 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Augmented Generation for Financial Applications
Apr 21, 2026Evaluating the reasoning capabilities of Large Language Models (LLMs) for complex, quantitative financial tasks is a critical and unsolved challenge. Standard benchmarks often fail to isolate an agent's core ability to parse queries and orchestrate computations. To address this, we introduce a novel evaluation methodology and benchmark designed to rigorously measure an LLM agent's reasoning for financial time-series analysis. We apply this methodology in a large-scale empirical study using our framework, Time Series Augmented Generation (TSAG), where an LLM agent delegates quantitative tasks to verifiable, external tools. Our benchmark, consisting of 100 financial questions, is used to compare multiple SOTA agents (e.g., GPT-4o, Llama 3, Qwen2) on metrics assessing tool selection accuracy, faithfulness, and hallucination. The results demonstrate that capable agents can achieve near-perfect tool-use accuracy with minimal hallucination, validating the tool-augmented paradigm. Our primary contribution is this evaluation framework and the corresponding empirical insights into agent performance, which we release publicly to foster standardized research on reliable financial AI.
Computational Concept of the Psyche
Mar 16, 2026This article presents an overview of approaches to modeling the human psyche in the context of constructing an artificial one. Based on this overview, a concept of cognitive architecture is proposed, in which the psyche is viewed as the operating system of a living or artificial subject, comprising a space of states, including the state of needs that determine the meaning of a subject's being in relation to stimuli from the external world, and intelligence as a decision-making system regarding actions in this world to satisfy these needs. Based on this concept, a computational formalization is proposed for creating artificial general intelligence systems for an agent through experiential learning in a state space that includes agent's needs, taking into account their biological or existential significance for the intelligent agent, along with agent's sensations and actions. Thus, the problem of constructing artificial general intelligence is formalized as a system for making optimal decisions in the space of specific agent needs under conditions of uncertainty, maximizing success in achieving goals, minimizing existential risks, and maximizing energy efficiency. A minimal experimental implementation of the model is presented.
Interpretable Recognition of Cognitive Distortions in Natural Language Texts
Nov 08, 2025We propose a new approach to multi-factor classification of natural language texts based on weighted structured patterns such as N-grams, taking into account the heterarchical relationships between them, applied to solve such a socially impactful problem as the automation of detection of specific cognitive distortions in psychological care, relying on an interpretable, robust and transparent artificial intelligence model. The proposed recognition and learning algorithms improve the current state of the art in this field. The improvement is tested on two publicly available datasets, with significant improvements over literature-known F1 scores for the task, with optimal hyper-parameters determined, having code and models available for future use by the community.
Evolution of Efficient Symbolic Communication Codes
Jun 11, 2023



The paper explores how the human natural language structure can be seen as a product of evolution of inter-personal communication code, targeting maximisation of such culture-agnostic and cross-lingual metrics such as anti-entropy, compression factor and cross-split F1 score. The exploration is done as part of a larger unsupervised language learning effort, the attempt is made to perform meta-learning in a space of hyper-parameters maximising F1 score based on the "ground truth" language structure, by means of maximising the metrics mentioned above. The paper presents preliminary results of cross-lingual word-level segmentation tokenisation study for Russian, Chinese and English as well as subword segmentation or morphological parsing study for English. It is found that language structure form the word-level segmentation or tokenisation can be found as driven by all of these metrics, anti-entropy being more relevant to English and Russian while compression factor more specific for Chinese. The study for subword segmentation or morphological parsing on English lexicon has revealed straight connection between the compression been found to be associated with compression factor, while, surprising, the same connection with anti-entropy has turned to be the inverse.
Self-tuning hyper-parameters for unsupervised cross-lingual tokenization
Mar 04, 2023



We explore the possibility of meta-learning for the language-independent unsupervised tokenization problem for English, Russian, and Chinese. We implement the meta-learning approach for automatic determination of hyper-parameters of the unsupervised tokenization model proposed in earlier works, relying on various human-independent fitness functions such as normalised anti-entropy, compression factor and cross-split F 1 score, as well as additive and multiplicative composite combinations of the three metrics, testing them against the conventional F1 tokenization score. We find a fairly good correlation between the latter and the additive combination of the former three metrics for English and Russian. In case of Chinese, we find a significant correlation between the F 1 score and the compression factor. Our results suggest the possibility of robust unsupervised tokenization of low-resource and dead languages and allow us to think about human languages in terms of the evolution of efficient symbolic communication codes with different structural optimisation schemes that have evolved in different human cultures.
Cognitive Architecture for Decision-Making Based on Brain Principles Programming (in Russian)
Feb 18, 2023



We describe a cognitive architecture intended to solve a wide range of problems based on the five identified principles of brain activity, with their implementation in three subsystems: logical-probabilistic inference, probabilistic formal concepts, and functional systems theory. Building an architecture involves the implementation of a task-driven approach that allows defining the target functions of applied applications as tasks formulated in terms of the operating environment corresponding to the task, expressed in the applied ontology. We provide a basic ontology for a number of practical applications as well as for the subject domain ontologies based upon it, describe the proposed architecture, and give possible examples of the execution of these applications in this architecture.
* 13 pages, 5 figures, Russian language, original English version of the paper is presented on BICA-2023 - 2023 Annual International Conference on Brain-Inspired Cognitive Architectures for Artificial Intelligence, the 14th Annual Meeting of the BICA Society
Application of Liquid Rank Reputation System for Content Recommendation
Sep 15, 2022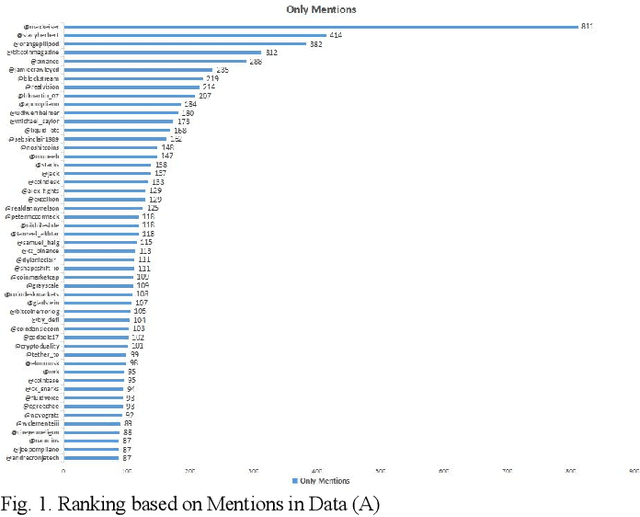
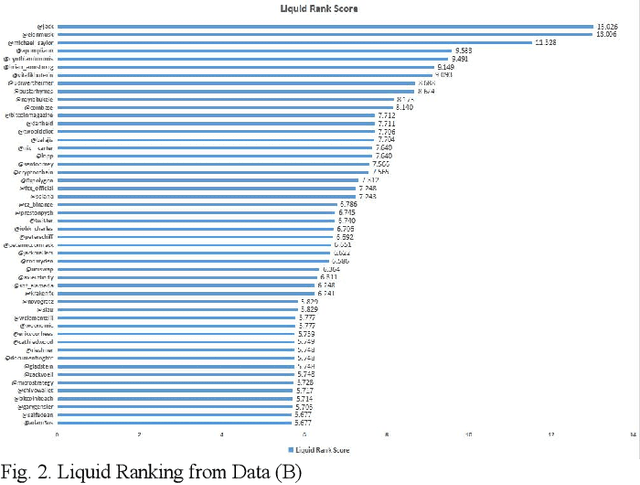
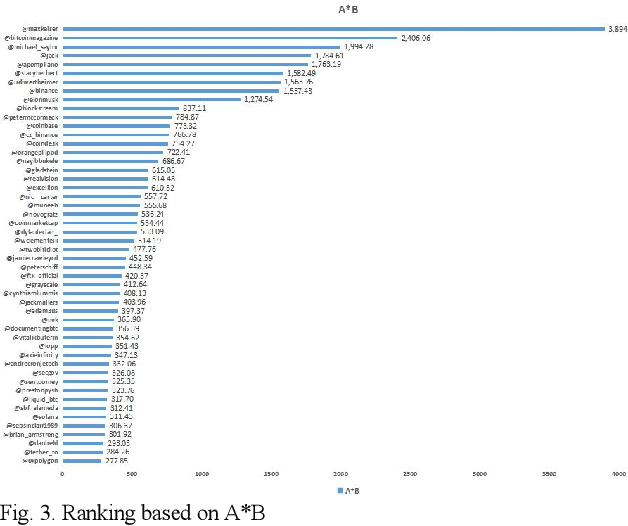
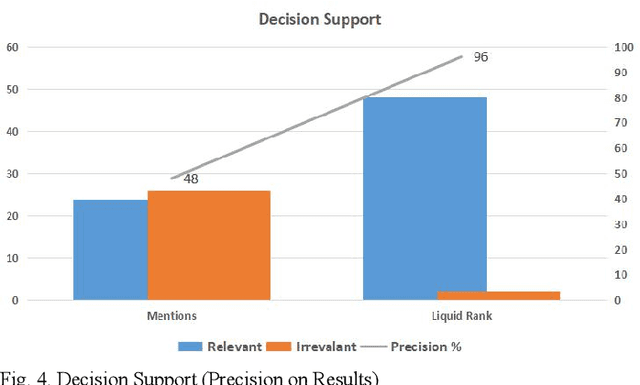
An effective content recommendation on social media platforms should be able to benefit both creators to earn fair compensation and consumers to enjoy really relevant, interesting, and personalized content. In this paper, we propose a model to implement the liquid democracy principle for the content recommendation system. It uses a personalized recommendation model based on reputation ranking system to encourage personal interests driven recommendation. Moreover, the personalization factors to an end users' higher-order friends on the social network (initial input Twitter channels in our case study) to improve the accuracy and diversity of recommendation results. This paper analyzes the dataset based on cryptocurrency news on Twitter to find the opinion leader using the liquid rank reputation system. This paper deals with the tier-2 implementation of a liquid rank in a content recommendation model. This model can be also used as an additional layer in the other recommendation systems. The paper proposes the implementation, challenges, and future scope of the liquid rank reputation model.
Unsupervised Tokenization Learning
May 23, 2022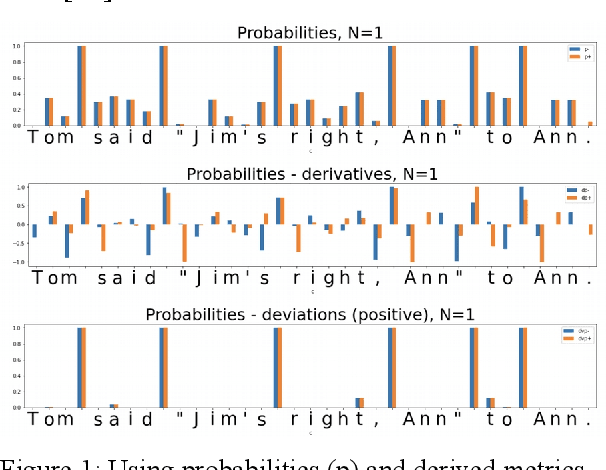
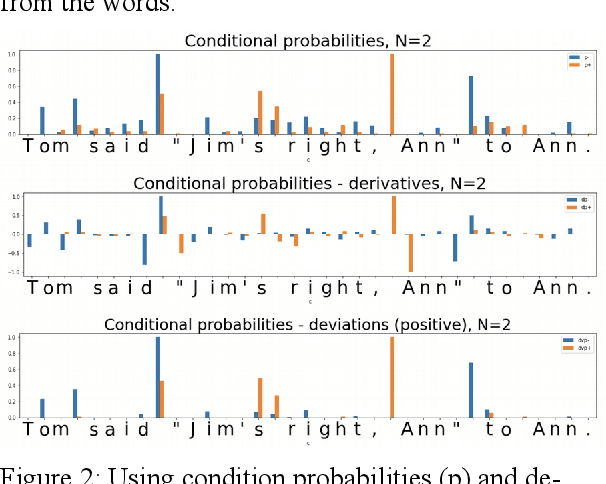
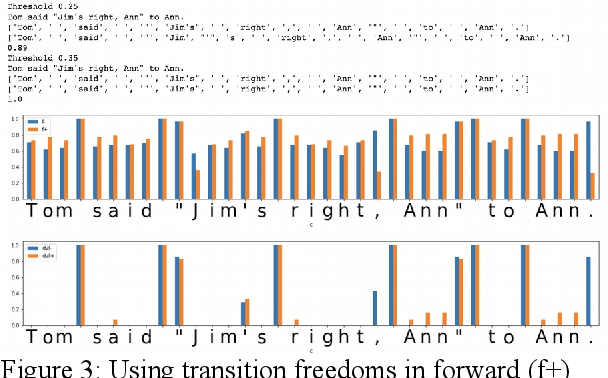
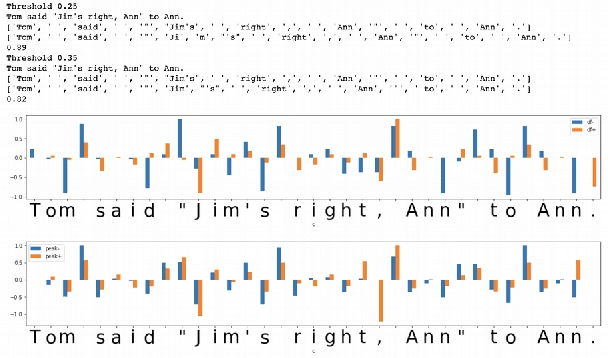
In the presented study, we discover that so called "transition freedom" metric appears superior for unsupervised tokenization purposes, compared to statistical metrics such as mutual information and conditional probability, providing F-measure scores in range from 0.71 to 1.0 across explored corpora. We find that different languages require different derivatives of that metric (such as variance and "peak values") for successful tokenization. Larger training corpora does not necessarily effect in better tokenization quality, while compacting the models eliminating statistically weak evidence tends to improve performance. Proposed unsupervised tokenization technique provides quality better or comparable to lexicon-based one, depending on the language.
Causal Analysis of Generic Time Series Data Applied for Market Prediction
Apr 22, 2022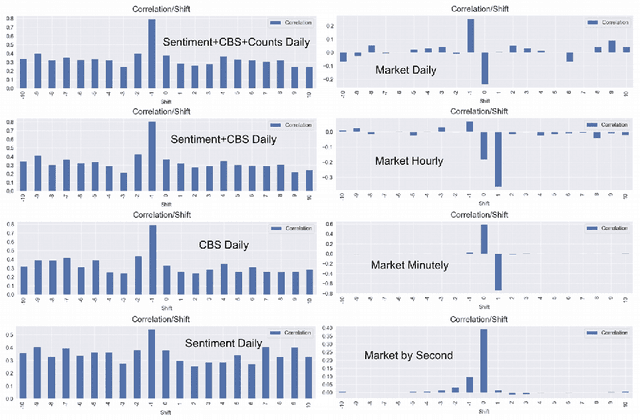
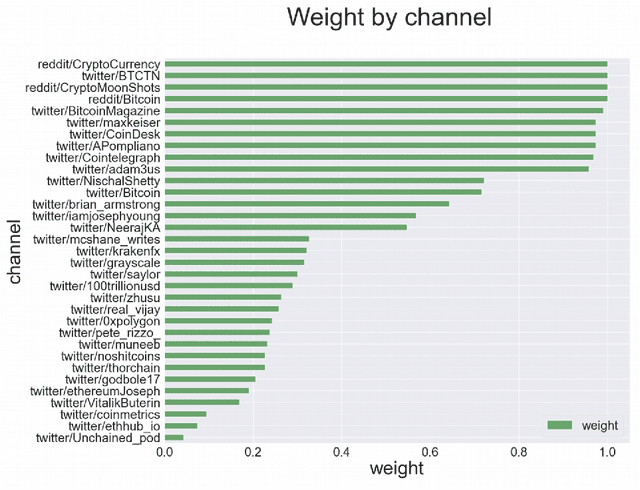
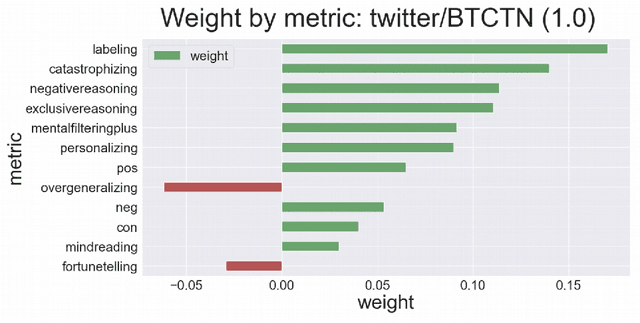
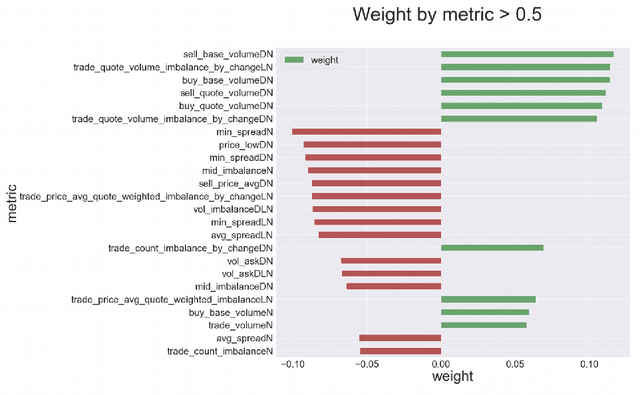
We explore the applicability of the causal analysis based on temporally shifted (lagged) Pearson correlation applied to diverse time series of different natures in context of the problem of financial market prediction. Theoretical discussion is followed by description of the practical approach for specific environment of time series data with diverse nature and sparsity, as applied for environments of financial markets. The data involves various financial metrics computable from raw market data such as real-time trades and snapshots of the limit order book as well as metrics determined upon social media news streams such as sentiment and different cognitive distortions. The approach is backed up with presentation of algorithmic framework for data acquisition and analysis, concluded with experimental results, and summary pointing out at the possibility to discriminate causal connections between different sorts of real field market data with further discussion on present issues and possible directions of the following work.
Social Media Sentiment Analysis for Cryptocurrency Market Prediction
Apr 19, 2022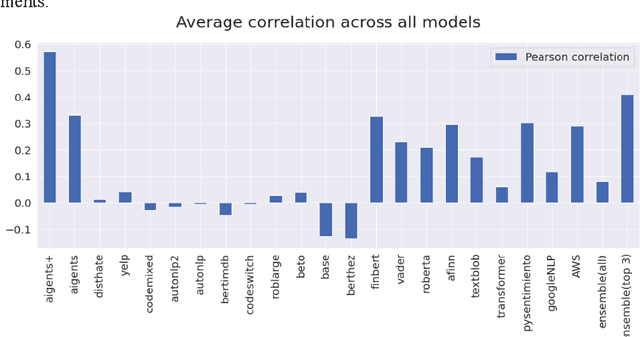
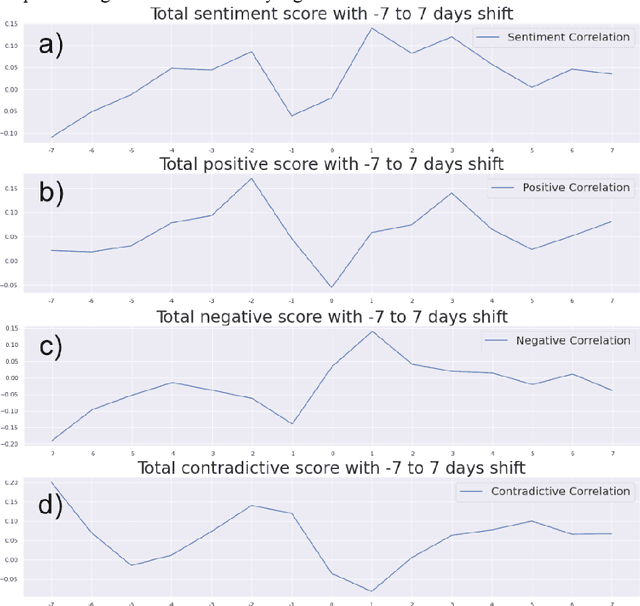
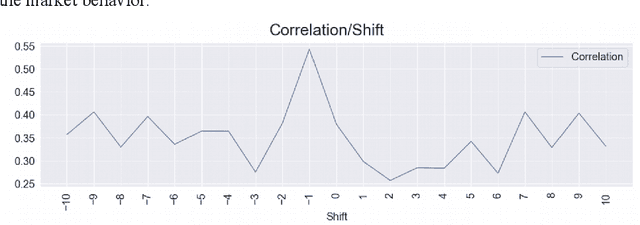
In this paper, we explore the usability of different natural language processing models for the sentiment analysis of social media applied to financial market prediction, using the cryptocurrency domain as a reference. We study how the different sentiment metrics are correlated with the price movements of Bitcoin. For this purpose, we explore different methods to calculate the sentiment metrics from a text finding most of them not very accurate for this prediction task. We find that one of the models outperforms more than 20 other public ones and makes it possible to fine-tune it efficiently given its interpretable nature. Thus we confirm that interpretable artificial intelligence and natural language processing methods might be more valuable practically than non-explainable and non-interpretable ones. In the end, we analyse potential causal connections between the different sentiment metrics and the price movements.