 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Geography: Mapping Language Data to Language Users
Dec 07, 2021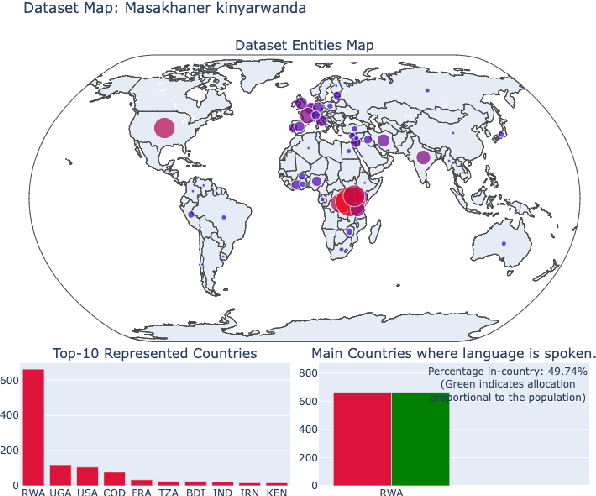
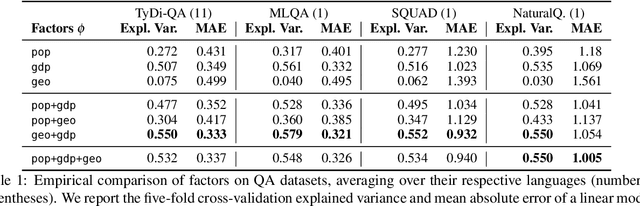
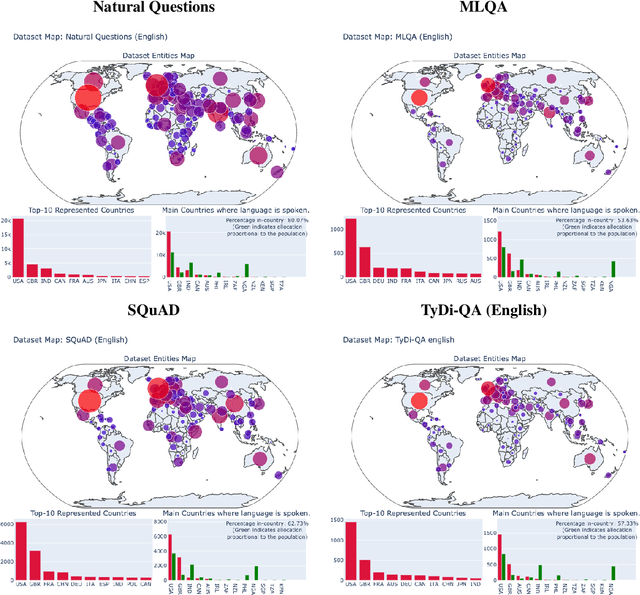
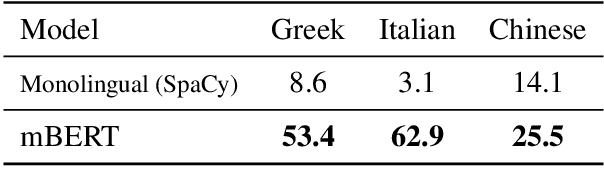
As language technologies become more ubiquitous, there are increasing efforts towards expanding the language diversity and coverage of natural language processing (NLP) systems. Arguably, the most important factor influencing the quality of modern NLP systems is data availability. In this work, we study the geographical representativeness of NLP datasets, aiming to quantify if and by how much do NLP datasets match the expected needs of the language speakers. In doing so, we use entity recognition and linking systems, also making important observations about their cross-lingual consistency and giving suggestions for more robust evaluation. Last, we explore some geographical and economic factors that may explain the observed dataset distributions. Code and data are available here: https://github.com/ffaisal93/dataset_geography. Additional visualizations are available here: https://nlp.cs.gmu.edu/project/datasetmaps/.
Lexically Aware Semi-Supervised Learning for OCR Post-Correction
Nov 04, 2021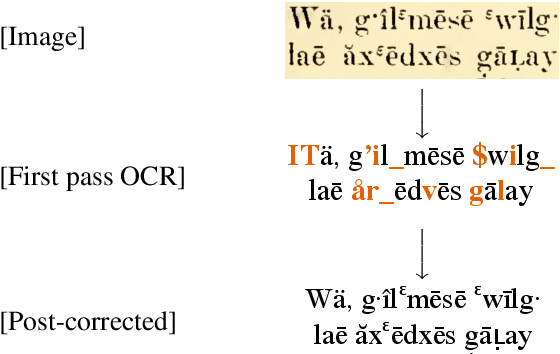
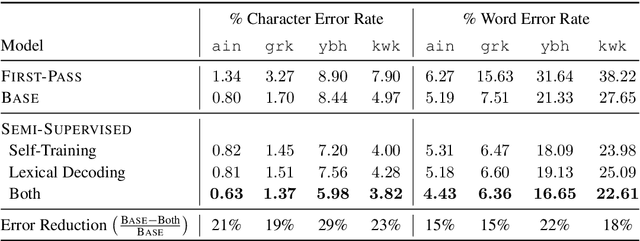
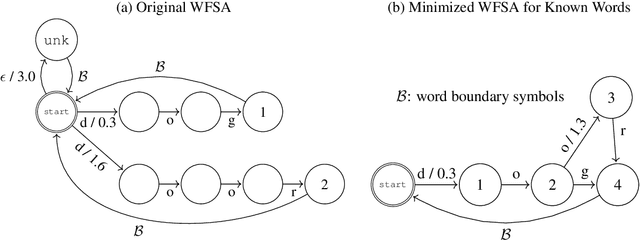
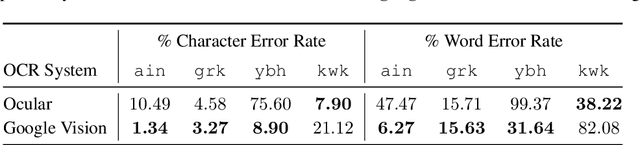
Much of the existing linguistic data in many languages of the world is locked away in non-digitized books and documents. Optical character recognition (OCR) can be used to produce digitized text, and previous work has demonstrated the utility of neural post-correction methods that improve the results of general-purpose OCR systems on recognition of less-well-resourced languages. However, these methods rely on manually curated post-correction data, which are relatively scarce compared to the non-annotated raw images that need to be digitized. In this paper, we present a semi-supervised learning method that makes it possible to utilize these raw images to improve performance, specifically through the use of self-training, a technique where a model is iteratively trained on its own outputs. In addition, to enforce consistency in the recognized vocabulary, we introduce a lexically-aware decoding method that augments the neural post-correction model with a count-based language model constructed from the recognized texts, implemented using weighted finite-state automata (WFSA) for efficient and effective decoding. Results on four endangered languages demonstrate the utility of the proposed method, with relative error reductions of 15-29%, where we find the combination of self-training and lexically-aware decoding essential for achieving consistent improvements. Data and code are available at https://shrutirij.github.io/ocr-el/.
Systematic Inequalities in Language Technology Performance across the World's Languages
Oct 13, 2021
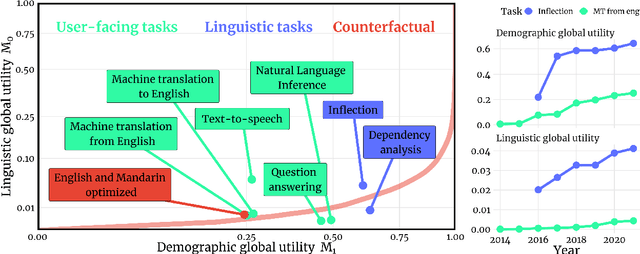
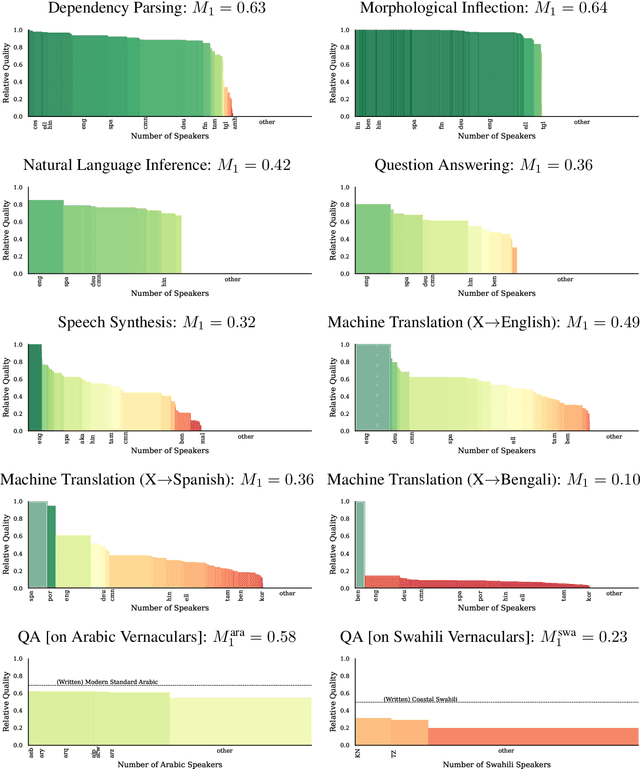
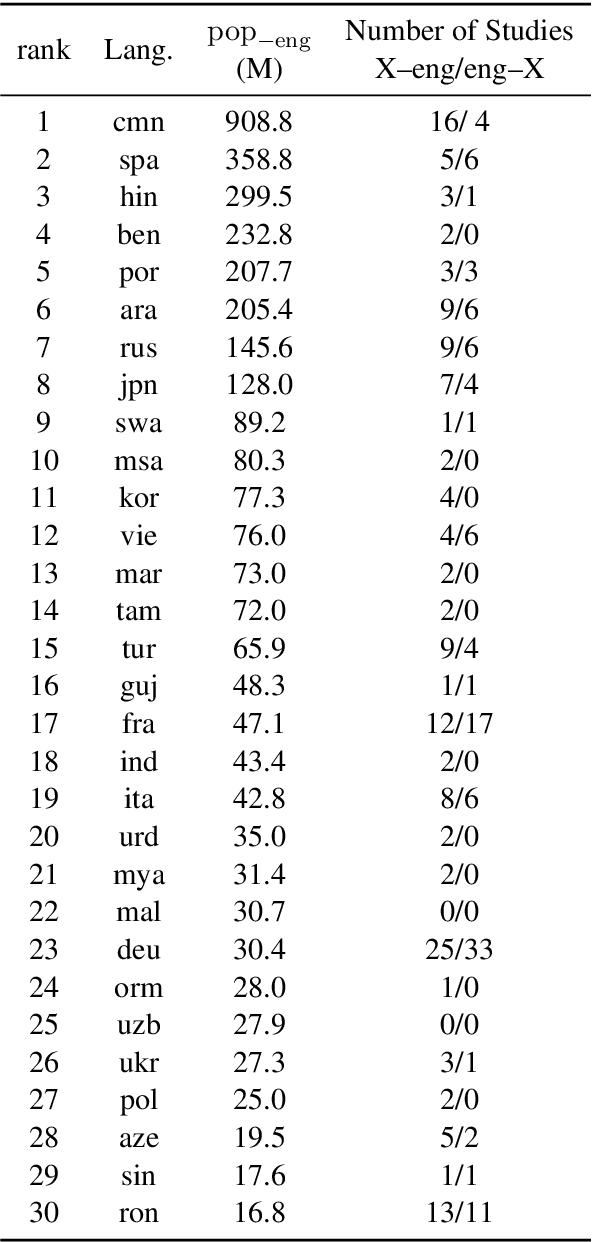
Natural language processing (NLP) systems have become a central technology in communication, education, medicine, artificial intelligence, and many other domains of research and development. While the performance of NLP methods has grown enormously over the last decade, this progress has been restricted to a minuscule subset of the world's 6,500 languages. We introduce a framework for estimating the global utility of language technologies as revealed in a comprehensive snapshot of recent publications in NLP. Our analyses involve the field at large, but also more in-depth studies on both user-facing technologies (machine translation, language understanding, question answering, text-to-speech synthesis) as well as more linguistic NLP tasks (dependency parsing, morphological inflection). In the process, we (1) quantify disparities in the current state of NLP research, (2) explore some of its associated societal and academic factors, and (3) produce tailored recommendations for evidence-based policy making aimed at promoting more global and equitable language technologies.
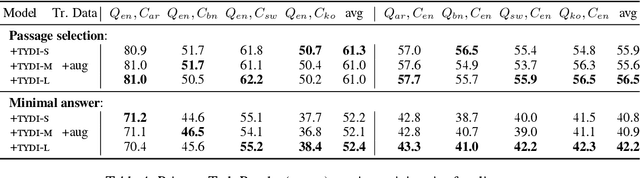
SD-QA: Spoken Dialectal Question Answering for the Real World
Sep 24, 2021

Question answering (QA) systems are now available through numerous commercial applications for a wide variety of domains, serving millions of users that interact with them via speech interfaces. However, current benchmarks in QA research do not account for the errors that speech recognition models might introduce, nor do they consider the language variations (dialects) of the users. To address this gap, we augment an existing QA dataset to construct a multi-dialect, spoken QA benchmark on five languages (Arabic, Bengali, English, Kiswahili, Korean) with more than 68k audio prompts in 24 dialects from 255 speakers. We provide baseline results showcasing the real-world performance of QA systems and analyze the effect of language variety and other sensitive speaker attributes on downstream performance. Last, we study the fairness of the ASR and QA models with respect to the underlying user populations. The dataset, model outputs, and code for reproducing all our experiments are available: https://github.com/ffaisal93/SD-QA.
Investigating Post-pretraining Representation Alignment for Cross-Lingual Question Answering
Sep 24, 2021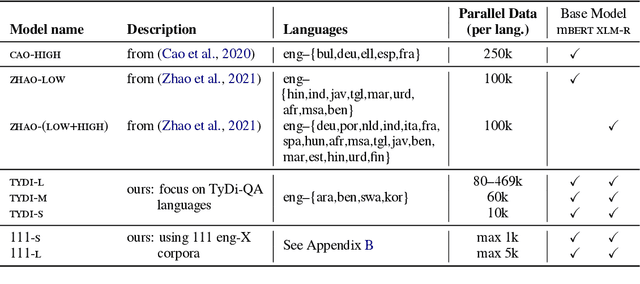
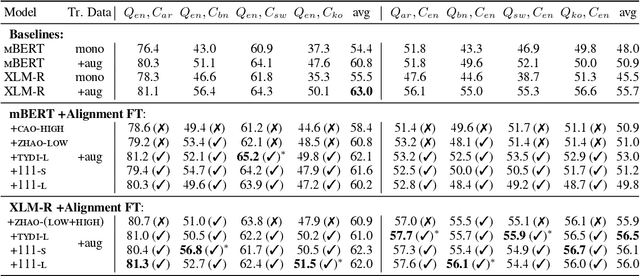
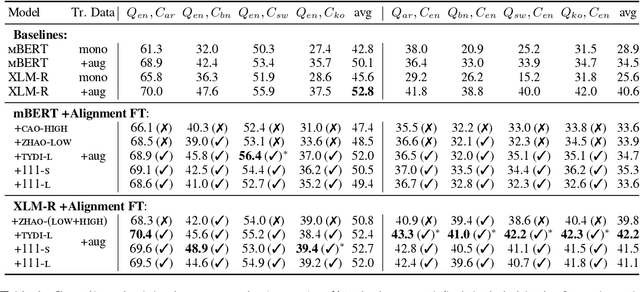
Human knowledge is collectively encoded in the roughly 6500 languages spoken around the world, but it is not distributed equally across languages. Hence, for information-seeking question answering (QA) systems to adequately serve speakers of all languages, they need to operate cross-lingually. In this work we investigate the capabilities of multilingually pre-trained language models on cross-lingual QA. We find that explicitly aligning the representations across languages with a post-hoc fine-tuning step generally leads to improved performance. We additionally investigate the effect of data size as well as the language choice in this fine-tuning step, also releasing a dataset for evaluating cross-lingual QA systems. Code and dataset are publicly available here: https://github.com/ffaisal93/aligned_qa
When is Wall a Pared and when a Muro? -- Extracting Rules Governing Lexical Selection
Sep 13, 2021
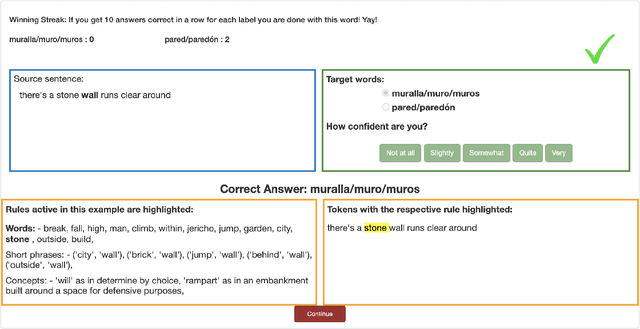

Learning fine-grained distinctions between vocabulary items is a key challenge in learning a new language. For example, the noun "wall" has different lexical manifestations in Spanish -- "pared" refers to an indoor wall while "muro" refers to an outside wall. However, this variety of lexical distinction may not be obvious to non-native learners unless the distinction is explained in such a way. In this work, we present a method for automatically identifying fine-grained lexical distinctions, and extracting concise descriptions explaining these distinctions in a human- and machine-readable format. We confirm the quality of these extracted descriptions in a language learning setup for two languages, Spanish and Greek, where we use them to teach non-native speakers when to translate a given ambiguous word into its different possible translations. Code and data are publicly released here (https://github.com/Aditi138/LexSelection)
Cross-Lingual Text Classification of Transliterated Hindi and Malayalam
Aug 31, 2021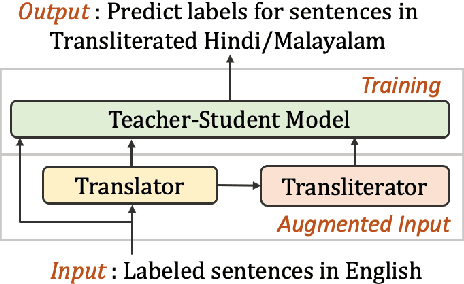
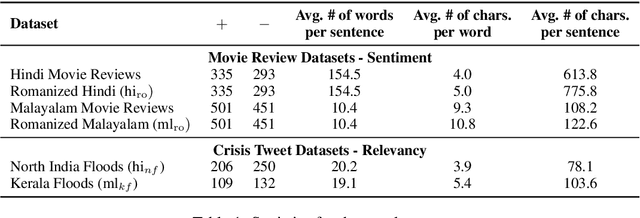

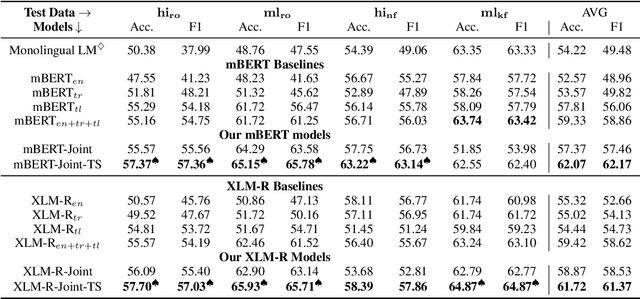
Transliteration is very common on social media, but transliterated text is not adequately handled by modern neural models for various NLP tasks. In this work, we combine data augmentation approaches with a Teacher-Student training scheme to address this issue in a cross-lingual transfer setting for fine-tuning state-of-the-art pre-trained multilingual language models such as mBERT and XLM-R. We evaluate our method on transliterated Hindi and Malayalam, also introducing new datasets for benchmarking on real-world scenarios: one on sentiment classification in transliterated Malayalam, and another on crisis tweet classification in transliterated Hindi and Malayalam (related to the 2013 North India and 2018 Kerala floods). Our method yielded an average improvement of +5.6% on mBERT and +4.7% on XLM-R in F1 scores over their strong baselines.
On the Evaluation of Machine Translation for Terminology Consistency
Jun 24, 2021
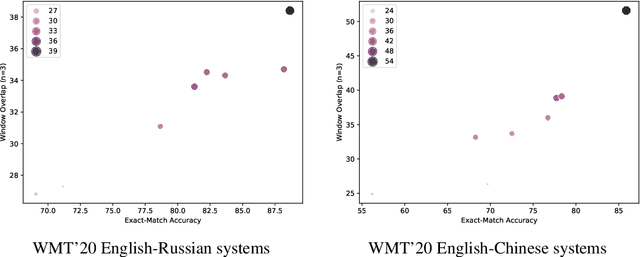

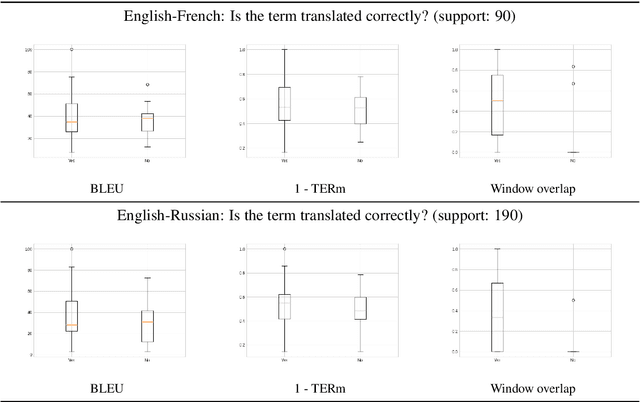
As neural machine translation (NMT) systems become an important part of professional translator pipelines, a growing body of work focuses on combining NMT with terminologies. In many scenarios and particularly in cases of domain adaptation, one expects the MT output to adhere to the constraints provided by a terminology. In this work, we propose metrics to measure the consistency of MT output with regards to a domain terminology. We perform studies on the COVID-19 domain over 5 languages, also performing terminology-targeted human evaluation. We open-source the code for computing all proposed metrics: https://github.com/mahfuzibnalam/terminology_evaluation
Code to Comment Translation: A Comparative Study on Model Effectiveness & Errors
Jun 15, 2021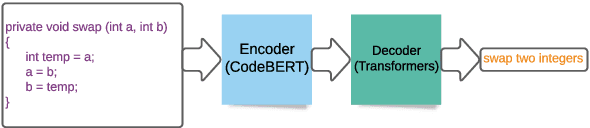
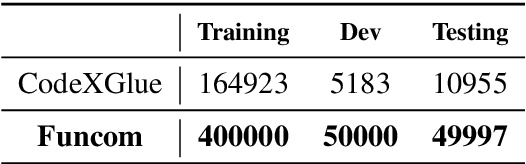


Automated source code summarization is a popular software engineering research topic wherein machine translation models are employed to "translate" code snippets into relevant natural language descriptions. Most evaluations of such models are conducted using automatic reference-based metrics. However, given the relatively large semantic gap between programming languages and natural language, we argue that this line of research would benefit from a qualitative investigation into the various error modes of current state-of-the-art models. Therefore, in this work, we perform both a quantitative and qualitative comparison of three recently proposed source code summarization models. In our quantitative evaluation, we compare the models based on the smoothed BLEU-4, METEOR, and ROUGE-L machine translation metrics, and in our qualitative evaluation, we perform a manual open-coding of the most common errors committed by the models when compared to ground truth captions. Our investigation reveals new insights into the relationship between metric-based performance and model prediction errors grounded in an empirically derived error taxonomy that can be used to drive future research efforts
Machine Translation into Low-resource Language Varieties
Jun 12, 2021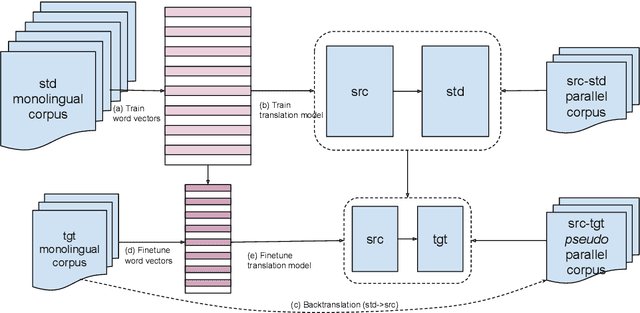
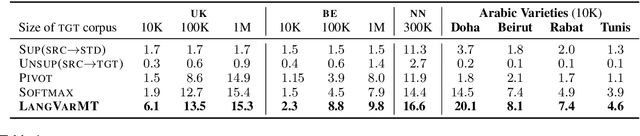


State-of-the-art machine translation (MT) systems are typically trained to generate the "standard" target language; however, many languages have multiple varieties (regional varieties, dialects, sociolects, non-native varieties) that are different from the standard language. Such varieties are often low-resource, and hence do not benefit from contemporary NLP solutions, MT included. We propose a general framework to rapidly adapt MT systems to generate language varieties that are close to, but different from, the standard target language, using no parallel (source--variety) data. This also includes adaptation of MT systems to low-resource typologically-related target languages. We experiment with adapting an English--Russian MT system to generate Ukrainian and Belarusian, an English--Norwegian Bokm{\aa}l system to generate Nynorsk, and an English--Arabic system to generate four Arabic dialects, obtaining significant improvements over competitive baselines.