 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS3D: End2End Self-Supervised 3D from Web Videos
Apr 24, 2026We present SS3D, a web-scale SfM-based self-supervision pretraining pipeline for feed-forward 3D estimation from monocular video. Our model jointly predicts depth, ego-motion, and intrinsics in a single forward pass and is trained/evaluated as a coherent end-to-end 3D estimator. To stabilize joint learning, we use an intrinsics-first two-stage schedule and a unified single-checkpoint evaluation protocol. Scaling SfM self-supervision to unconstrained web video is challenging due to weak multi-view observability and strong corpus heterogeneity; we address these with a multi-view signal proxy (MVS) used for filtering and curriculum sampling, and with expert training distilled into a single student. Pretraining on YouTube-8M (~100M frames after filtering) yields strong cross-domain zero-shot transfer and improved fine-tuning performance over prior self-supervised baselines. We release the pretrained checkpoint and code.
A Geometric Multimodal Foundation Model Integrating Bp-MRI and Clinical Reports in Prostate Cancer Classification
Jan 30, 2026Prostate cancer (PCa) is one of the most common cancers in men worldwide. Bi-parametric MRI (bp-MRI) and clinical variables are crucial for PCa identification and improving treatment decisions. However, this process is subjective to expert interpretations. Furthermore, most existing computer-aided diagnosis methods focus on imaging-based models, overlooking the clinical context and suffering from data scarcity, limiting their ability to learn robust representations. We propose a geometric multimodal Foundation Model (FM), named MFM-Geom, that learns representations from bp-MRI and clinical reports, encoding visual findings and information from the context of clinical variables. In the representations classification head, the approach leverages symmetric positive definite (SPD) matrices and Riemannian deep learning to integrate imaging-text representations from a biomedical multimodal FM. Using 10% of the training data, MFM-Geom outperformed baseline class token embedding-based classification (+8.3%, AUC-PR of 90.67). Generalization on external dataset confirmed the robustness of fine-tuning biomedical FM, achieving an AUC-PR of 90.6.
Double Descent Meets Out-of-Distribution Detection: Theoretical Insights and Empirical Analysis on the role of model complexity
Nov 04, 2024



While overparameterization is known to benefit generalization, its impact on Out-Of-Distribution (OOD) detection is less understood. This paper investigates the influence of model complexity in OOD detection. We propose an expected OOD risk metric to evaluate classifiers confidence on both training and OOD samples. Leveraging Random Matrix Theory, we derive bounds for the expected OOD risk of binary least-squares classifiers applied to Gaussian data. We show that the OOD risk depicts an infinite peak, when the number of parameters is equal to the number of samples, which we associate with the double descent phenomenon. Our experimental study on different OOD detection methods across multiple neural architectures extends our theoretical insights and highlights a double descent curve. Our observations suggest that overparameterization does not necessarily lead to better OOD detection. Using the Neural Collapse framework, we provide insights to better understand this behavior. To facilitate reproducibility, our code will be made publicly available upon publication.
Leveraging a realistic synthetic database to learn Shape-from-Shading for estimating the colon depth in colonoscopy images
Nov 08, 2023



Colonoscopy is the choice procedure to diagnose colon and rectum cancer, from early detection of small precancerous lesions (polyps), to confirmation of malign masses. However, the high variability of the organ appearance and the complex shape of both the colon wall and structures of interest make this exploration difficult. Learned visuospatial and perceptual abilities mitigate technical limitations in clinical practice by proper estimation of the intestinal depth. This work introduces a novel methodology to estimate colon depth maps in single frames from monocular colonoscopy videos. The generated depth map is inferred from the shading variation of the colon wall with respect to the light source, as learned from a realistic synthetic database. Briefly, a classic convolutional neural network architecture is trained from scratch to estimate the depth map, improving sharp depth estimations in haustral folds and polyps by a custom loss function that minimizes the estimation error in edges and curvatures. The network was trained by a custom synthetic colonoscopy database herein constructed and released, composed of 248,400 frames (47 videos), with depth annotations at the level of pixels. This collection comprehends 5 subsets of videos with progressively higher levels of visual complexity. Evaluation of the depth estimation with the synthetic database reached a threshold accuracy of 95.65%, and a mean-RMSE of 0.451 cm, while a qualitative assessment with a real database showed consistent depth estimations, visually evaluated by the expert gastroenterologist coauthoring this paper. Finally, the method achieved competitive performance with respect to another state-of-the-art method using a public synthetic database and comparable results in a set of images with other five state-of-the-art methods.
NECO: NEural Collapse Based Out-of-distribution detection
Oct 12, 2023



Detecting out-of-distribution (OOD) data is a critical challenge in machine learning due to model overconfidence, often without awareness of their epistemological limits. We hypothesize that ``neural collapse'', a phenomenon affecting in-distribution data for models trained beyond loss convergence, also influences OOD data. To benefit from this interplay, we introduce NECO, a novel post-hoc method for OOD detection, which leverages the geometric properties of ``neural collapse'' and of principal component spaces to identify OOD data. Our extensive experiments demonstrate that NECO achieves state-of-the-art results on both small and large-scale OOD detection tasks while exhibiting strong generalization capabilities across different network architectures. Furthermore, we provide a theoretical explanation for the effectiveness of our method in OOD detection. We plan to release the code after the anonymity period.
InfraParis: A multi-modal and multi-task autonomous driving dataset
Sep 27, 2023



Current deep neural networks (DNNs) for autonomous driving computer vision are typically trained on specific datasets that only involve a single type of data and urban scenes. Consequently, these models struggle to handle new objects, noise, nighttime conditions, and diverse scenarios, which is essential for safety-critical applications. Despite ongoing efforts to enhance the resilience of computer vision DNNs, progress has been sluggish, partly due to the absence of benchmarks featuring multiple modalities. We introduce a novel and versatile dataset named InfraParis that supports multiple tasks across three modalities: RGB, depth, and infrared. We assess various state-of-the-art baseline techniques, encompassing models for the tasks of semantic segmentation, object detection, and depth estimation.
A study of deep perceptual metrics for image quality assessment
Feb 17, 2022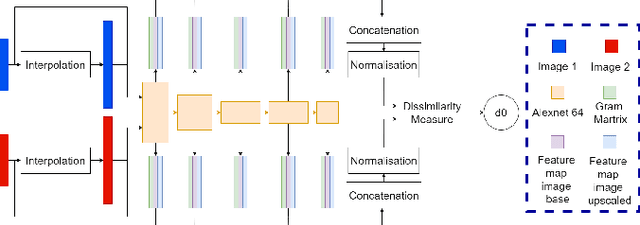
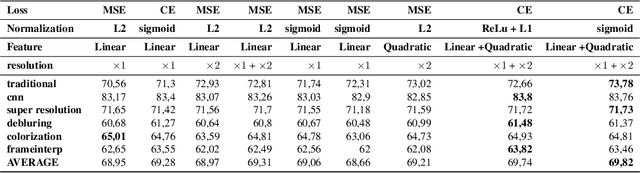
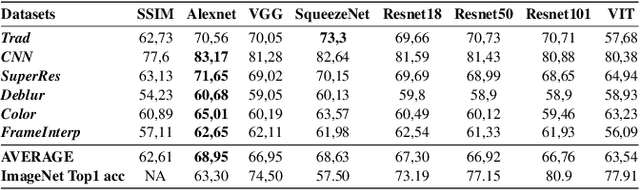
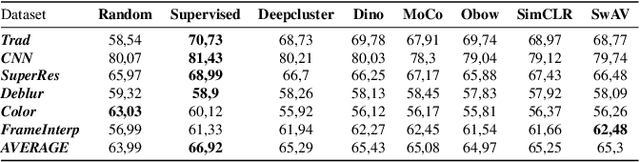
Several metrics exist to quantify the similarity between images, but they are inefficient when it comes to measure the similarity of highly distorted images. In this work, we propose to empirically investigate perceptual metrics based on deep neural networks for tackling the Image Quality Assessment (IQA) task. We study deep perceptual metrics according to different hyperparameters like the network's architecture or training procedure. Finally, we propose our multi-resolution perceptual metric (MR-Perceptual), that allows us to aggregate perceptual information at different resolutions and outperforms standard perceptual metrics on IQA tasks with varying image deformations. Our code is available at https://github.com/ENSTA-U2IS/MR_perceptual
Does it work outside this benchmark? Introducing the Rigid Depth Constructor tool, depth validation dataset construction in rigid scenes for the masses
Mar 29, 2021
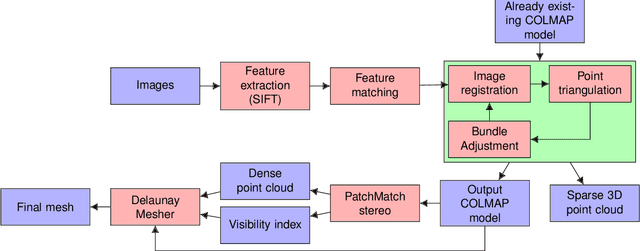
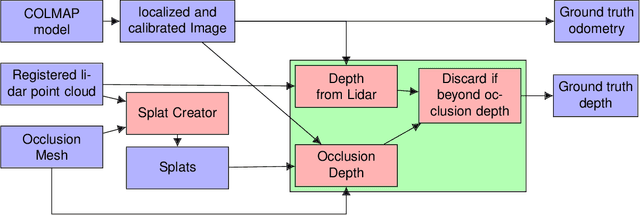
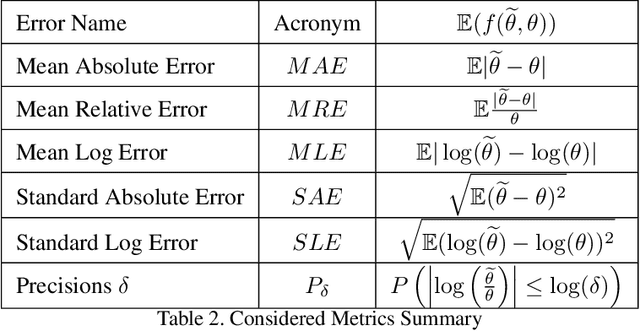
We present a protocol to construct your own depth validation dataset for navigation. This protocol, called RDC for Rigid Depth Constructor, aims at being more accessible and cheaper than already existing techniques, requiring only a camera and a Lidar sensor to get started. We also develop a test suite to get insightful information from the evaluated algorithm. Finally, we take the example of UAV videos, on which we test two depth algorithms that were initially tested on KITTI and show that the drone context is dramatically different from in-car videos. This shows that a single context benchmark should not be considered reliable, and when developing a depth estimation algorithm, one should benchmark it on a dataset that best fits one's particular needs, which often means creating a brand new one. Along with this paper we provide the tool with an open source implementation and plan to make it as user-friendly as possible, to make depth dataset creation possible even for small teams. Our key contributions are the following: We propose a complete, open-source and almost fully automatic software application for creating validation datasets with densely annotated depth, adaptable to a wide variety of image, video and range data. It includes selection tools to adapt the dataset to specific validation needs, and conversion tools to other dataset formats. Using this application, we propose two new real datasets, outdoor and indoor, readily usable in UAV navigation context. Finally as examples, we show an evaluation of two depth prediction algorithms, using a collection of comprehensive (e.g. distribution based) metrics.
Learning structure-from-motion from motion
Oct 19, 2018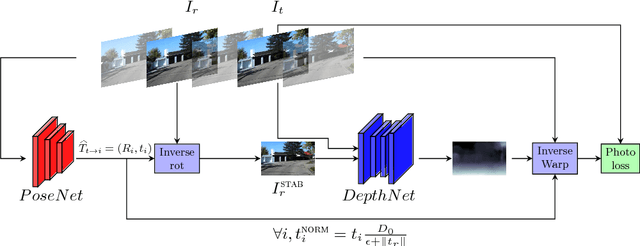
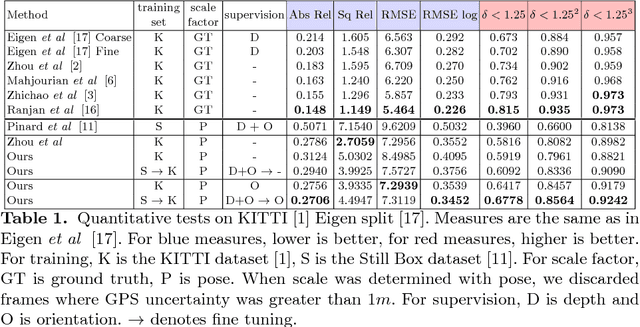


This work is based on a questioning of the quality metrics used by deep neural networks performing depth prediction from a single image, and then of the usability of recently published works on unsupervised learning of depth from videos. To overcome their limitations, we propose to learn in the same unsupervised manner a depth map inference system from monocular videos that takes a pair of images as input. This algorithm actually learns structure-from-motion from motion, and not only structure from context appearance. The scale factor issue is explicitly treated, and the absolute depth map can be estimated from camera displacement magnitude, which can be easily measured from cheap external sensors. Our solution is also much more robust with respect to domain variation and adaptation via fine tuning, because it does not rely entirely in depth from context. Two use cases are considered, unstabilized moving camera videos, and stabilized ones. This choice is motivated by the UAV (for Unmanned Aerial Vehicle) use case that generally provides reliable orientation measurement. We provide a set of experiments showing that, used in real conditions where only speed can be known, our network outperforms competitors for most depth quality measures. Results are given on the well known KITTI dataset, which provides robust stabilization for our second use case, but also contains moving scenes which are very typical of the in-car road context. We then present results on a synthetic dataset that we believe to be more representative of typical UAV scenes. Lastly, we present two domain adaptation use cases showing superior robustness of our method compared to single view depth algorithms, which indicates that it is better suited for highly variable visual contexts.
Multi range Real-time depth inference from a monocular stabilized footage using a Fully Convolutional Neural Network
Sep 12, 2018

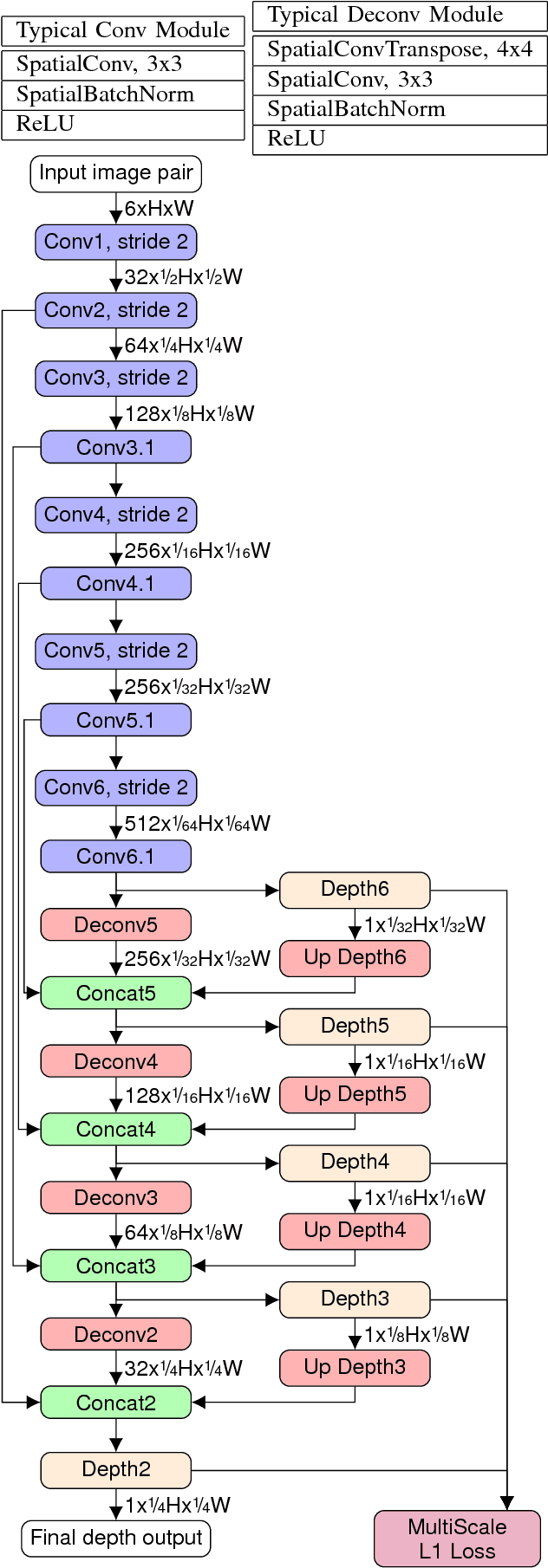

Using a neural network architecture for depth map inference from monocular stabilized videos with application to UAV videos in rigid scenes, we propose a multi-range architecture for unconstrained UAV flight, leveraging flight data from sensors to make accurate depth maps for uncluttered outdoor environment. We try our algorithm on both synthetic scenes and real UAV flight data. Quantitative results are given for synthetic scenes with a slightly noisy orientation, and show that our multi-range architecture improves depth inference. Along with this article is a video that present our results more thoroughly.
* arXiv admin note: text overlap with arXiv:1809.04453