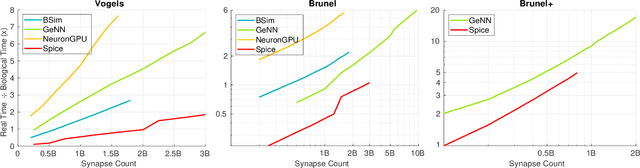
We present two novel optimizations that accelerate clock-based spiking neural network (SNN) simulators. The first one targets spike timing dependent plasticity (STDP). It combines lazy- with event-driven plasticity and efficiently facilitates the computation of pre- and post-synaptic spikes using bitfields and integer intrinsics. It offers higher bandwidth than event-driven plasticity alone and achieves a 1.5x-2x speedup over our closest competitor. The second optimization targets spike delivery. We partition our graph representation in a way that bounds the number of neurons that need be updated at any given time which allows us to perform said update in shared memory instead of global memory. This is 2x-2.5x faster than our closest competitor. Both optimizations represent the final evolutionary stages of years of iteration on STDP and spike delivery inside "Spice" (/spaIk/), our state of the art SNN simulator. The proposed optimizations are not exclusive to our graph representation or pipeline but are applicable to a multitude of simulator designs. We evaluate our performance on three well-established models and compare ourselves against three other state of the art simulators.
H-GAN: the power of GANs in your Hands
Apr 21, 2021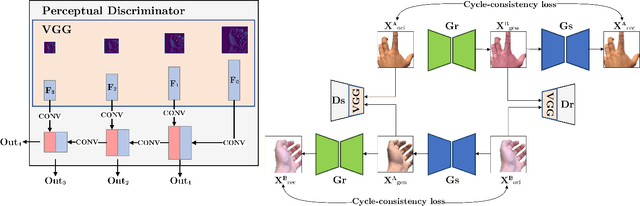
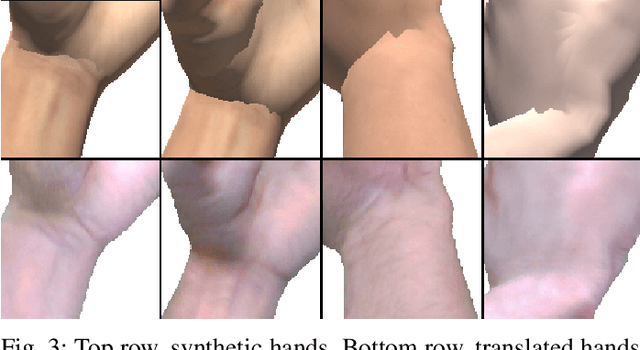
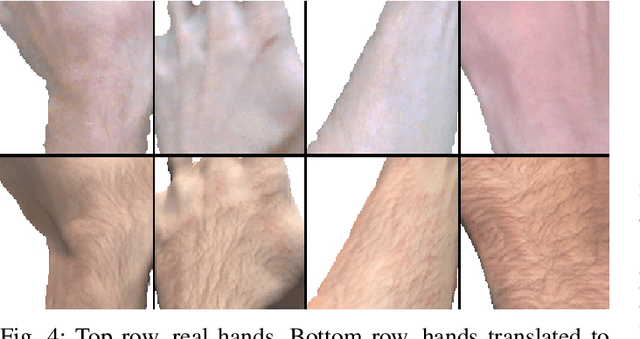
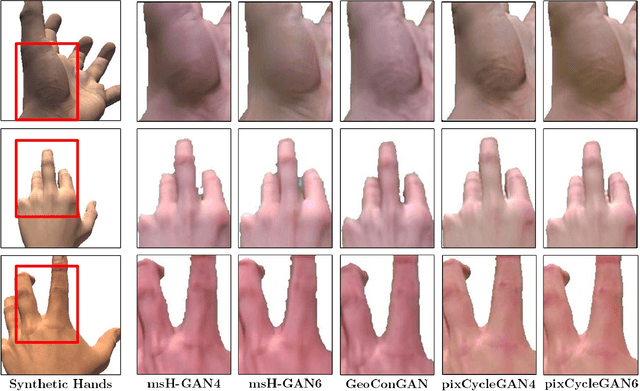
We present HandGAN (H-GAN), a cycle-consistent adversarial learning approach implementing multi-scale perceptual discriminators. It is designed to translate synthetic images of hands to the real domain. Synthetic hands provide complete ground-truth annotations, yet they are not representative of the target distribution of real-world data. We strive to provide the perfect blend of a realistic hand appearance with synthetic annotations. Relying on image-to-image translation, we improve the appearance of synthetic hands to approximate the statistical distribution underlying a collection of real images of hands. H-GAN tackles not only the cross-domain tone mapping but also structural differences in localized areas such as shading discontinuities. Results are evaluated on a qualitative and quantitative basis improving previous works. Furthermore, we relied on the hand classification task to claim our generated hands are statistically similar to the real domain of hands.
Multi-GPU SNN Simulation with Perfect Static Load Balancing
Feb 09, 2021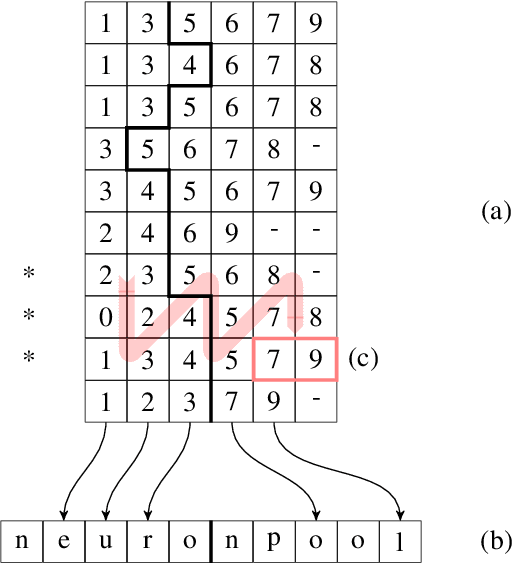
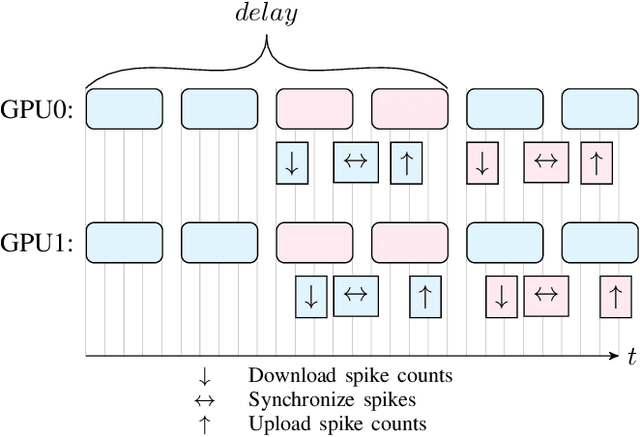
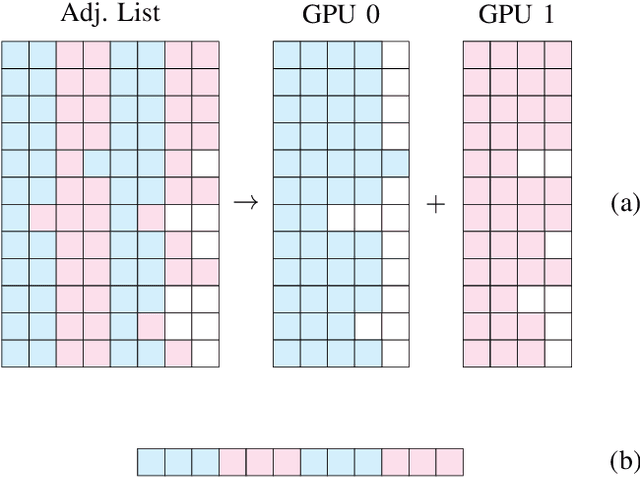
We present a SNN simulator which scales to millions of neurons, billions of synapses, and 8 GPUs. This is made possible by 1) a novel, cache-aware spike transmission algorithm 2) a model parallel multi-GPU distribution scheme and 3) a static, yet very effective load balancing strategy. The simulator further features an easy to use API and the ability to create custom models. We compare the proposed simulator against two state of the art ones on a series of benchmarks using three well-established models. We find that our simulator is faster, consumes less memory, and scales linearly with the number of GPUs.
A Review on Deep Learning Techniques for Video Prediction
Apr 15, 2020
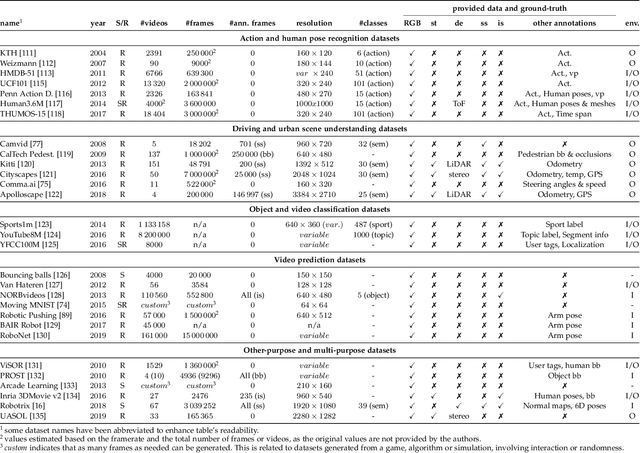
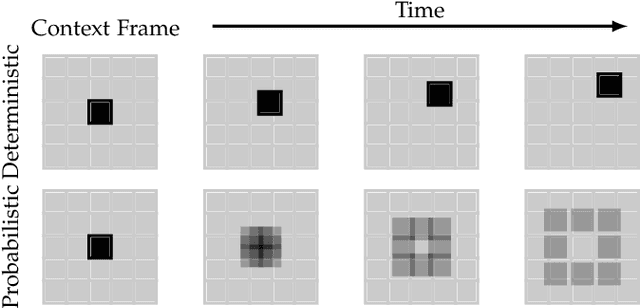
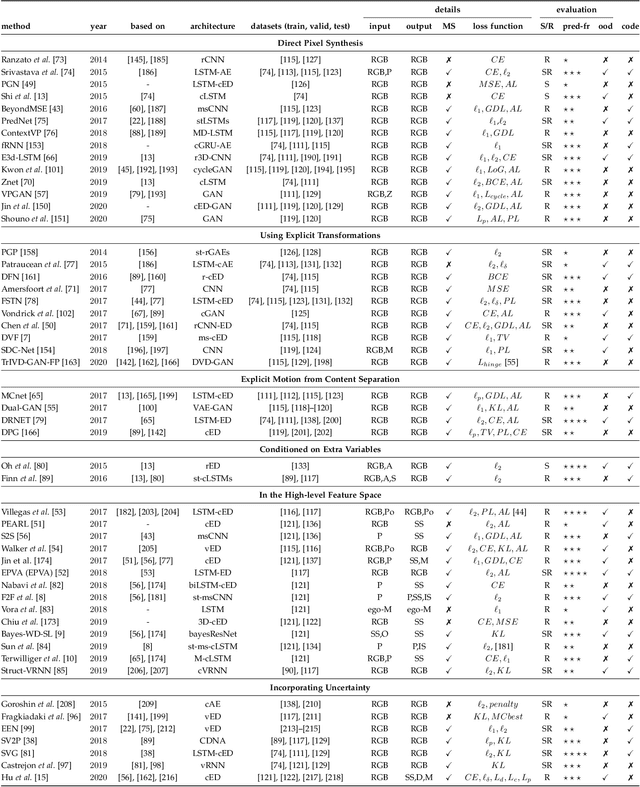
The ability to predict, anticipate and reason about future outcomes is a key component of intelligent decision-making systems. In light of the success of deep learning in computer vision, deep-learning-based video prediction emerged as a promising research direction. Defined as a self-supervised learning task, video prediction represents a suitable framework for representation learning, as it demonstrated potential capabilities for extracting meaningful representations of the underlying patterns in natural videos. Motivated by the increasing interest in this task, we provide a review on the deep learning methods for prediction in video sequences. We firstly define the video prediction fundamentals, as well as mandatory background concepts and the most used datasets. Next, we carefully analyze existing video prediction models organized according to a proposed taxonomy, highlighting their contributions and their significance in the field. The summary of the datasets and methods is accompanied with experimental results that facilitate the assessment of the state of the art on a quantitative basis. The paper is summarized by drawing some general conclusions, identifying open research challenges and by pointing out future research directions.
A Review on Intelligent Object Perception Methods Combining Knowledge-based Reasoning and Machine Learning
Dec 26, 2019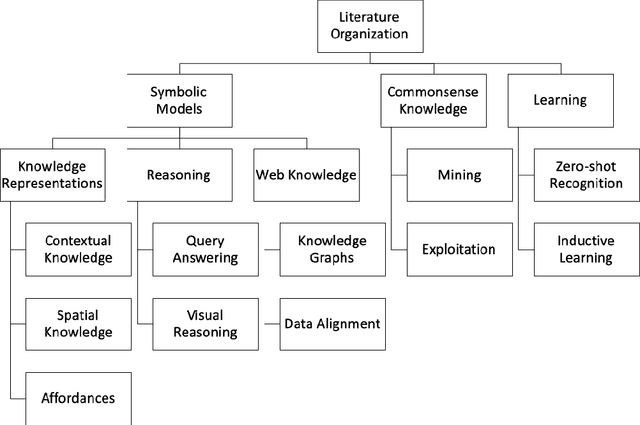
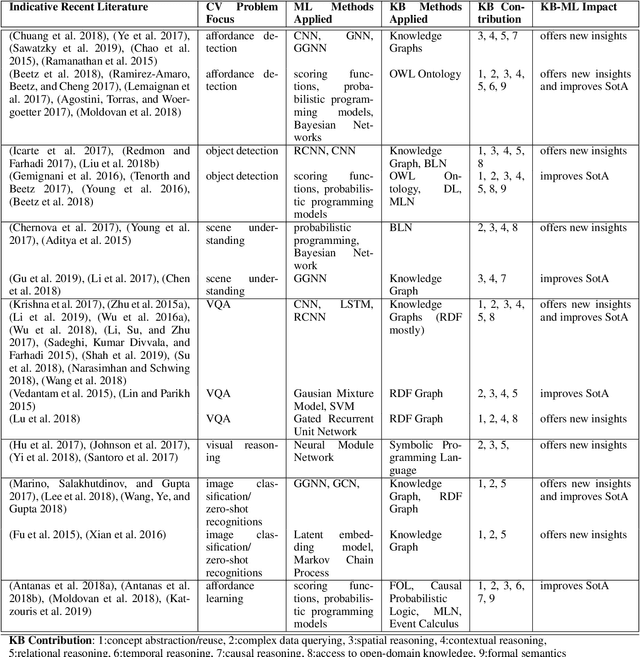
Object perception is a fundamental sub-field of Computer Vision, covering a multitude of individual areas and having contributed high-impact results. While Machine Learning has been traditionally applied to address related problems, recent works also seek ways to integrate knowledge engineering in order to expand the level of intelligence of the visual interpretation of objects, their properties and their relations with their environment. In this paper, we attempt a systematic investigation of how knowledge-based methods contribute to diverse object perception tasks. We review the latest achievements and identify prominent research directions.
Faster and Simpler SNN Simulation with Work Queues
Dec 17, 2019



We present a clock-driven Spiking Neural Network simulator which is up to 3x faster than the state of the art while, at the same time, being more general and requiring less programming effort on both the user's and maintainer's side. This is made possible by designing our pipeline around "work queues" which act as interfaces between stages and greatly reduce implementation complexity. We evaluate our work using three well-established SNN models on a series of benchmarks.