 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mathematical Model of the Hidden Feedback Loop Effect in Machine Learning Systems
May 04, 2024Widespread deployment of societal-scale machine learning systems necessitates a thorough understanding of the resulting long-term effects these systems have on their environment, including loss of trustworthiness, bias amplification, and violation of AI safety requirements. We introduce a repeated learning process to jointly describe several phenomena attributed to unintended hidden feedback loops, such as error amplification, induced concept drift, echo chambers and others. The process comprises the entire cycle of obtaining the data, training the predictive model, and delivering predictions to end-users within a single mathematical model. A distinctive feature of such repeated learning setting is that the state of the environment becomes causally dependent on the learner itself over time, thus violating the usual assumptions about the data distribution. We present a novel dynamical systems model of the repeated learning process and prove the limiting set of probability distributions for positive and negative feedback loop modes of the system operation. We conduct a series of computational experiments using an exemplary supervised learning problem on two synthetic data sets. The results of the experiments correspond to the theoretical predictions derived from the dynamical model. Our results demonstrate the feasibility of the proposed approach for studying the repeated learning processes in machine learning systems and open a range of opportunities for further research in the area.
Towards automated verification of multi-party consensus protocols
Dec 04, 2021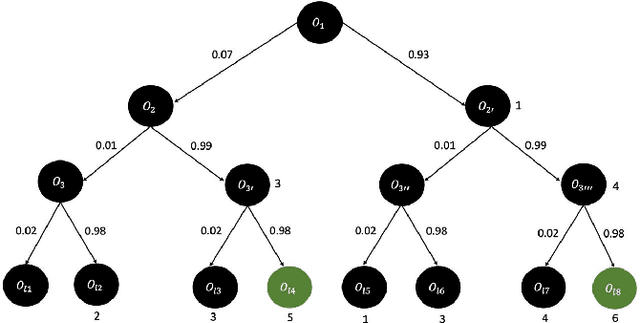
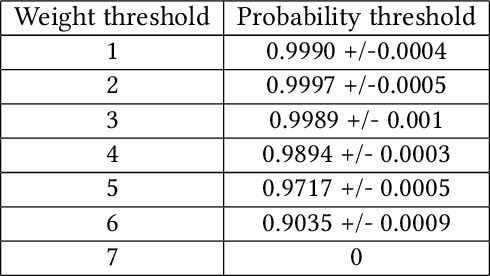
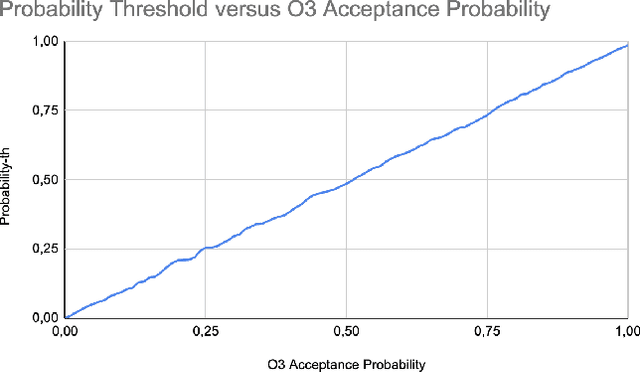
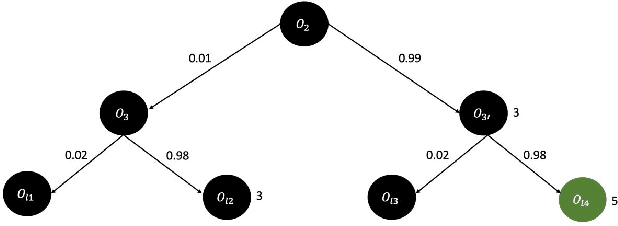
Blockchain technology and related frameworks have recently received extensive attention. Blockchain systems use multi-party consensus protocols to reach agreements on transactions. Hyperledger Fabric framework exposes a multi-party consensus, based on endorsement policy protocol, to reach a consensus on a transaction. In this paper, we define a problem of verification of a blockchain multi-party consensus with probabilistic properties. Further, we propose a verification technique of endorsement policies using statistical model checking and hypothesis testing. We analyze several aspects of the policies, including the ability to assign weights to organizations and the refusal probabilities of organizations. We demonstrate on experiments the work of our verification technique and how one can use experimental results to make the model satisfiable the specification. One can use our technique to design enterprise applications with the Hyperledger Fabric framework.
MLDev: Data Science Experiment Automation and Reproducibility Software
Jul 26, 2021In this paper we explore the challenges of automating experiments in data science. We propose an extensible experiment model as a foundation for integration of different open source tools for running research experiments. We implement our approach in a prototype open source MLDev software package and evaluate it in a series of experiments yielding promising results. Comparison with other state-of-the-art tools signifies novelty of our approach.
Analysis of hidden feedback loops in continuous machine learning systems
Jan 17, 2021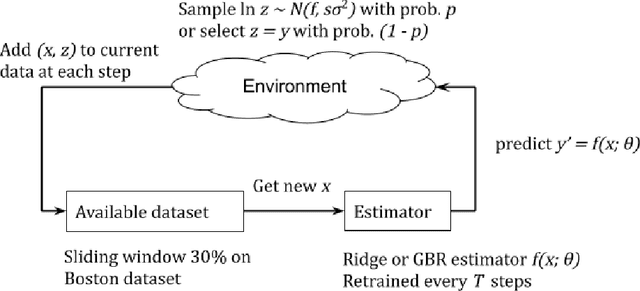
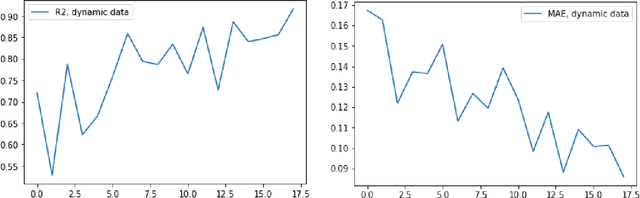
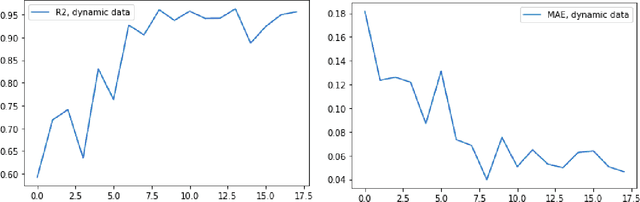
In this concept paper, we discuss intricacies of specifying and verifying the quality of continuous and lifelong learning artificial intelligence systems as they interact with and influence their environment causing a so-called concept drift. We signify a problem of implicit feedback loops, demonstrate how they intervene with user behavior on an exemplary housing prices prediction system. Based on a preliminary model, we highlight conditions when such feedback loops arise and discuss possible solution approaches.
* 7 pages, 9 figures; added more experiments, minor stylistic fixes and typos