 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
CLIP4Sketch: Enhancing Sketch to Mugshot Matching through Dataset Augmentation using Diffusion Models
Aug 02, 2024



Forensic sketch-to-mugshot matching is a challenging task in face recognition, primarily hindered by the scarcity of annotated forensic sketches and the modality gap between sketches and photographs. To address this, we propose CLIP4Sketch, a novel approach that leverages diffusion models to generate a large and diverse set of sketch images, which helps in enhancing the performance of face recognition systems in sketch-to-mugshot matching. Our method utilizes Denoising Diffusion Probabilistic Models (DDPMs) to generate sketches with explicit control over identity and style. We combine CLIP and Adaface embeddings of a reference mugshot, along with textual descriptions of style, as the conditions to the diffusion model. We demonstrate the efficacy of our approach by generating a comprehensive dataset of sketches corresponding to mugshots and training a face recognition model on our synthetic data. Our results show significant improvements in sketch-to-mugshot matching accuracy over training on an existing, limited amount of real face sketch data, validating the potential of diffusion models in enhancing the performance of face recognition systems across modalities. We also compare our dataset with datasets generated using GAN-based methods to show its superiority.
GenPalm: Contactless Palmprint Generation with Diffusion Models
Jun 01, 2024



The scarcity of large-scale palmprint databases poses a significant bottleneck to advancements in contactless palmprint recognition. To address this, researchers have turned to synthetic data generation. While Generative Adversarial Networks (GANs) have been widely used, they suffer from instability and mode collapse. Recently, diffusion probabilistic models have emerged as a promising alternative, offering stable training and better distribution coverage. This paper introduces a novel palmprint generation method using diffusion probabilistic models, develops an end-to-end framework for synthesizing multiple palm identities, and validates the realism and utility of the generated palmprints. Experimental results demonstrate the effectiveness of our approach in generating palmprint images which enhance contactless palmprint recognition performance across several test databases utilizing challenging cross-database and time-separated evaluation protocols.
Universal Fingerprint Generation: Controllable Diffusion Model with Multimodal Conditions
Apr 21, 2024



The utilization of synthetic data for fingerprint recognition has garnered increased attention due to its potential to alleviate privacy concerns surrounding sensitive biometric data. However, current methods for generating fingerprints have limitations in creating impressions of the same finger with useful intra-class variations. To tackle this challenge, we present GenPrint, a framework to produce fingerprint images of various types while maintaining identity and offering humanly understandable control over different appearance factors such as fingerprint class, acquisition type, sensor device, and quality level. Unlike previous fingerprint generation approaches, GenPrint is not confined to replicating style characteristics from the training dataset alone: it enables the generation of novel styles from unseen devices without requiring additional fine-tuning. To accomplish these objectives, we developed GenPrint using latent diffusion models with multimodal conditions (text and image) for consistent generation of style and identity. Our experiments leverage a variety of publicly available datasets for training and evaluation. Results demonstrate the benefits of GenPrint in terms of identity preservation, explainable control, and universality of generated images. Importantly, the GenPrint-generated images yield comparable or even superior accuracy to models trained solely on real data and further enhances performance when augmenting the diversity of existing real fingerprint datasets.
Mobile Contactless Palmprint Recognition: Use of Multiscale, Multimodel Embeddings
Jan 16, 2024



Contactless palmprints are comprised of both global and local discriminative features. Most prior work focuses on extracting global features or local features alone for palmprint matching, whereas this research introduces a novel framework that combines global and local features for enhanced palmprint matching accuracy. Leveraging recent advancements in deep learning, this study integrates a vision transformer (ViT) and a convolutional neural network (CNN) to extract complementary local and global features. Next, a mobile-based, end-to-end palmprint recognition system is developed, referred to as Palm-ID. On top of the ViT and CNN features, Palm-ID incorporates a palmprint enhancement module and efficient dimensionality reduction (for faster matching). Palm-ID balances the trade-off between accuracy and latency, requiring just 18ms to extract a template of size 516 bytes, which can be efficiently searched against a 10,000 palmprint gallery in 0.33ms on an AMD EPYC 7543 32-Core CPU utilizing 128-threads. Cross-database matching protocols and evaluations on large-scale operational datasets demonstrate the robustness of the proposed method, achieving a TAR of 98.06% at FAR=0.01% on a newly collected, time-separated dataset. To show a practical deployment of the end-to-end system, the entire recognition pipeline is embedded within a mobile device for enhanced user privacy and security.
AdvGen: Physical Adversarial Attack on Face Presentation Attack Detection Systems
Nov 20, 2023



Evaluating the risk level of adversarial images is essential for safely deploying face authentication models in the real world. Popular approaches for physical-world attacks, such as print or replay attacks, suffer from some limitations, like including physical and geometrical artifacts. Recently, adversarial attacks have gained attraction, which try to digitally deceive the learning strategy of a recognition system using slight modifications to the captured image. While most previous research assumes that the adversarial image could be digitally fed into the authentication systems, this is not always the case for systems deployed in the real world. This paper demonstrates the vulnerability of face authentication systems to adversarial images in physical world scenarios. We propose AdvGen, an automated Generative Adversarial Network, to simulate print and replay attacks and generate adversarial images that can fool state-of-the-art PADs in a physical domain attack setting. Using this attack strategy, the attack success rate goes up to 82.01%. We test AdvGen extensively on four datasets and ten state-of-the-art PADs. We also demonstrate the effectiveness of our attack by conducting experiments in a realistic, physical environment.
Accelerated Fingerprint Enhancement: A GPU-Optimized Mixed Architecture Approach
Jun 01, 2023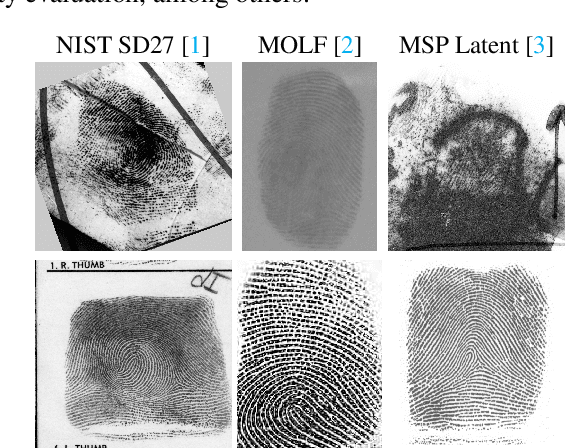
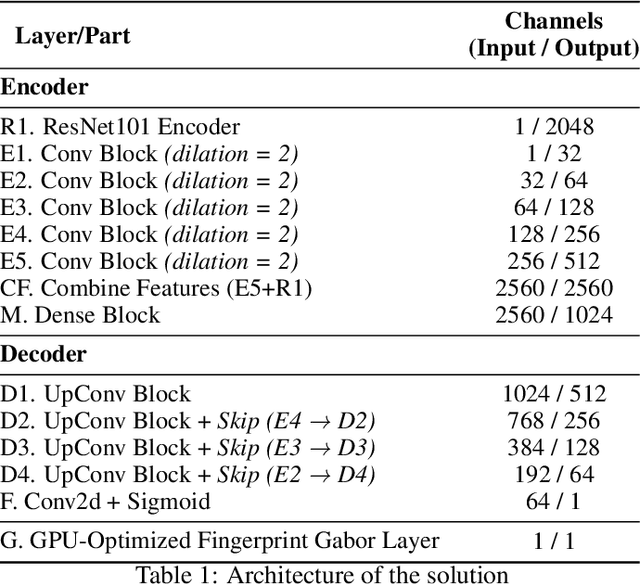
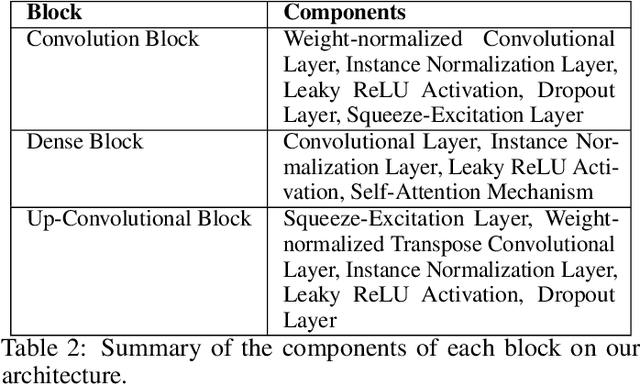
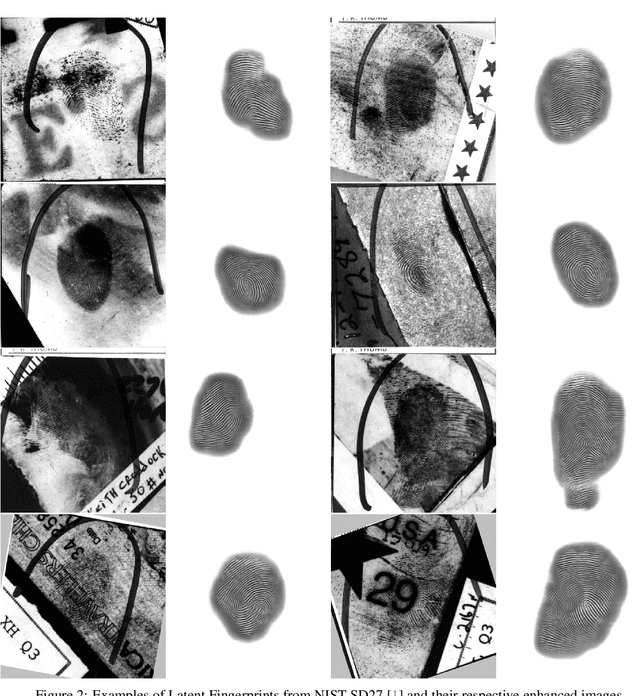
This document presents a preliminary approach to latent fingerprint enhancement, fundamentally designed around a mixed Unet architecture. It combines the capabilities of the Resnet-101 network and Unet encoder, aiming to form a potentially powerful composite. This combination, enhanced with attention mechanisms and forward skip connections, is intended to optimize the enhancement of ridge and minutiae features in fingerprints. One innovative element of this approach includes a novel Fingerprint Enhancement Gabor layer, specifically designed for GPU computations. This illustrates how modern computational resources might be harnessed to expedite enhancement. Given its potential functionality as either a CNN or Transformer layer, this Gabor layer could offer improved agility and processing speed to the system. However, it is important to note that this approach is still in the early stages of development and has not yet been fully validated through rigorous experiments. As such, it may require additional time and testing to establish its robustness and usability in the field of latent fingerprint enhancement. This includes improvements in processing speed, enhancement adaptability with distinct latent fingerprint types, and full validation in experimental approaches such as open-set (identification 1:N) and open-set validation, fingerprint quality evaluation, among others.
A Universal Latent Fingerprint Enhancer Using Transformers
May 31, 2023



Forensic science heavily relies on analyzing latent fingerprints, which are crucial for criminal investigations. However, various challenges, such as background noise, overlapping prints, and contamination, make the identification process difficult. Moreover, limited access to real crime scene and laboratory-generated databases hinders the development of efficient recognition algorithms. This study aims to develop a fast method, which we call ULPrint, to enhance various latent fingerprint types, including those obtained from real crime scenes and laboratory-created samples, to boost fingerprint recognition system performance. In closed-set identification accuracy experiments, the enhanced image was able to improve the performance of the MSU-AFIS from 61.56\% to 75.19\% in the NIST SD27 database, from 67.63\% to 77.02\% in the MSP Latent database, and from 46.90\% to 52.12\% in the NIST SD302 database. Our contributions include (1) the development of a two-step latent fingerprint enhancement method that combines Ridge Segmentation with UNet and Mix Visual Transformer (MiT) SegFormer-B5 encoder architecture, (2) the implementation of multiple dilated convolutions in the UNet architecture to capture intricate, non-local patterns better and enhance ridge segmentation, and (3) the guided blending of the predicted ridge mask with the latent fingerprint. This novel approach, ULPrint, streamlines the enhancement process, addressing challenges across diverse latent fingerprint types to improve forensic investigations and criminal justice outcomes.
ViT Unified: Joint Fingerprint Recognition and Presentation Attack Detection
May 12, 2023



A secure fingerprint recognition system must contain both a presentation attack (i.e., spoof) detection and recognition module in order to protect users against unwanted access by malicious users. Traditionally, these tasks would be carried out by two independent systems; however, recent studies have demonstrated the potential to have one unified system architecture in order to reduce the computational burdens on the system, while maintaining high accuracy. In this work, we leverage a vision transformer architecture for joint spoof detection and matching and report competitive results with state-of-the-art (SOTA) models for both a sequential system (two ViT models operating independently) and a unified architecture (a single ViT model for both tasks). ViT models are particularly well suited for this task as the ViT's global embedding encodes features useful for recognition, whereas the individual, local embeddings are useful for spoof detection. We demonstrate the capability of our unified model to achieve an average integrated matching (IM) accuracy of 98.87% across LivDet 2013 and 2015 CrossMatch sensors. This is comparable to IM accuracy of 98.95% of our sequential dual-ViT system, but with ~50% of the parameters and ~58% of the latency.
Child Palm-ID: Contactless Palmprint Recognition for Children
May 09, 2023



Effective distribution of nutritional and healthcare aid for children, particularly infants and toddlers, in some of the least developed and most impoverished countries of the world, is a major problem due to the lack of reliable identification documents. Biometric authentication technology has been investigated to address child recognition in the absence of reliable ID documents. We present a mobile-based contactless palmprint recognition system, called Child Palm-ID, which meets the requirements of usability, hygiene, cost, and accuracy for child recognition. Using a contactless child palmprint database, Child-PalmDB1, consisting of 19,158 images from 1,020 unique palms (in the age range of 6 mos. to 48 mos.), we report a TAR=94.11% @ FAR=0.1%. The proposed Child Palm-ID system is also able to recognize adults, achieving a TAR=99.4% on the CASIA contactless palmprint database and a TAR=100% on the COEP contactless adult palmprint database, both @ FAR=0.1%. These accuracies are competitive with the SOTA provided by COTS systems. Despite these high accuracies, we show that the TAR for time-separated child-palmprints is only 78.1% @ FAR=0.1%.