 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossTransformers: spatially-aware few-shot transfer
Jul 23, 2020
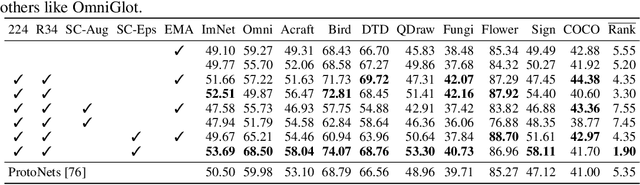
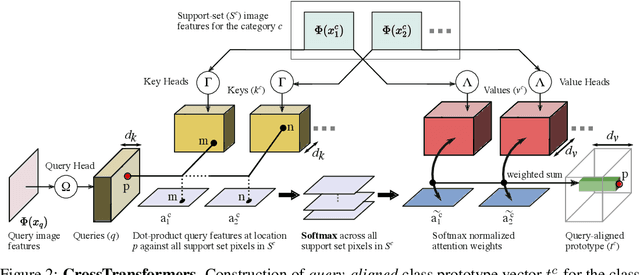
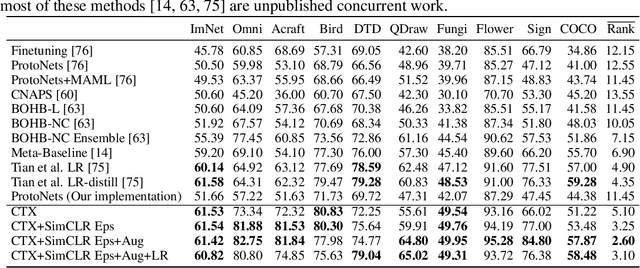
Given new tasks with very little data--such as new classes in a classification problem or a domain shift in the input--performance of modern vision systems degrades remarkably quickly. In this work, we illustrate how the neural network representations which underpin modern vision systems are subject to supervision collapse, whereby they lose any information that is not necessary for performing the training task, including information that may be necessary for transfer to new tasks or domains. We then propose two methods to mitigate this problem. First, we employ self-supervised learning to encourage general-purpose features that transfer better. Second, we propose a novel Transformer based neural network architecture called CrossTransformers, which can take a small number of labeled images and an unlabeled query, find coarse spatial correspondence between the query and the labeled images, and then infer class membership by computing distances between spatially-corresponding features. The result is a classifier that is more robust to task and domain shift, which we demonstrate via state-of-the-art performance on Meta-Dataset, a recent dataset for evaluating transfer from ImageNet to many other vision datasets.
Compliance Change Tracking in Business Process Services
Aug 20, 2019
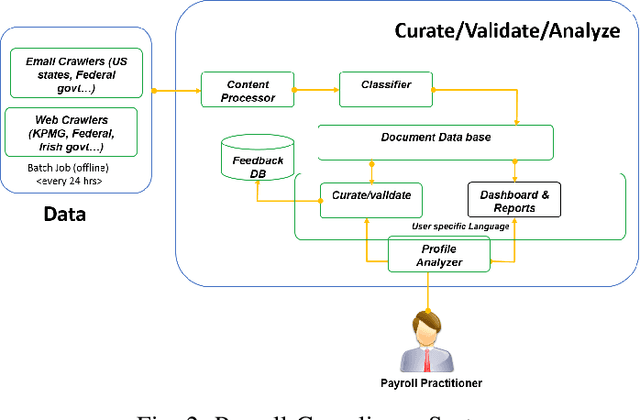
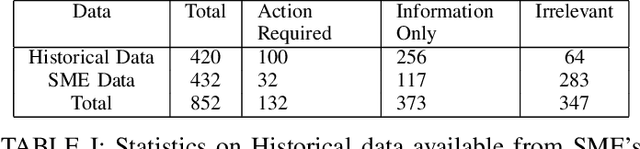

Regulatory compliance is an organization's adherence to laws, regulations, guidelines and specifications relevant to its business. Compliance officers responsible for maintaining adherence constantly struggle to keep up with the large amount of changes in regulatory requirements. Keeping up with the changes entail two main tasks: fetching the regulatory announcements that actually contain changes of interest, and incorporating those changes in the business process. In this paper we focus on the first task, and present a Compliance Change Tracking System, that gathers regulatory announcements from government sites, news sites, email subscriptions; classifies their importance i.e Actionability through a hierarchical classifier, and business process applicability through a multi-class classifier. For these classifiers, we experiment with several approaches such as vanilla classification methods (e.g. Naive Bayes, logistic regression etc.), hierarchical classification methods, rule based approach, hybrid approach with various preprocessing and feature selection methods; and show that despite the richness of other models, a simple hierarchical classification with bag-of-words features works the best for Actionability classifier and multi-class logistic regression works the best for Applicability classifier. The system has been deployed in global delivery centers, and has received positive feedback from payroll compliance officers.
Learning Landmarks from Unaligned Data using Image Translation
Jul 03, 2019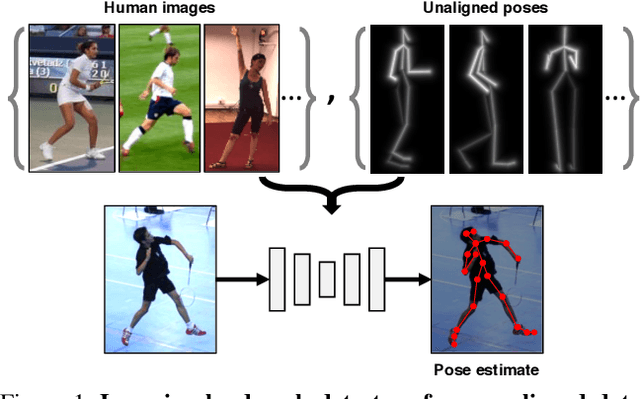
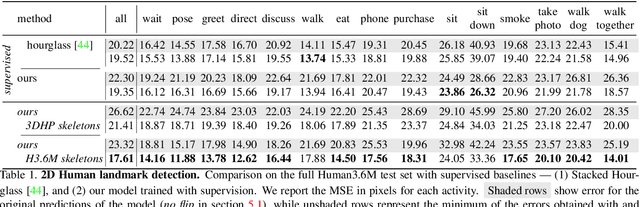

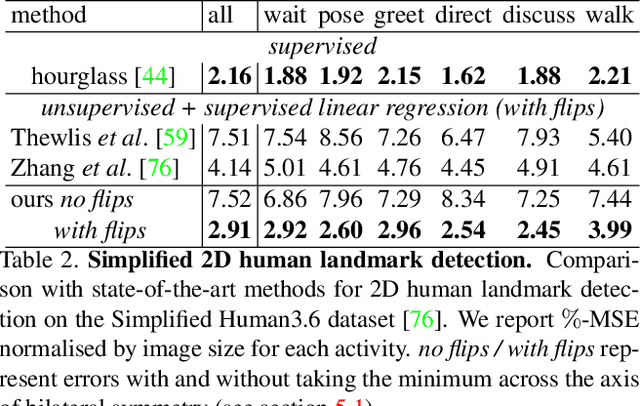
We introduce a method for learning landmark detectors from unlabelled video frames and unpaired labels. This allows us to learn a detector from a large collection of raw videos given only a few example annotations harvested from existing data or motion capture. We achieve this by formulating the landmark detection task as one of image translation, learning to map an image of the object to an image of its landmarks, represented as a skeleton. The advantage is that this translation problem can then be tackled by CycleGAN. However, we show that a naive application of CycleGAN confounds appearance and pose information, with suboptimal keypoint detection performance. We solve this problem by introducing an analytical and differentiable renderer for the skeleton image so that no appearance information can be leaked in the skeleton. Then, since cycle consistency requires to reconstruct the input image from the skeleton, we supply the appearance information thus removed by conditioning the generator with a second image of the same object (e.g. another frame from a video). Furthermore, while CycleGAN uses two cycle consistency constraints, we show that the second one is detrimental in this application and we discard it, significantly simplifying the model. We show that these modifications improve the quality of the learned detector leading to state-of-the-art unsupervised landmark detection performance in a number of challenging human pose and facial landmark detection benchmarks.
Unsupervised Learning of Object Keypoints for Perception and Control
Jun 19, 2019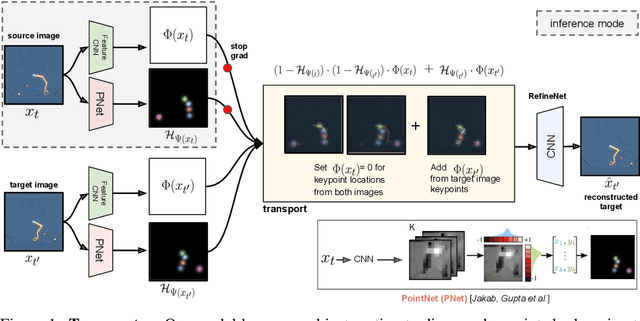


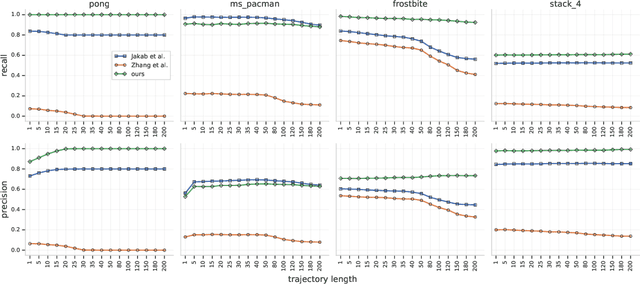
The study of object representations in computer vision has primarily focused on developing representations that are useful for image classification, object detection, or semantic segmentation as downstream tasks. In this work we aim to learn object representations that are useful for control and reinforcement learning (RL). To this end, we introduce Transporter, a neural network architecture for discovering concise geometric object representations in terms of keypoints or image-space coordinates. Our method learns from raw video frames in a fully unsupervised manner, by transporting learnt image features between video frames using a keypoint bottleneck. The discovered keypoints track objects and object parts across long time-horizons more accurately than recent similar methods. Furthermore, consistent long-term tracking enables two notable results in control domains -- (1) using the keypoint co-ordinates and corresponding image features as inputs enables highly sample-efficient reinforcement learning; (2) learning to explore by controlling keypoint locations drastically reduces the search space, enabling deep exploration (leading to states unreachable through random action exploration) without any extrinsic rewards.
Learning to Read by Spelling: Towards Unsupervised Text Recognition
Sep 23, 2018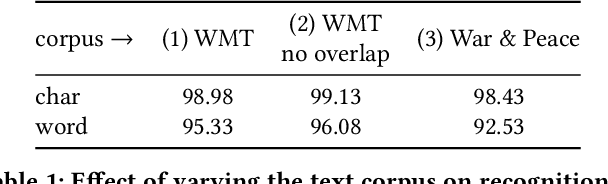
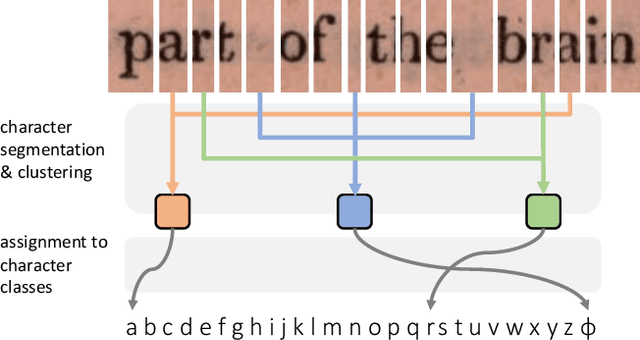


This work presents a method for visual text recognition without using any paired supervisory data. We formulate the text recognition task as one of aligning the conditional distribution of strings predicted from given text images, with lexically valid strings sampled from target corpora. This enables fully automated, and unsupervised learning from just line-level text-images, and unpaired text-string samples, obviating the need for large aligned datasets. We present detailed analysis for various aspects of the proposed method, namely - (1) the impact of the length of training sequences on convergence, (2) relation between character frequencies and the order in which they are learnt, and (3) demonstrate the generalisation ability of our recognition network to inputs of arbitrary lengths. Finally, we demonstrate excellent text recognition accuracy on both synthetically generated text images, and scanned images of real printed books, using no labelled training examples.
Inductive Visual Localisation: Factorised Training for Superior Generalisation
Jul 21, 2018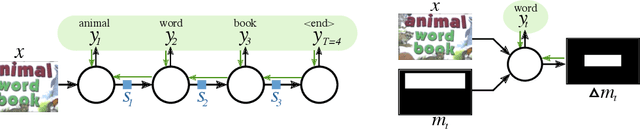

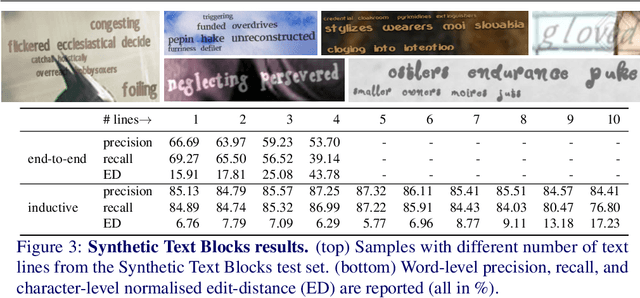
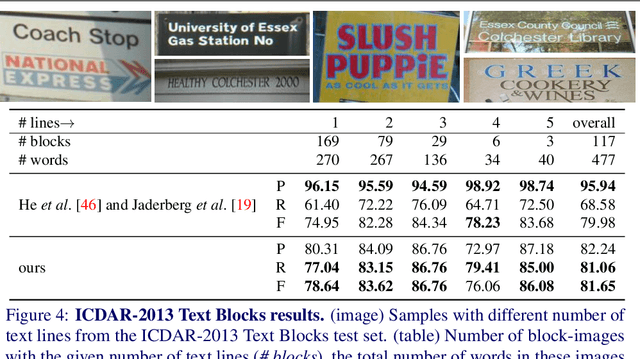
End-to-end trained Recurrent Neural Networks (RNNs) have been successfully applied to numerous problems that require processing sequences, such as image captioning, machine translation, and text recognition. However, RNNs often struggle to generalise to sequences longer than the ones encountered during training. In this work, we propose to optimise neural networks explicitly for induction. The idea is to first decompose the problem in a sequence of inductive steps and then to explicitly train the RNN to reproduce such steps. Generalisation is achieved as the RNN is not allowed to learn an arbitrary internal state; instead, it is tasked with mimicking the evolution of a valid state. In particular, the state is restricted to a spatial memory map that tracks parts of the input image which have been accounted for in previous steps. The RNN is trained for single inductive steps, where it produces updates to the memory in addition to the desired output. We evaluate our method on two different visual recognition problems involving visual sequences: (1) text spotting, i.e. joint localisation and reading of text in images containing multiple lines (or a block) of text, and (2) sequential counting of objects in aerial images. We show that inductive training of recurrent models enhances their generalisation ability on challenging image datasets.
Conditional Image Generation for Learning the Structure of Visual Objects
Jun 20, 2018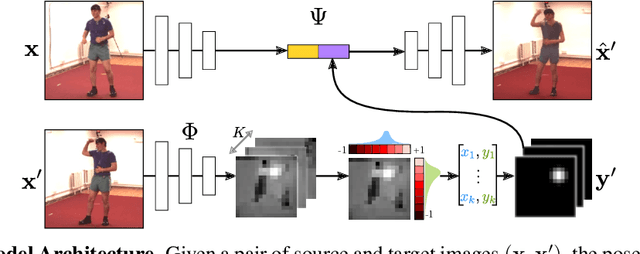
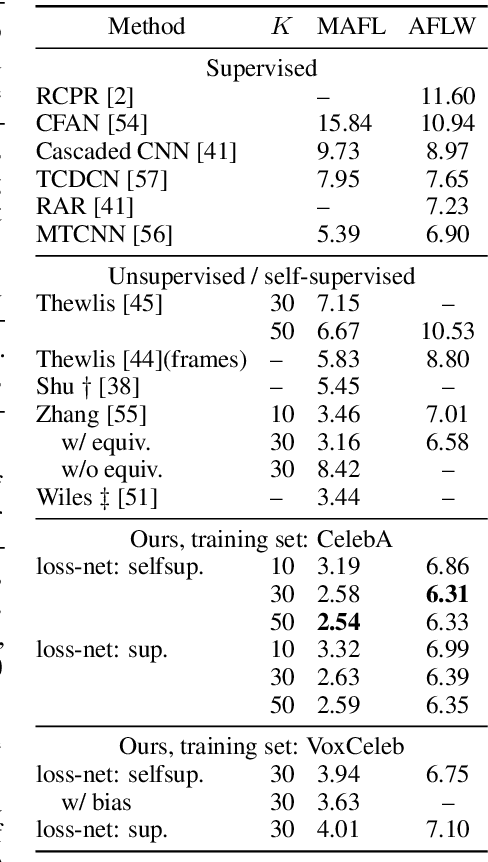

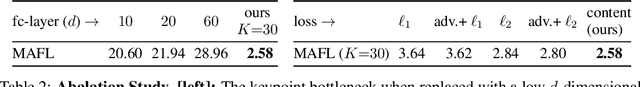
In this paper, we consider the problem of learning landmarks for object categories without any manual annotations. We cast this as the problem of conditionally generating an image of an object from another one, where the images differ by acquisition time and/or viewpoint. The process is aided by providing the generator with a keypoint-like representation extracted from the target image through a tight bottleneck. This encourages the representation to distil information about the object geometry, which changes from source to target, while the appearance, which is shared between the source and target, is read off from the source alone. Conditioning simplifies the generation task significantly, to the point that adopting a simple perceptual loss instead of more sophisticated approaches such as adversarial training is sufficient to learn landmarks. We show that our method is applicable to a large variety of datasets - faces, people, 3D objects, and digits - without any modifications. We further demonstrate that we can learn landmarks from synthetic image deformations or videos, all without manual supervision, while outperforming state-of-the-art unsupervised landmark detectors.
A Deep Generative Framework for Paraphrase Generation
Sep 15, 2017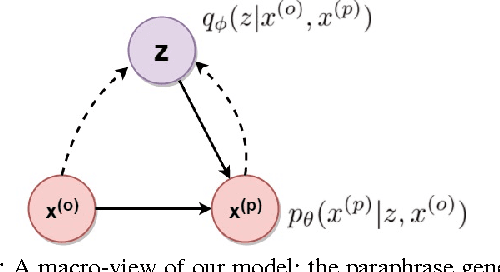
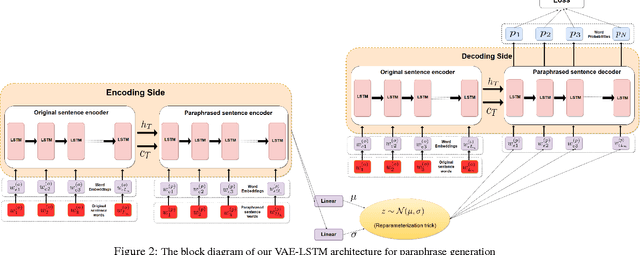
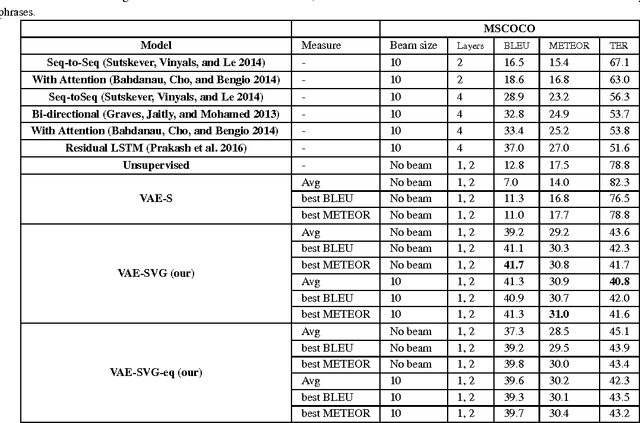
Paraphrase generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. In this paper, we address the problem of generating paraphrases automatically. Our proposed method is based on a combination of deep generative models (VAE) with sequence-to-sequence models (LSTM) to generate paraphrases, given an input sentence. Traditional VAEs when combined with recurrent neural networks can generate free text but they are not suitable for paraphrase generation for a given sentence. We address this problem by conditioning the both, encoder and decoder sides of VAE, on the original sentence, so that it can generate the given sentence's paraphrases. Unlike most existing models, our model is simple, modular and can generate multiple paraphrases, for a given sentence. Quantitative evaluation of the proposed method on a benchmark paraphrase dataset demonstrates its efficacy, and its performance improvement over the state-of-the-art methods by a significant margin, whereas qualitative human evaluation indicate that the generated paraphrases are well-formed, grammatically correct, and are relevant to the input sentence. Furthermore, we evaluate our method on a newly released question paraphrase dataset, and establish a new baseline for future research.
Synthetic Data for Text Localisation in Natural Images
Apr 22, 2016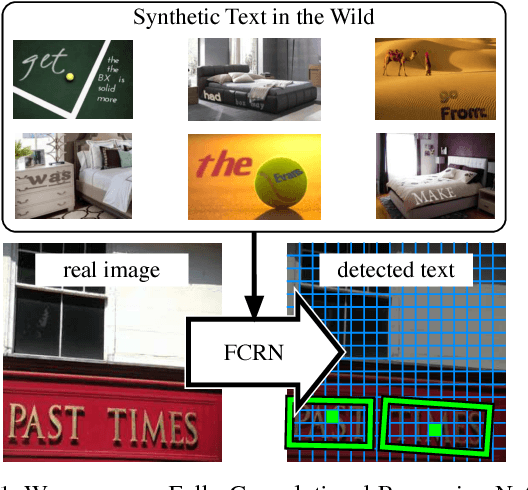
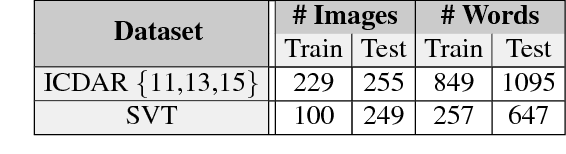

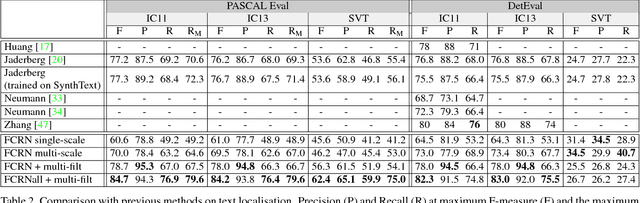
In this paper we introduce a new method for text detection in natural images. The method comprises two contributions: First, a fast and scalable engine to generate synthetic images of text in clutter. This engine overlays synthetic text to existing background images in a natural way, accounting for the local 3D scene geometry. Second, we use the synthetic images to train a Fully-Convolutional Regression Network (FCRN) which efficiently performs text detection and bounding-box regression at all locations and multiple scales in an image. We discuss the relation of FCRN to the recently-introduced YOLO detector, as well as other end-to-end object detection systems based on deep learning. The resulting detection network significantly out performs current methods for text detection in natural images, achieving an F-measure of 84.2% on the standard ICDAR 2013 benchmark. Furthermore, it can process 15 images per second on a GPU.