 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Don't Need Attention: Gated Convolutional Modeling for Watch-Based Fall Detection
May 19, 2026Existing deep learning approaches for wearable fall detection systems rely on self-attention mechanisms that impose quadratic computational overhead, distributing weights across all time steps. This global weight distribution impairs the precise localization of the brief impact signatures that characterize falls within short, fixed-length windows. To overcome this challenge, we propose Gated-CNN, a lightweight dual-stream architecture that processes accelerometer and gyroscope streams through independent one-dimensional convolutional feature extractors, followed by (i) a sigmoid gating module that selectively suppresses uninformative background activations while amplifying fall-discriminative features, (ii) a global average pooling layer that compresses each stream into a compact fixed-length descriptor, and (iii) a shared classification head that fuses both descriptors for binary fall prediction. For offline evaluation, we evaluate the model across five wrist-mounted inertial measurement unit (IMU) datasets, achieving average F1-scores of 93%, 93%, 90%, 91%, and 90% on SmartFallMM, WEDA-Fall, FallAllD, UMAFall, and UP-Fall, outperforming Transformer baselines. For real-time evaluation, we deployed the model on a Google Pixel Watch 3 and tested across 12 participants. The model achieves an average F1-score of 97% and an accuracy of 98% with zero missed falls, showing that sigmoid gating offers a more structurally aligned and computationally efficient alternative to attention for commodity smartwatch-based fall detection.
Personalized Fall Detection by Balancing Data with Selective Feedback Using Contrastive Learning
Mar 17, 2026Personalized fall detection models can significantly improve accuracy by adapting to individual motion patterns, yet their effectiveness is often limited by the scarcity of real-world fall data and the dominance of non-fall feedback samples. This imbalance biases the model toward routine activities and weakens its sensitivity to true fall events. To address this challenge, we propose a personalization framework that combines semi-supervised clustering with contrastive learning to identify and balance the most informative user feedback samples. The framework is evaluated under three retraining strategies, including Training from Scratch (TFS), Transfer Learning (TL), and Few-Shot Learning (FSL), to assess adaptability across learning paradigms. Real-time experiments with ten participants show that the TFS approach achieves the highest performance, with up to a 25% improvement over the baseline, while FSL achieves the second-highest performance with a 7% improvement, demonstrating the effectiveness of selective personalization for real-world deployment.
TransConv-DDPM: Enhanced Diffusion Model for Generating Time-Series Data in Healthcare
Feb 03, 2026The lack of real-world data in clinical fields poses a major obstacle in training effective AI models for diagnostic and preventive tools in medicine. Generative AI has shown promise in increasing data volume and enhancing model training, particularly in computer vision and natural language processing (NLP) domains. However, generating physiological time-series data, a common type in medical AI applications, presents unique challenges due to its inherent complexity and variability. This paper introduces TransConv-DDPM, an enhanced generative AI method for biomechanical and physiological time-series data generation. The model employs a denoising diffusion probabilistic model (DDPM) with U-Net, multi-scale convolution modules, and a transformer layer to capture both global and local temporal dependencies. We evaluated TransConv-DDPM on three diverse datasets, generating both long and short-sequence time-series data. Quantitative comparisons against state-of-the-art methods, TimeGAN and Diffusion-TS, using four performance metrics, demonstrated promising results, particularly on the SmartFallMM and EEG datasets, where it effectively captured the more gradual temporal change patterns between data points. Additionally, a utility test on the SmartFallMM dataset revealed that adding synthetic fall data generated by TransConv-DDPM improved predictive model performance, showing a 13.64% improvement in F1-score and a 14.93% increase in overall accuracy compared to the baseline model trained solely on fall data from the SmartFallMM dataset. These findings highlight the potential of TransConv-DDPM to generate high-quality synthetic data for real-world applications.
* Previously published at IEEE COMPSAC 2025
AI-Generated Fall Data: Assessing LLMs and Diffusion Model for Wearable Fall Detection
May 07, 2025



Training fall detection systems is challenging due to the scarcity of real-world fall data, particularly from elderly individuals. To address this, we explore the potential of Large Language Models (LLMs) for generating synthetic fall data. This study evaluates text-to-motion (T2M, SATO, ParCo) and text-to-text models (GPT4o, GPT4, Gemini) in simulating realistic fall scenarios. We generate synthetic datasets and integrate them with four real-world baseline datasets to assess their impact on fall detection performance using a Long Short-Term Memory (LSTM) model. Additionally, we compare LLM-generated synthetic data with a diffusion-based method to evaluate their alignment with real accelerometer distributions. Results indicate that dataset characteristics significantly influence the effectiveness of synthetic data, with LLM-generated data performing best in low-frequency settings (e.g., 20Hz) while showing instability in high-frequency datasets (e.g., 200Hz). While text-to-motion models produce more realistic biomechanical data than text-to-text models, their impact on fall detection varies. Diffusion-based synthetic data demonstrates the closest alignment to real data but does not consistently enhance model performance. An ablation study further confirms that the effectiveness of synthetic data depends on sensor placement and fall representation. These findings provide insights into optimizing synthetic data generation for fall detection models.
A Survey on Multimodal Wearable Sensor-based Human Action Recognition
Apr 14, 2024



The combination of increased life expectancy and falling birth rates is resulting in an aging population. Wearable Sensor-based Human Activity Recognition (WSHAR) emerges as a promising assistive technology to support the daily lives of older individuals, unlocking vast potential for human-centric applications. However, recent surveys in WSHAR have been limited, focusing either solely on deep learning approaches or on a single sensor modality. In real life, our human interact with the world in a multi-sensory way, where diverse information sources are intricately processed and interpreted to accomplish a complex and unified sensing system. To give machines similar intelligence, multimodal machine learning, which merges data from various sources, has become a popular research area with recent advancements. In this study, we present a comprehensive survey from a novel perspective on how to leverage multimodal learning to WSHAR domain for newcomers and researchers. We begin by presenting the recent sensor modalities as well as deep learning approaches in HAR. Subsequently, we explore the techniques used in present multimodal systems for WSHAR. This includes inter-multimodal systems which utilize sensor modalities from both visual and non-visual systems and intra-multimodal systems that simply take modalities from non-visual systems. After that, we focus on current multimodal learning approaches that have applied to solve some of the challenges existing in WSHAR. Specifically, we make extra efforts by connecting the existing multimodal literature from other domains, such as computer vision and natural language processing, with current WSHAR area. Finally, we identify the corresponding challenges and potential research direction in current WSHAR area for further improvement.
Progressive Cross-modal Knowledge Distillation for Human Action Recognition
Aug 17, 2022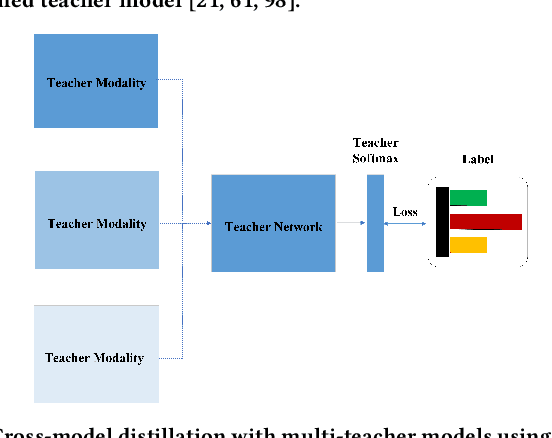
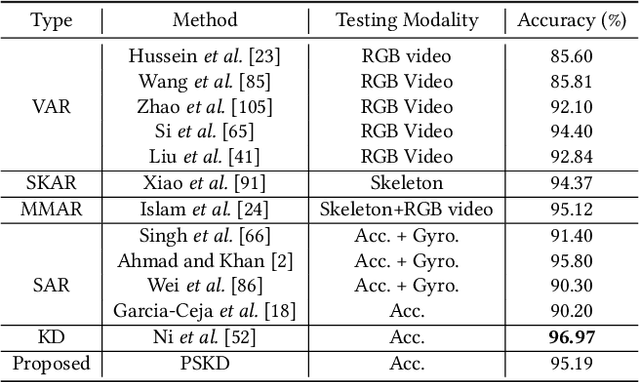
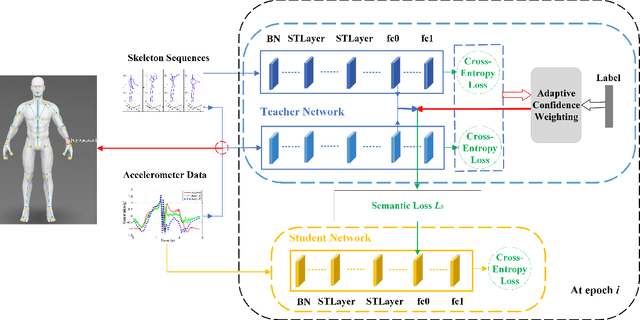
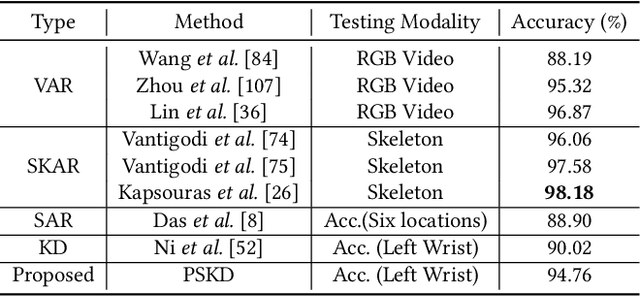
Wearable sensor-based Human Action Recognition (HAR) has achieved remarkable success recently. However, the accuracy performance of wearable sensor-based HAR is still far behind the ones from the visual modalities-based system (i.e., RGB video, skeleton, and depth). Diverse input modalities can provide complementary cues and thus improve the accuracy performance of HAR, but how to take advantage of multi-modal data on wearable sensor-based HAR has rarely been explored. Currently, wearable devices, i.e., smartwatches, can only capture limited kinds of non-visual modality data. This hinders the multi-modal HAR association as it is unable to simultaneously use both visual and non-visual modality data. Another major challenge lies in how to efficiently utilize multimodal data on wearable devices with their limited computation resources. In this work, we propose a novel Progressive Skeleton-to-sensor Knowledge Distillation (PSKD) model which utilizes only time-series data, i.e., accelerometer data, from a smartwatch for solving the wearable sensor-based HAR problem. Specifically, we construct multiple teacher models using data from both teacher (human skeleton sequence) and student (time-series accelerometer data) modalities. In addition, we propose an effective progressive learning scheme to eliminate the performance gap between teacher and student models. We also designed a novel loss function called Adaptive-Confidence Semantic (ACS), to allow the student model to adaptively select either one of the teacher models or the ground-truth label it needs to mimic. To demonstrate the effectiveness of our proposed PSKD method, we conduct extensive experiments on Berkeley-MHAD, UTD-MHAD, and MMAct datasets. The results confirm that the proposed PSKD method has competitive performance compared to the previous mono sensor-based HAR methods.