 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Appearance Models in Visual Object Tracking
Mar 20, 2013
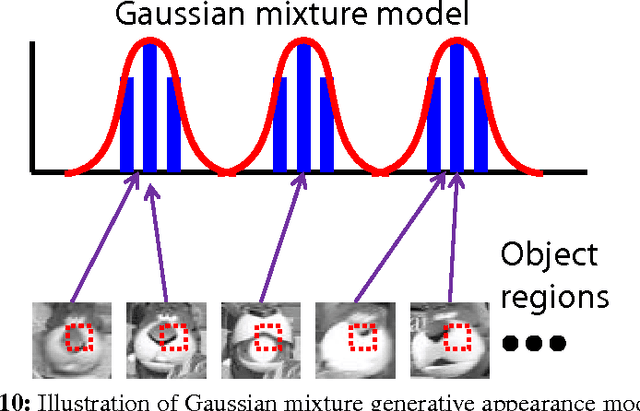
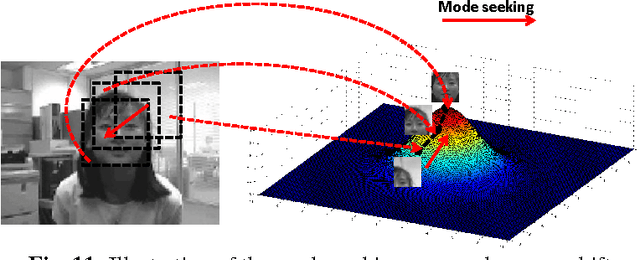

Visual object tracking is a significant computer vision task which can be applied to many domains such as visual surveillance, human computer interaction, and video compression. In the literature, researchers have proposed a variety of 2D appearance models. To help readers swiftly learn the recent advances in 2D appearance models for visual object tracking, we contribute this survey, which provides a detailed review of the existing 2D appearance models. In particular, this survey takes a module-based architecture that enables readers to easily grasp the key points of visual object tracking. In this survey, we first decompose the problem of appearance modeling into two different processing stages: visual representation and statistical modeling. Then, different 2D appearance models are categorized and discussed with respect to their composition modules. Finally, we address several issues of interest as well as the remaining challenges for future research on this topic. The contributions of this survey are four-fold. First, we review the literature of visual representations according to their feature-construction mechanisms (i.e., local and global). Second, the existing statistical modeling schemes for tracking-by-detection are reviewed according to their model-construction mechanisms: generative, discriminative, and hybrid generative-discriminative. Third, each type of visual representations or statistical modeling techniques is analyzed and discussed from a theoretical or practical viewpoint. Fourth, the existing benchmark resources (e.g., source code and video datasets) are examined in this survey.
Learning Hash Functions Using Column Generation
Mar 02, 2013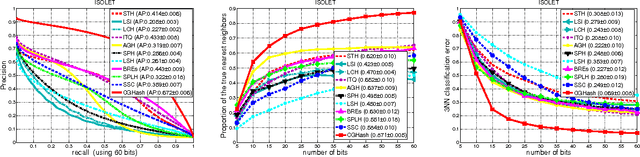
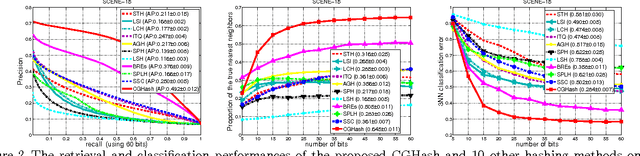
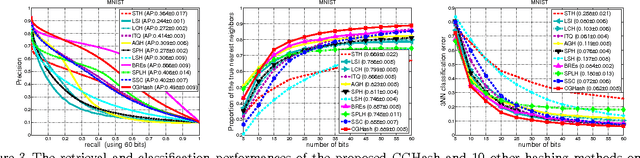
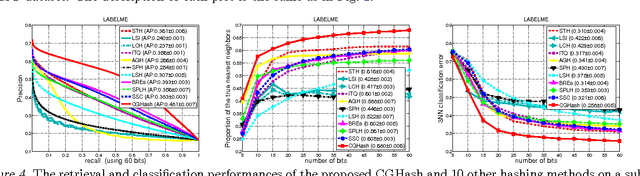
Fast nearest neighbor searching is becoming an increasingly important tool in solving many large-scale problems. Recently a number of approaches to learning data-dependent hash functions have been developed. In this work, we propose a column generation based method for learning data-dependent hash functions on the basis of proximity comparison information. Given a set of triplets that encode the pairwise proximity comparison information, our method learns hash functions that preserve the relative comparison relationships in the data as well as possible within the large-margin learning framework. The learning procedure is implemented using column generation and hence is named CGHash. At each iteration of the column generation procedure, the best hash function is selected. Unlike most other hashing methods, our method generalizes to new data points naturally; and has a training objective which is convex, thus ensuring that the global optimum can be identified. Experiments demonstrate that the proposed method learns compact binary codes and that its retrieval performance compares favorably with state-of-the-art methods when tested on a few benchmark datasets.
Incremental Learning of 3D-DCT Compact Representations for Robust Visual Tracking
Jul 18, 2012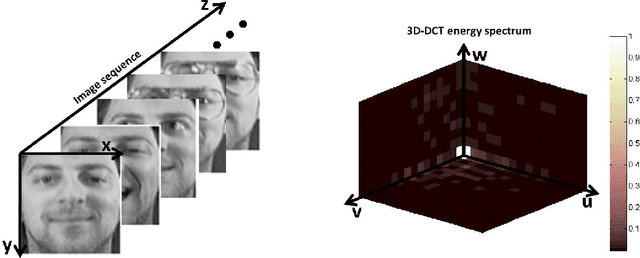

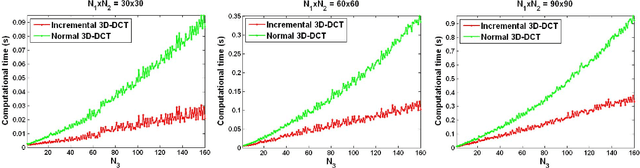
Visual tracking usually requires an object appearance model that is robust to changing illumination, pose and other factors encountered in video. In this paper, we construct an appearance model using the 3D discrete cosine transform (3D-DCT). The 3D-DCT is based on a set of cosine basis functions, which are determined by the dimensions of the 3D signal and thus independent of the input video data. In addition, the 3D-DCT can generate a compact energy spectrum whose high-frequency coefficients are sparse if the appearance samples are similar. By discarding these high-frequency coefficients, we simultaneously obtain a compact 3D-DCT based object representation and a signal reconstruction-based similarity measure (reflecting the information loss from signal reconstruction). To efficiently update the object representation, we propose an incremental 3D-DCT algorithm, which decomposes the 3D-DCT into successive operations of the 2D discrete cosine transform (2D-DCT) and 1D discrete cosine transform (1D-DCT) on the input video data.
Non-sparse Linear Representations for Visual Tracking with Online Reservoir Metric Learning
Apr 13, 2012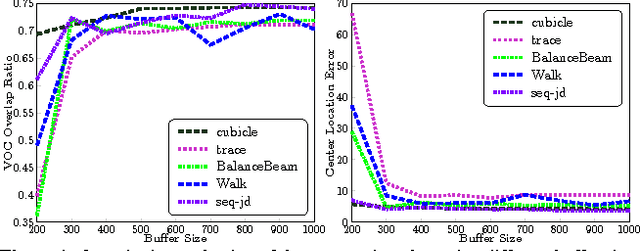
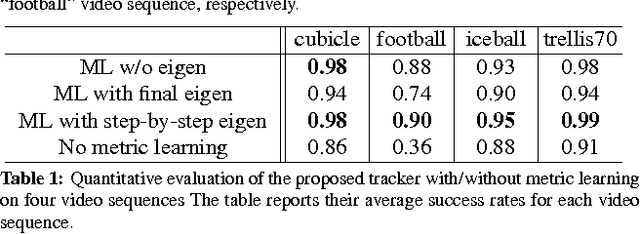
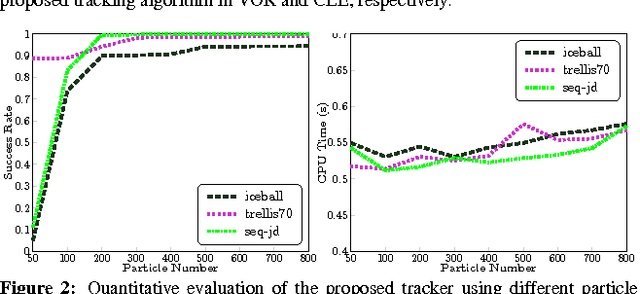
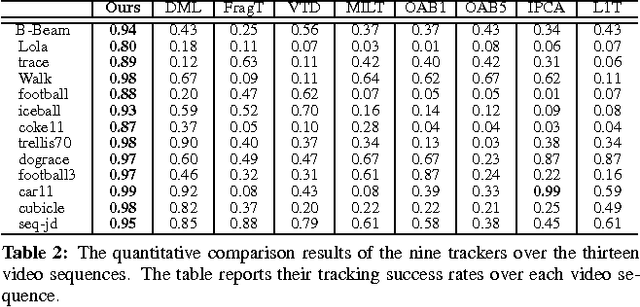
Most sparse linear representation-based trackers need to solve a computationally expensive L1-regularized optimization problem. To address this problem, we propose a visual tracker based on non-sparse linear representations, which admit an efficient closed-form solution without sacrificing accuracy. Moreover, in order to capture the correlation information between different feature dimensions, we learn a Mahalanobis distance metric in an online fashion and incorporate the learned metric into the optimization problem for obtaining the linear representation. We show that online metric learning using proximity comparison significantly improves the robustness of the tracking, especially on those sequences exhibiting drastic appearance changes. Furthermore, in order to prevent the unbounded growth in the number of training samples for the metric learning, we design a time-weighted reservoir sampling method to maintain and update limited-sized foreground and background sample buffers for balancing sample diversity and adaptability. Experimental results on challenging videos demonstrate the effectiveness and robustness of the proposed tracker.