 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect simultaneous speech to speech translation
Oct 15, 2021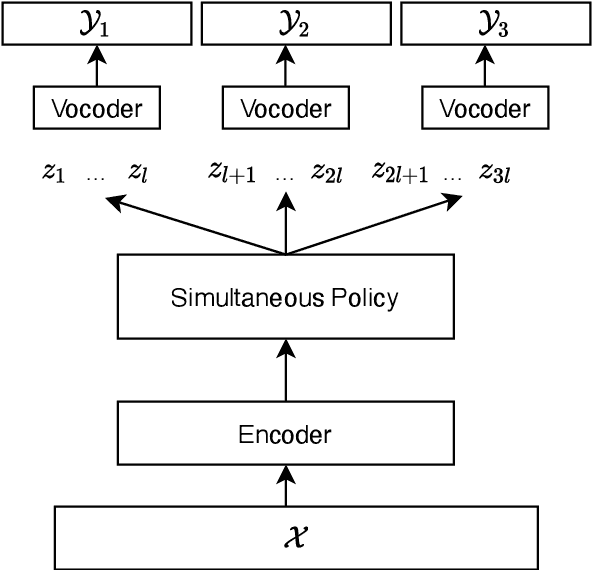
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Sep 14, 2021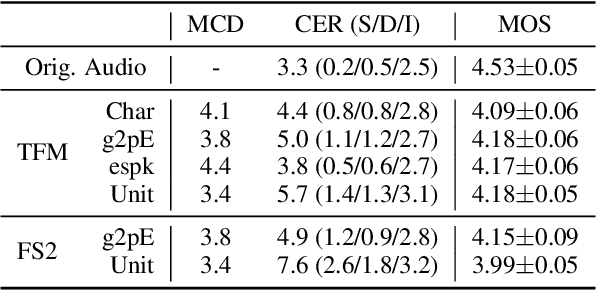
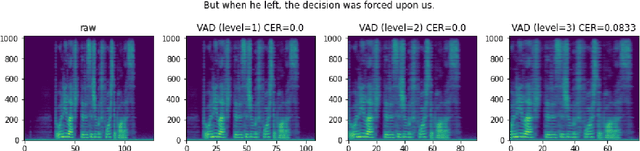

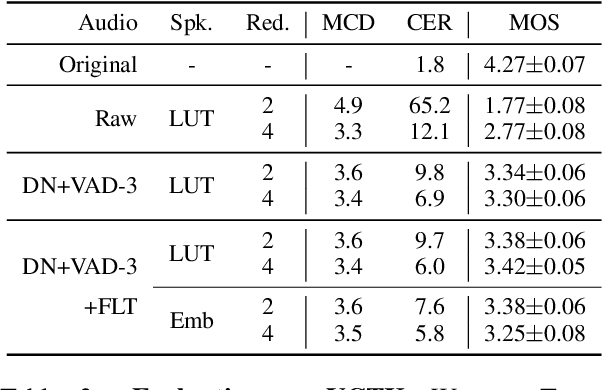
This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework. The code, documentation, and pre-trained models are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_synthesis.
Text-Free Prosody-Aware Generative Spoken Language Modeling
Sep 07, 2021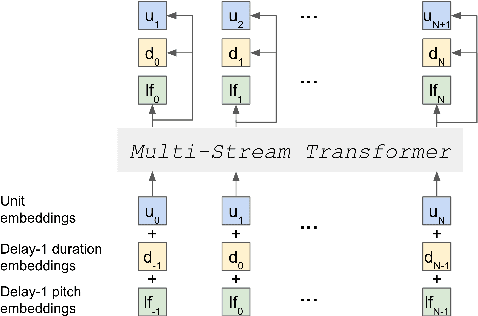
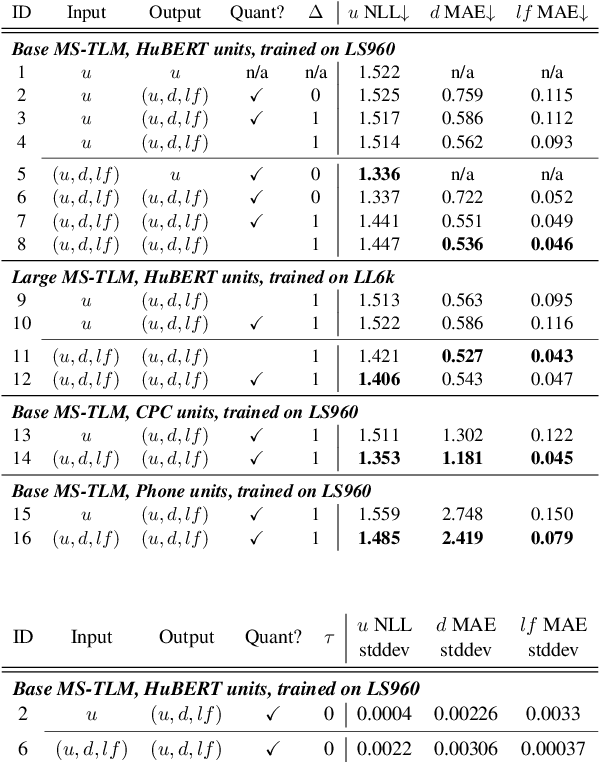
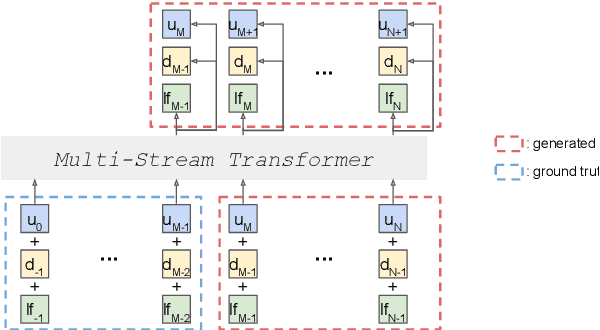
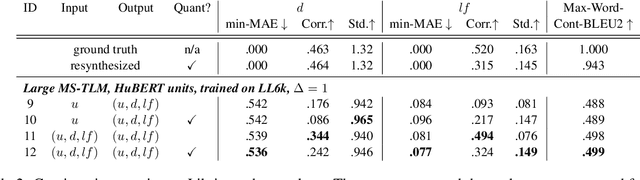
Speech pre-training has primarily demonstrated efficacy on classification tasks, while its capability of generating novel speech, similar to how GPT-2 can generate coherent paragraphs, has barely been explored. Generative Spoken Language Modeling (GSLM) (Lakhotia et al., 2021) is the only prior work addressing the generative aspects of speech pre-training, which replaces text with discovered phone-like units for language modeling and shows the ability to generate meaningful novel sentences. Unfortunately, despite eliminating the need of text, the units used in GSLM discard most of the prosodic information. Hence, GSLM fails to leverage prosody for better comprehension, and does not generate expressive speech. In this work, we present a prosody-aware generative spoken language model (pGSLM). It is composed of a multi-stream transformer language model (MS-TLM) of speech, represented as discovered unit and prosodic feature streams, and an adapted HiFi-GAN model converting MS-TLM outputs to waveforms. We devise a series of metrics for prosody modeling and generation, and re-use metrics from GSLM for content modeling. Experimental results show that the pGSLM can utilize prosody to improve both prosody and content modeling, and also generate natural, meaningful, and coherent speech given a spoken prompt. Audio samples can be found at https://speechbot.github.io/pgslm.
Direct speech-to-speech translation with discrete units
Jul 12, 2021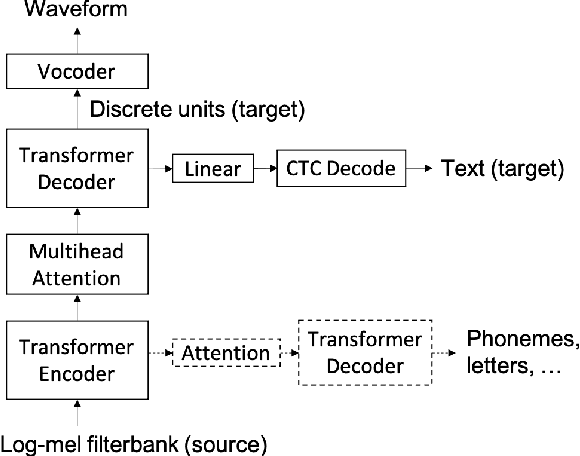
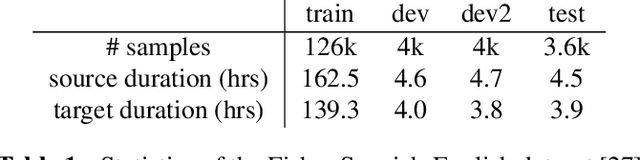
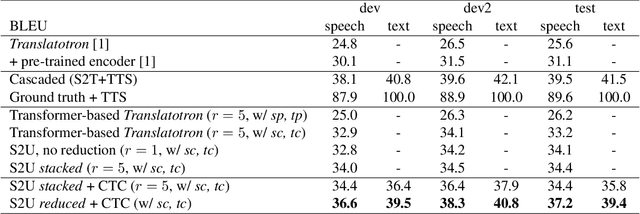
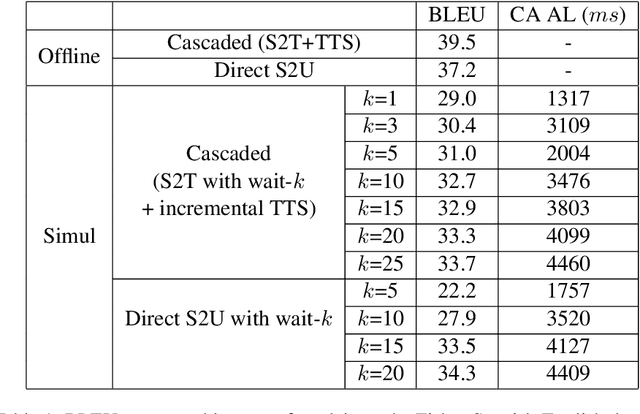
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.
Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
Apr 02, 2021
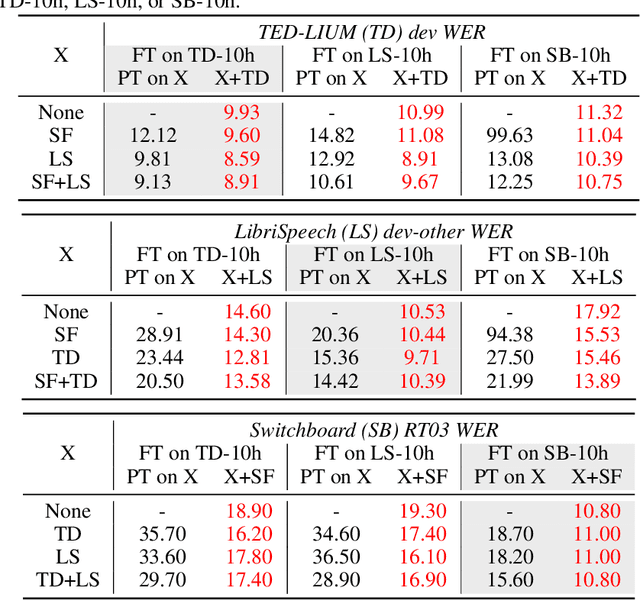
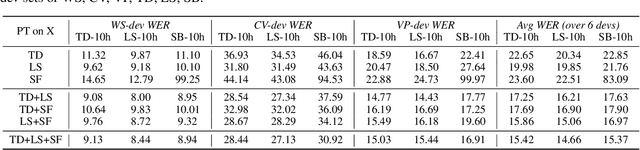
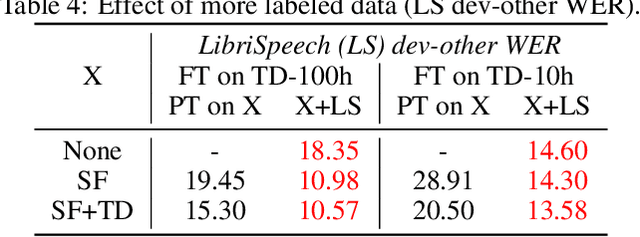
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at https://github.com/pytorch/fairseq.
VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021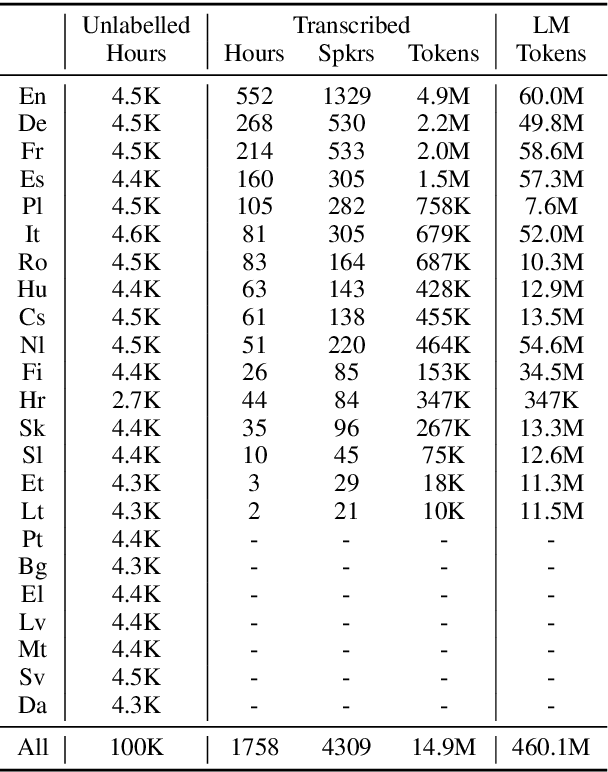
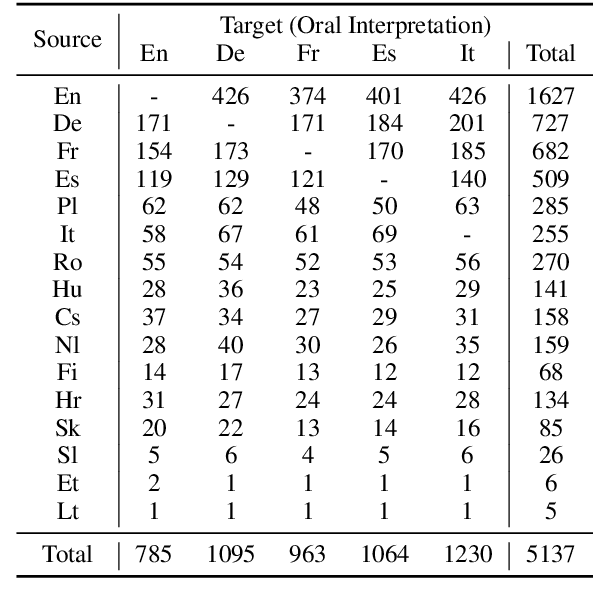

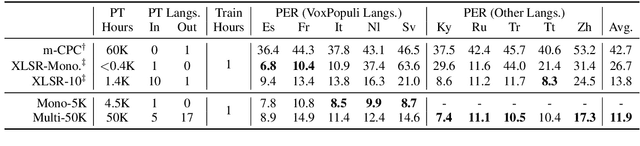
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
Few-shot Sequence Learning with Transformers
Dec 17, 2020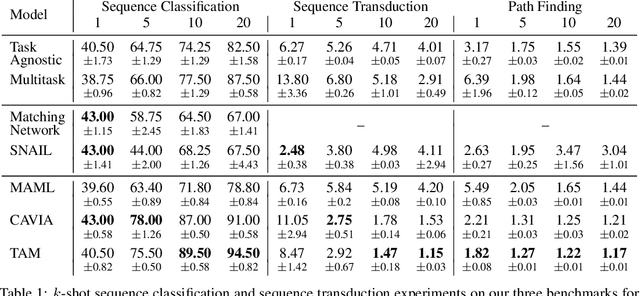
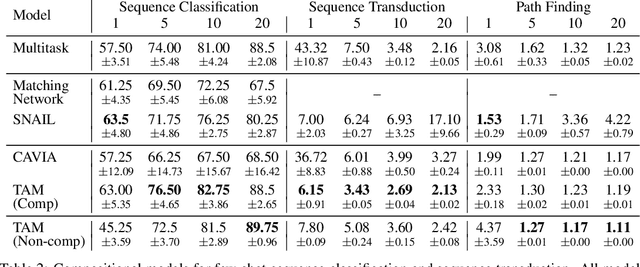
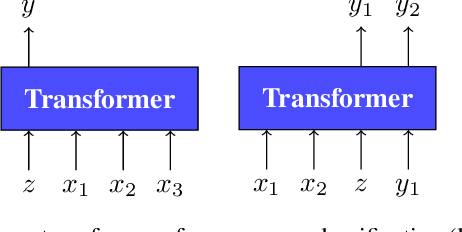
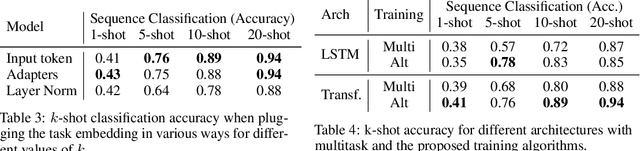
Few-shot algorithms aim at learning new tasks provided only a handful of training examples. In this work we investigate few-shot learning in the setting where the data points are sequences of tokens and propose an efficient learning algorithm based on Transformers. In the simplest setting, we append a token to an input sequence which represents the particular task to be undertaken, and show that the embedding of this token can be optimized on the fly given few labeled examples. Our approach does not require complicated changes to the model architecture such as adapter layers nor computing second order derivatives as is currently popular in the meta-learning and few-shot learning literature. We demonstrate our approach on a variety of tasks, and analyze the generalization properties of several model variants and baseline approaches. In particular, we show that compositional task descriptors can improve performance. Experiments show that our approach works at least as well as other methods, while being more computationally efficient.
Facebook AI's WMT20 News Translation Task Submission
Nov 16, 2020

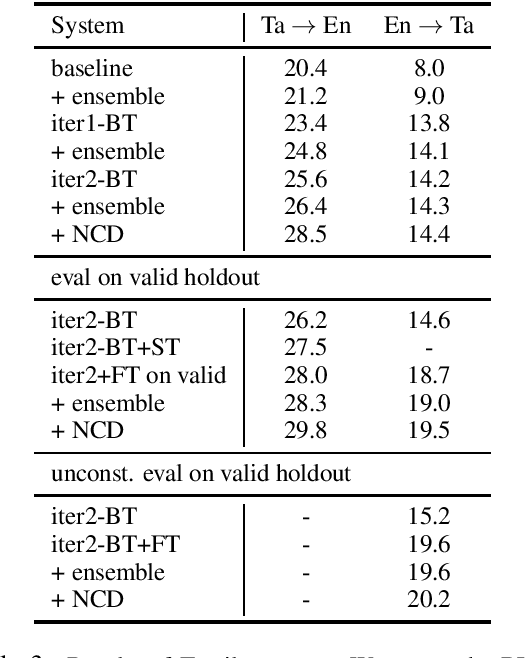
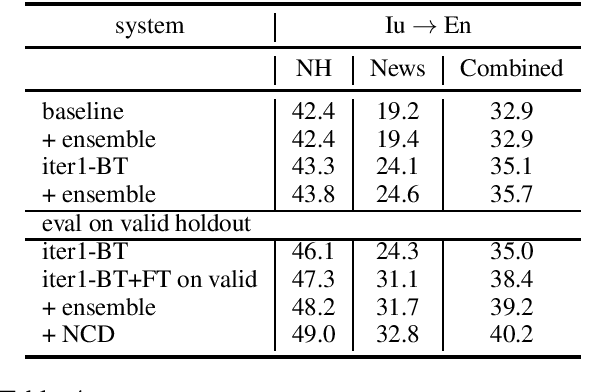
This paper describes Facebook AI's submission to WMT20 shared news translation task. We focus on the low resource setting and participate in two language pairs, Tamil <-> English and Inuktitut <-> English, where there are limited out-of-domain bitext and monolingual data. We approach the low resource problem using two main strategies, leveraging all available data and adapting the system to the target news domain. We explore techniques that leverage bitext and monolingual data from all languages, such as self-supervised model pretraining, multilingual models, data augmentation, and reranking. To better adapt the translation system to the test domain, we explore dataset tagging and fine-tuning on in-domain data. We observe that different techniques provide varied improvements based on the available data of the language pair. Based on the finding, we integrate these techniques into one training pipeline. For En->Ta, we explore an unconstrained setup with additional Tamil bitext and monolingual data and show that further improvement can be obtained. On the test set, our best submitted systems achieve 21.5 and 13.7 BLEU for Ta->En and En->Ta respectively, and 27.9 and 13.0 for Iu->En and En->Iu respectively.
Semi-Supervised Speech Recognition via Local Prior Matching
Feb 24, 2020
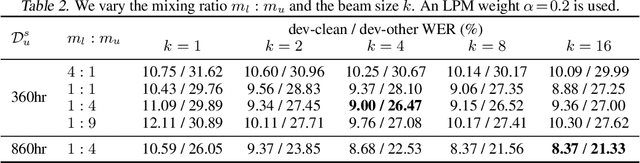
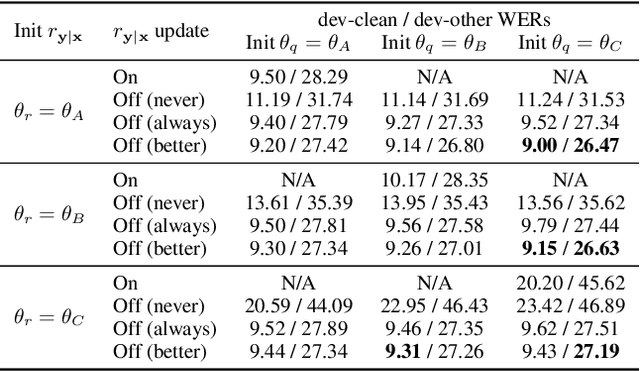
For sequence transduction tasks like speech recognition, a strong structured prior model encodes rich information about the target space, implicitly ruling out invalid sequences by assigning them low probability. In this work, we propose local prior matching (LPM), a semi-supervised objective that distills knowledge from a strong prior (e.g. a language model) to provide learning signal to a discriminative model trained on unlabeled speech. We demonstrate that LPM is theoretically well-motivated, simple to implement, and superior to existing knowledge distillation techniques under comparable settings. Starting from a baseline trained on 100 hours of labeled speech, with an additional 360 hours of unlabeled data, LPM recovers 54% and 73% of the word error rate on clean and noisy test sets relative to a fully supervised model on the same data.
Self-Training for End-to-End Speech Recognition
Sep 19, 2019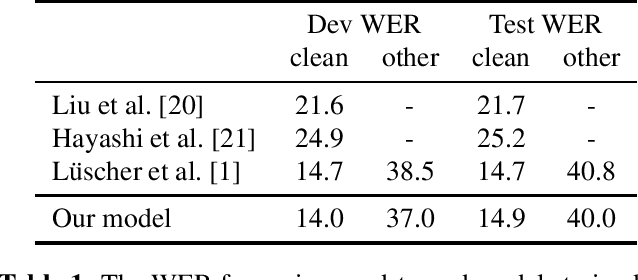
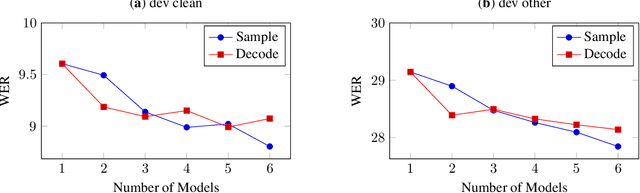
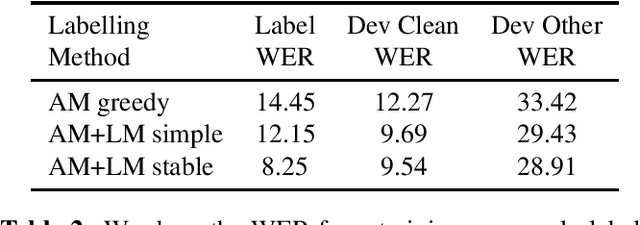
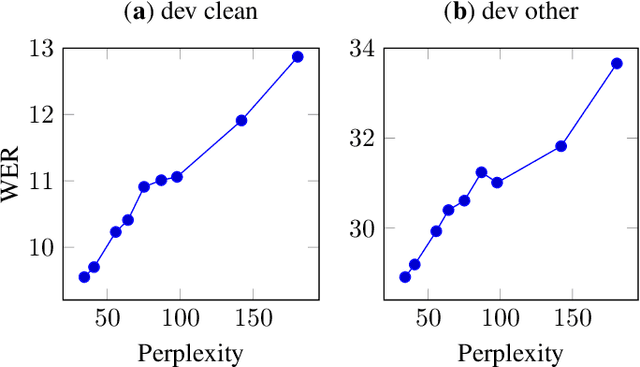
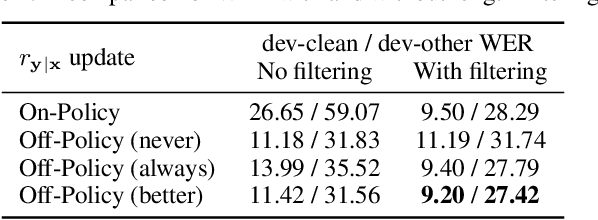
We revisit self-training in the context of end-to-end speech recognition. We demonstrate that training with pseudo-labels can substantially improve the accuracy of a baseline model by leveraging unlabelled data. Key to our approach are a strong baseline acoustic and language model used to generate the pseudo-labels, a robust and stable beam-search decoder, and a novel ensemble approach used to increase pseudo-label diversity. Experiments on the LibriSpeech corpus show that self-training with a single model can yield a 21% relative WER improvement on clean data over a baseline trained on 100 hours of labelled data. We also evaluate label filtering approaches to increase pseudo-label quality. With an ensemble of six models in conjunction with label filtering, self-training yields a 26% relative improvement and bridges 55.6% of the gap between the baseline and an oracle model trained with all of the labels.