 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Neural Sequence Models Generalize? Local and Global Context Cues for Out-of-Distribution Prediction
Nov 04, 2021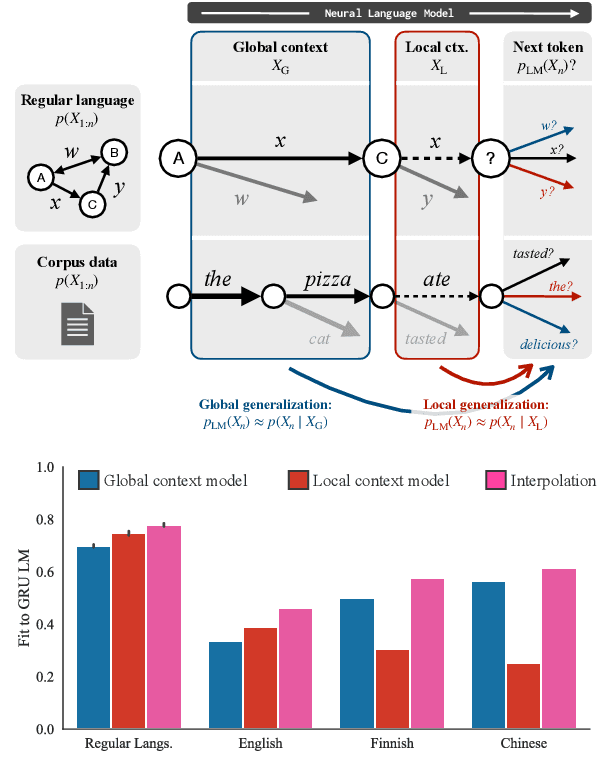
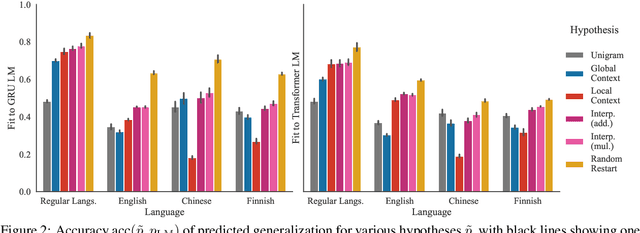
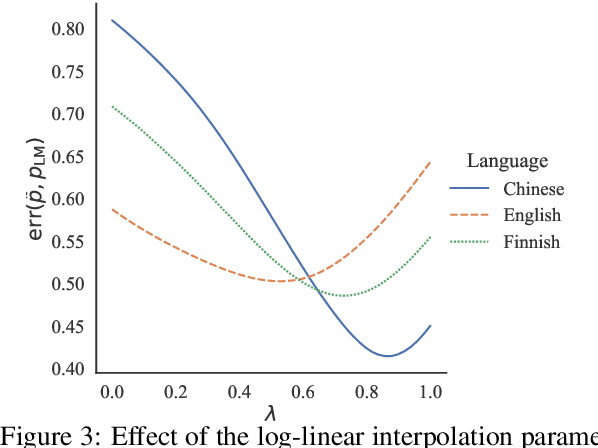
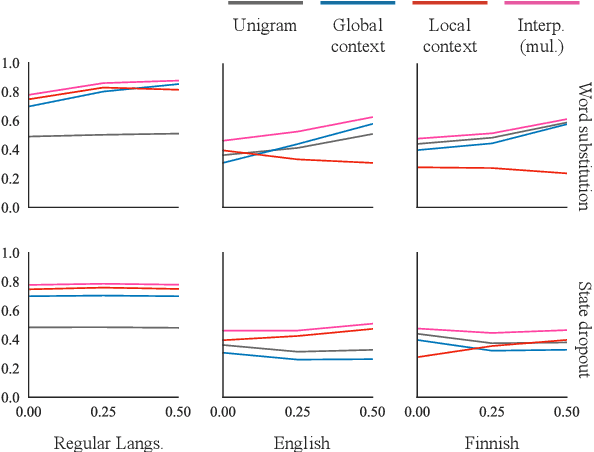
After a neural sequence model encounters an unexpected token, can its behavior be predicted? We show that RNN and transformer language models exhibit structured, consistent generalization in out-of-distribution contexts. We begin by introducing two idealized models of generalization in next-word prediction: a local context model in which generalization is consistent with the last word observed, and a global context model in which generalization is consistent with the global structure of the input. In experiments in English, Finnish, Mandarin, and random regular languages, we demonstrate that neural language models interpolate between these two forms of generalization: their predictions are well-approximated by a log-linear combination of local and global predictive distributions. We then show that, in some languages, noise mediates the two forms of generalization: noise applied to input tokens encourages global generalization, while noise in history representations encourages local generalization. Finally, we offer a preliminary theoretical explanation of these results by proving that the observed interpolation behavior is expected in log-linear models with a particular feature correlation structure. These results help explain the effectiveness of two popular regularization schemes and show that aspects of sequence model generalization can be understood and controlled.
What Is One Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models
Dec 21, 2018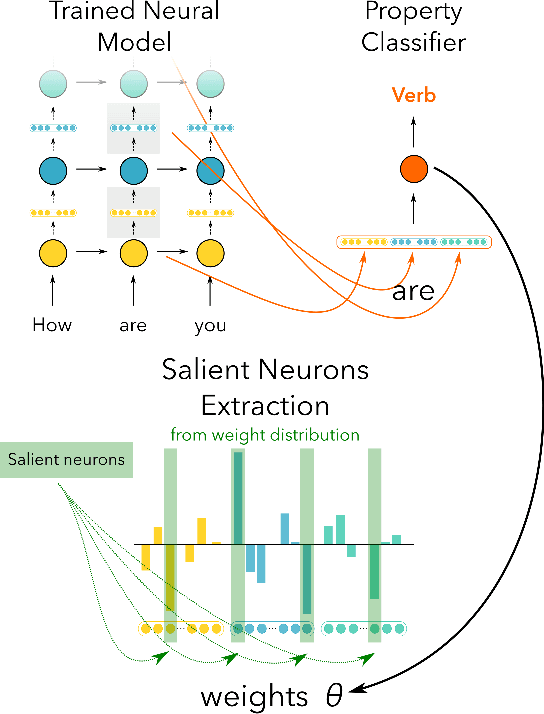
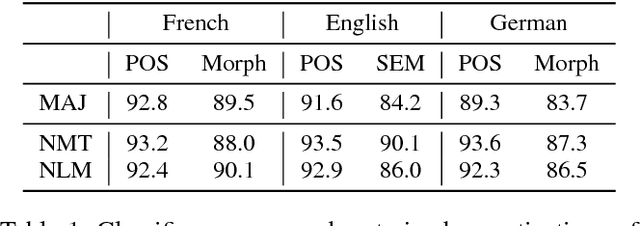

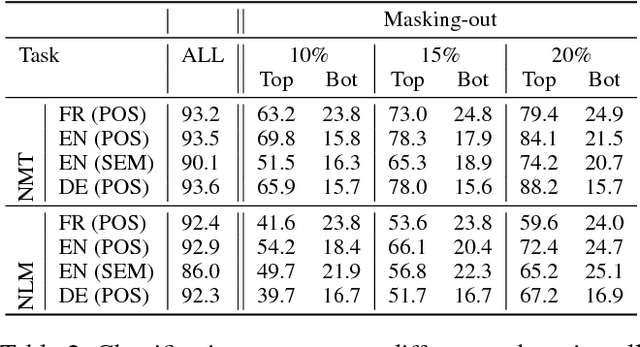
Despite the remarkable evolution of deep neural networks in natural language processing (NLP), their interpretability remains a challenge. Previous work largely focused on what these models learn at the representation level. We break this analysis down further and study individual dimensions (neurons) in the vector representation learned by end-to-end neural models in NLP tasks. We propose two methods: Linguistic Correlation Analysis, based on a supervised method to extract the most relevant neurons with respect to an extrinsic task, and Cross-model Correlation Analysis, an unsupervised method to extract salient neurons w.r.t. the model itself. We evaluate the effectiveness of our techniques by ablating the identified neurons and reevaluating the network's performance for two tasks: neural machine translation (NMT) and neural language modeling (NLM). We further present a comprehensive analysis of neurons with the aim to address the following questions: i) how localized or distributed are different linguistic properties in the models? ii) are certain neurons exclusive to some properties and not others? iii) is the information more or less distributed in NMT vs. NLM? and iv) how important are the neurons identified through the linguistic correlation method to the overall task? Our code is publicly available as part of the NeuroX toolkit (Dalvi et al. 2019).
Identifying and Controlling Important Neurons in Neural Machine Translation
Nov 03, 2018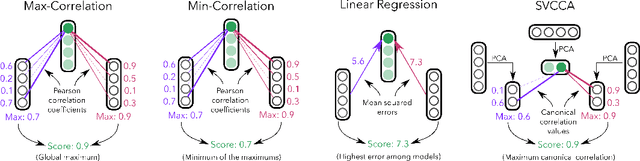
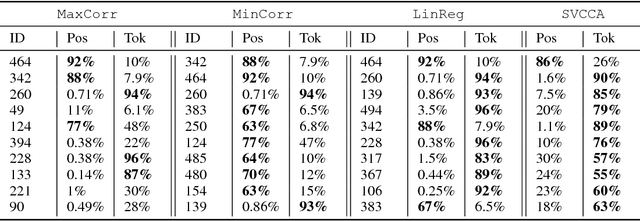
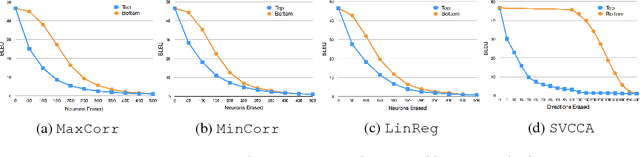
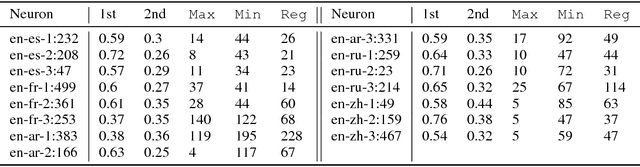
Neural machine translation (NMT) models learn representations containing substantial linguistic information. However, it is not clear if such information is fully distributed or if some of it can be attributed to individual neurons. We develop unsupervised methods for discovering important neurons in NMT models. Our methods rely on the intuition that different models learn similar properties, and do not require any costly external supervision. We show experimentally that translation quality depends on the discovered neurons, and find that many of them capture common linguistic phenomena. Finally, we show how to control NMT translations in predictable ways, by modifying activations of individual neurons.