 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Idea Elaboration on the Automatic Assessment of Idea Originality
Apr 22, 2026Automatic systems are increasingly used to assess the originality of responses in creative tasks. They offer a potential solution to key limitations of human assessment (cost, fatigue, and subjectivity), but there is preliminary evidence of a self-preference bias. Accordingly, automatic systems tend to prefer outcomes that are more closely related to their style, rather than to the human one. In this paper, we investigated how Large Language Models (LLMs) align with human raters in assessing the originality of responses in a divergent thinking task. We analysed 4,813 responses to the Alternate Uses Task produced by higher and lower creative humans and ChatGPT-4o. Human raters were two university students who underwent intensive training. Machine raters were two specialised systems fine-tuned on AUT responses and corresponding human ratings (OCSAI and CLAUS) and ChatGPT-4o, which was prompted with the same instructions as human raters. Results confirmed the presence of a self-preference bias in LLMs. Automatic systems tended to privilege artificial responses. However, this self-preference bias disappeared when the analyses controlled for the idea elaboration. We discuss theoretical and methodological implications of these findings by highlighting future directions for research on creativity assessment.
Follow, listen, feel and go: alternative guidance systems for a walking assistance device
Jan 15, 2016
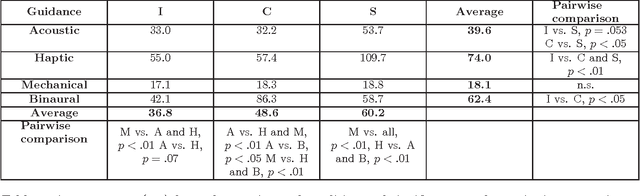
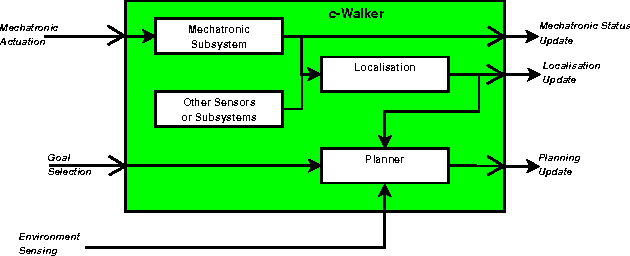

In this paper, we propose several solutions to guide an older adult along a safe path using a robotic walking assistant (the c-Walker). We consider four different possibilities to execute the task. One of them is mechanical, with the c-Walker playing an active role in setting the course. The other ones are based on tactile or acoustic stimuli, and suggest a direction of motion that the user is supposed to take on her own will. We describe the technological basis for the hardware components implementing the different solutions, and show specialized path following algorithms for each of them. The paper reports an extensive user validation activity with a quantitative and qualitative analysis of the different solutions. In this work, we test our system just with young participants to establish a safer methodology that will be used in future studies with older adults.