 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutliers Dimensions that Disrupt Transformers Are Driven by Frequency
May 23, 2022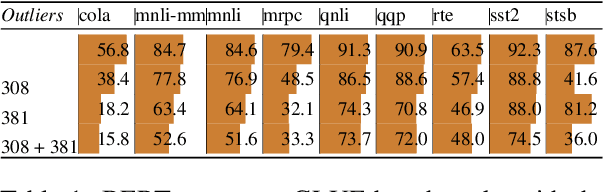
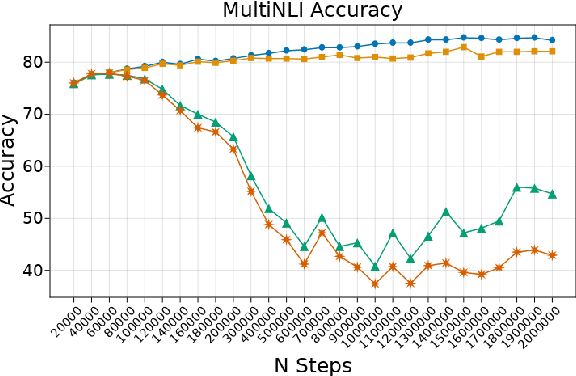
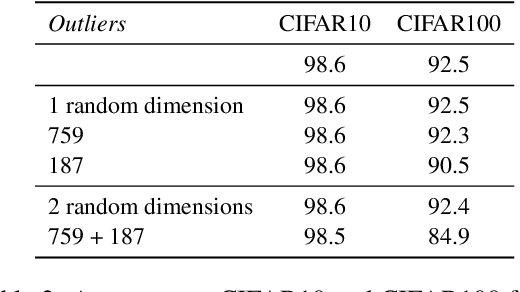
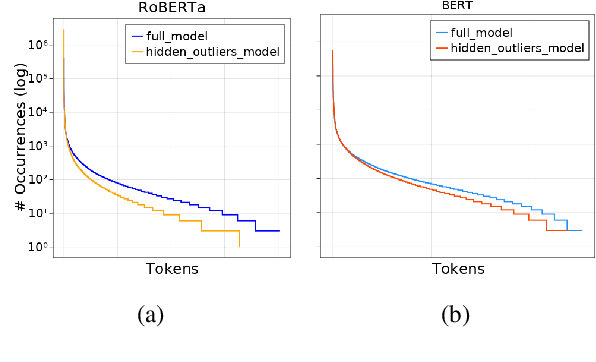
Transformer-based language models are known to display anisotropic behavior: the token embeddings are not homogeneously spread in space, but rather accumulate along certain directions. A related recent finding is the outlier phenomenon: the parameters in the final element of Transformer layers that consistently have unusual magnitude in the same dimension across the model, and significantly degrade its performance if disabled. We replicate the evidence for the outlier phenomenon and we link it to the geometry of the embedding space. Our main finding is that in both BERT and RoBERTa the token frequency, known to contribute to anisotropicity, also contributes to the outlier phenomenon. In its turn, the outlier phenomenon contributes to the "vertical" self-attention pattern that enables the model to focus on the special tokens. We also find that, surprisingly, the outlier effect on the model performance varies by layer, and that variance is also related to the correlation between outlier magnitude and encoded token frequency.
What Factors Should Paper-Reviewer Assignments Rely On? Community Perspectives on Issues and Ideals in Conference Peer-Review
May 03, 2022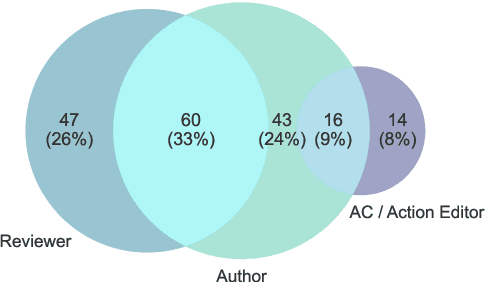
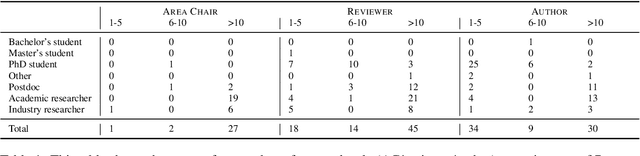
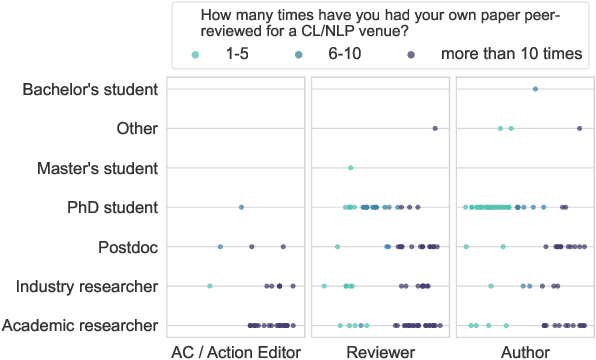

Both scientific progress and individual researcher careers depend on the quality of peer review, which in turn depends on paper-reviewer matching. Surprisingly, this problem has been mostly approached as an automated recommendation problem rather than as a matter where different stakeholders (area chairs, reviewers, authors) have accumulated experience worth taking into account. We present the results of the first survey of the NLP community, identifying common issues and perspectives on what factors should be considered by paper-reviewer matching systems. This study contributes actionable recommendations for improving future NLP conferences, and desiderata for interpretable peer review assignments.
Generalization in NLI: Ways To Go Beyond Simple Heuristics
Oct 04, 2021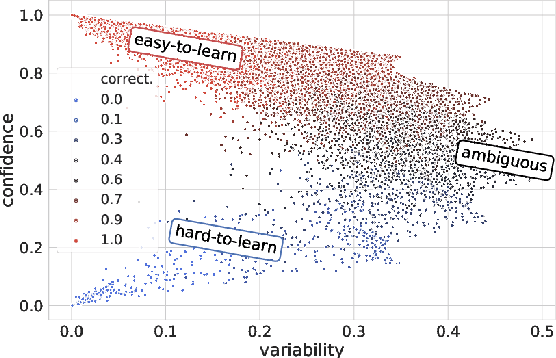
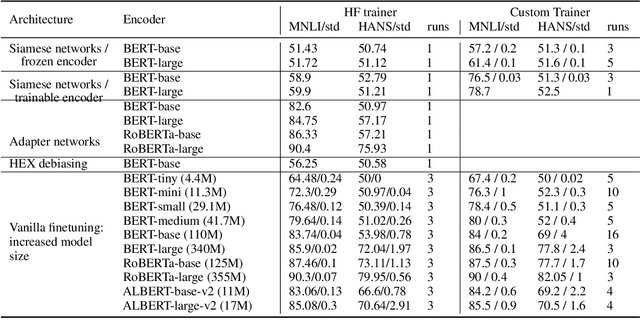
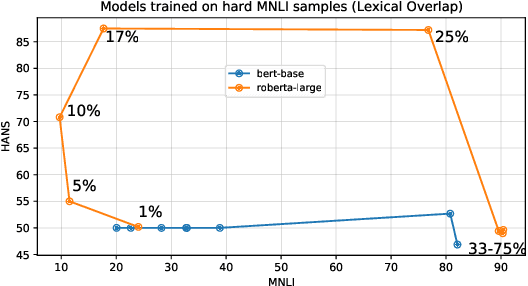
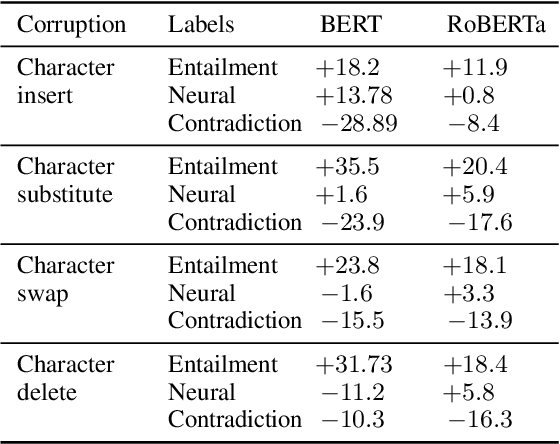
Much of recent progress in NLU was shown to be due to models' learning dataset-specific heuristics. We conduct a case study of generalization in NLI (from MNLI to the adversarially constructed HANS dataset) in a range of BERT-based architectures (adapters, Siamese Transformers, HEX debiasing), as well as with subsampling the data and increasing the model size. We report 2 successful and 3 unsuccessful strategies, all providing insights into how Transformer-based models learn to generalize.
Just What do You Think You're Doing, Dave?' A Checklist for Responsible Data Use in NLP
Sep 14, 2021

A key part of the NLP ethics movement is responsible use of data, but exactly what that means or how it can be best achieved remain unclear. This position paper discusses the core legal and ethical principles for collection and sharing of textual data, and the tensions between them. We propose a potential checklist for responsible data (re-)use that could both standardise the peer review of conference submissions, as well as enable a more in-depth view of published research across the community. Our proposal aims to contribute to the development of a consistent standard for data (re-)use, embraced across NLP conferences.
QA Dataset Explosion: A Taxonomy of NLP Resources for Question Answering and Reading Comprehension
Jul 27, 2021


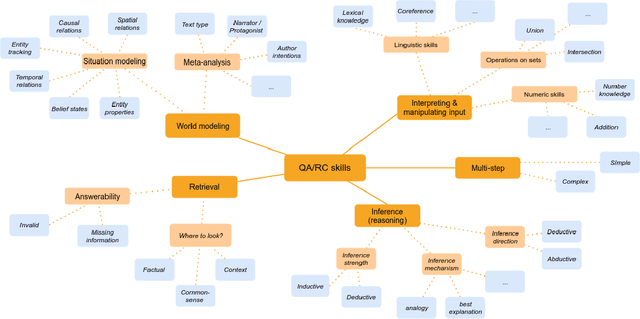
Alongside huge volumes of research on deep learning models in NLP in the recent years, there has been also much work on benchmark datasets needed to track modeling progress. Question answering and reading comprehension have been particularly prolific in this regard, with over 80 new datasets appearing in the past two years. This study is the largest survey of the field to date. We provide an overview of the various formats and domains of the current resources, highlighting the current lacunae for future work. We further discuss the current classifications of ``reasoning types" in question answering and propose a new taxonomy. We also discuss the implications of over-focusing on English, and survey the current monolingual resources for other languages and multilingual resources. The study is aimed at both practitioners looking for pointers to the wealth of existing data, and at researchers working on new resources.
On the Interaction of Belief Bias and Explanations
Jun 29, 2021
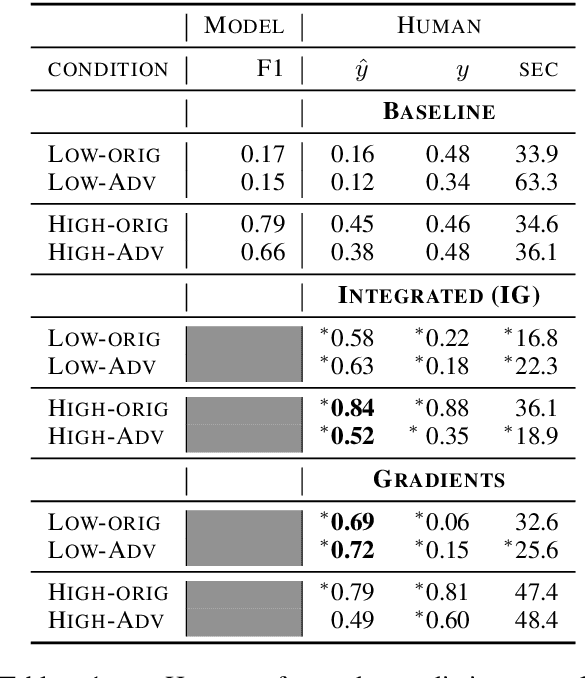

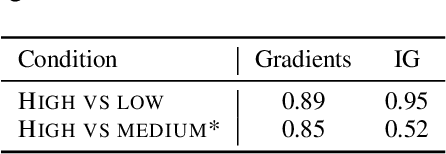
A myriad of explainability methods have been proposed in recent years, but there is little consensus on how to evaluate them. While automatic metrics allow for quick benchmarking, it isn't clear how such metrics reflect human interaction with explanations. Human evaluation is of paramount importance, but previous protocols fail to account for belief biases affecting human performance, which may lead to misleading conclusions. We provide an overview of belief bias, its role in human evaluation, and ideas for NLP practitioners on how to account for it. For two experimental paradigms, we present a case study of gradient-based explainability introducing simple ways to account for humans' prior beliefs: models of varying quality and adversarial examples. We show that conclusions about the highest performing methods change when introducing such controls, pointing to the importance of accounting for belief bias in evaluation.
BERT Busters: Outlier Dimensions that Disrupt Transformers
Jun 02, 2021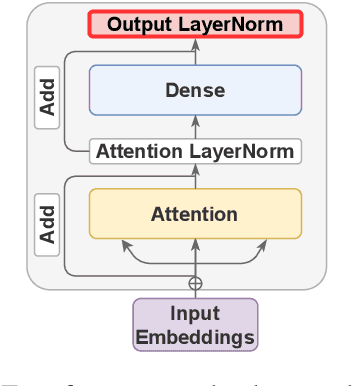

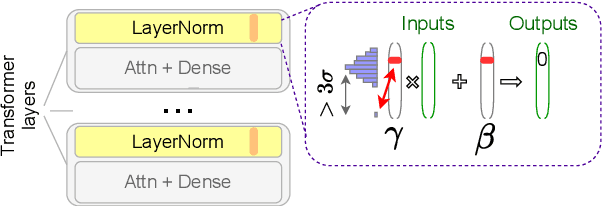
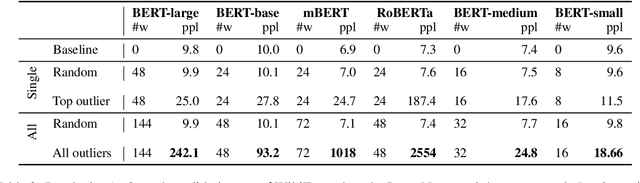
Multiple studies have shown that Transformers are remarkably robust to pruning. Contrary to this received wisdom, we demonstrate that pre-trained Transformer encoders are surprisingly fragile to the removal of a very small number of features in the layer outputs (<0.0001% of model weights). In case of BERT and other pre-trained encoder Transformers, the affected component is the scaling factors and biases in the LayerNorm. The outliers are high-magnitude normalization parameters that emerge early in pre-training and show up consistently in the same dimensional position throughout the model. We show that disabling them significantly degrades both the MLM loss and the downstream task performance. This effect is observed across several BERT-family models and other popular pre-trained Transformer architectures, including BART, XLNet and ELECTRA; we also show a similar effect in GPT-2.
Changing the World by Changing the Data
May 28, 2021NLP community is currently investing a lot more research and resources into development of deep learning models than training data. While we have made a lot of progress, it is now clear that our models learn all kinds of spurious patterns, social biases, and annotation artifacts. Algorithmic solutions have so far had limited success. An alternative that is being actively discussed is more careful design of datasets so as to deliver specific signals. This position paper maps out the arguments for and against data curation, and argues that fundamentally the point is moot: curation already is and will be happening, and it is changing the world. The question is only how much thought we want to invest into that process.
What Can We Do to Improve Peer Review in NLP?
Oct 08, 2020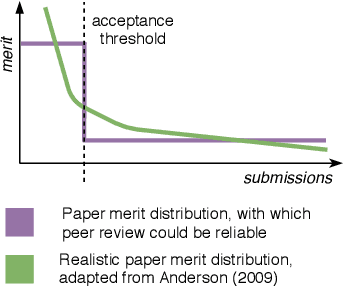
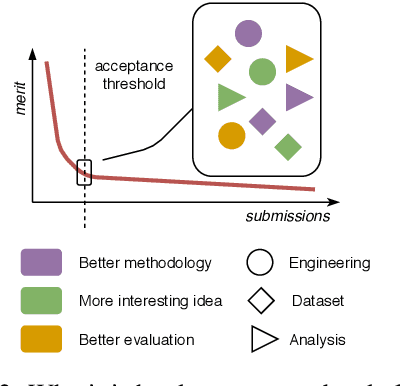
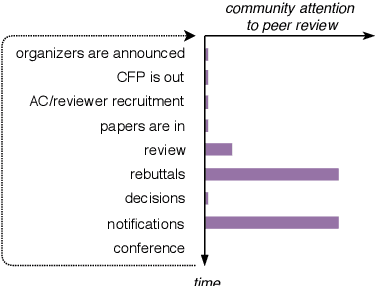
Peer review is our best tool for judging the quality of conference submissions, but it is becoming increasingly spurious. We argue that a part of the problem is that the reviewers and area chairs face a poorly defined task forcing apples-to-oranges comparisons. There are several potential ways forward, but the key difficulty is creating the incentives and mechanisms for their consistent implementation in the NLP community.
When BERT Plays the Lottery, All Tickets Are Winning
May 01, 2020
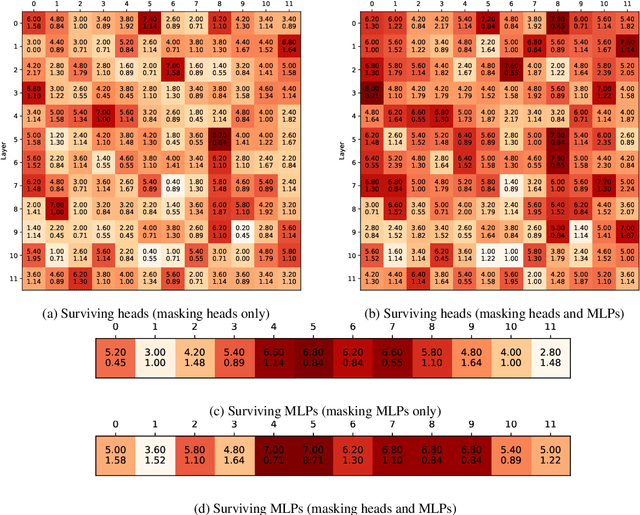
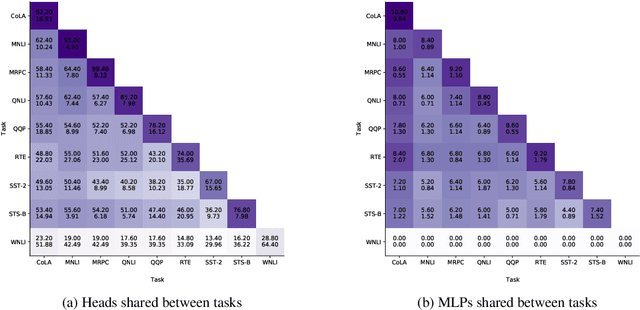
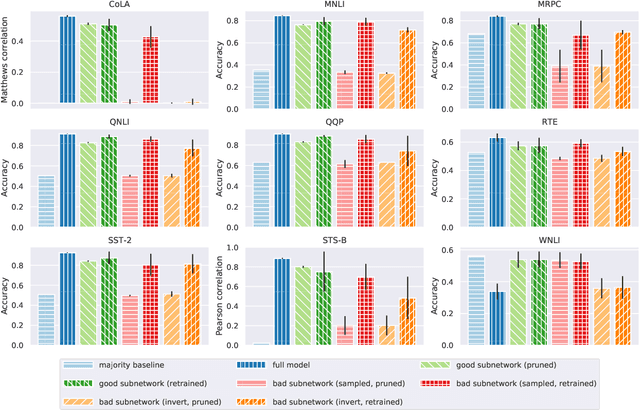
Much of the recent success in NLP is due to the large Transformer-based models such as BERT (Devlin et al, 2019). However, these models have been shown to be reducible to a smaller number of self-attention heads and layers. We consider this phenomenon from the perspective of the lottery ticket hypothesis. For fine-tuned BERT, we show that (a) it is possible to find a subnetwork of elements that achieves performance comparable with that of the full model, and (b) similarly-sized subnetworks sampled from the rest of the model perform worse. However, the "bad" subnetworks can be fine-tuned separately to achieve only slightly worse performance than the "good" ones, indicating that most weights in the pre-trained BERT are potentially useful. We also show that the "good" subnetworks vary considerably across GLUE tasks, opening up the possibilities to learn what knowledge BERT actually uses at inference time.