 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-Box Evaluation of Fingerprint Matchers
Sep 23, 2019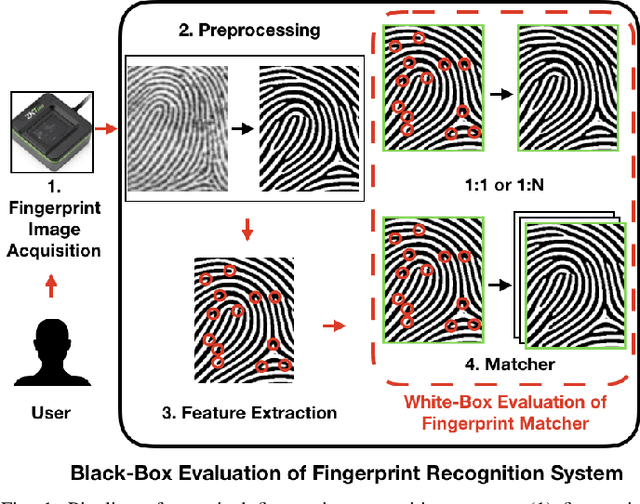
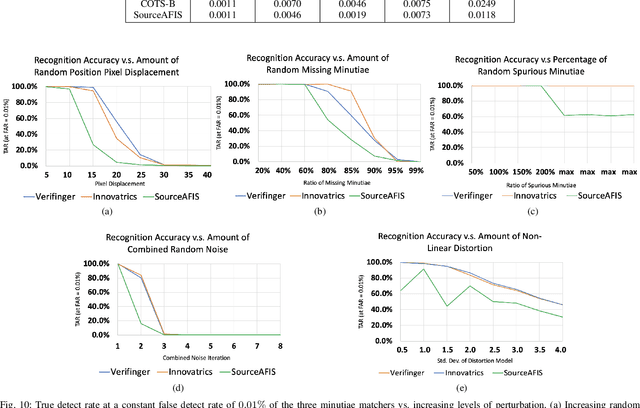


Prevailing evaluations of fingerprint recognition systems have been performed as end-to-end black-box tests of fingerprint identification or verification accuracy. However, performance of the end-to-end system is subject to errors arising in any of the constituent modules, including: fingerprint reader, preprocessing, feature extraction, and matching. While a few studies have conducted white-box testing of the fingerprint reader and feature extraction modules of fingerprint recognition systems, little work has been devoted towards white-box evaluations of the fingerprint matching sub-module. We report results of a controlled, white-box evaluation of one open-source and two commercial-off-the-shelf (COTS) state-of-the-art minutiae-based matchers in terms of their robustness against controlled perturbations (random noise, and non-linear distortions) introduced into the input minutiae feature sets. Experiments were conducted on 10,000 synthetically generated fingerprints. Our white-box evaluations show performance comparisons between different minutiae-based matchers in the presence of various perturbations and non-linear distortion, which were not previously shown with black-box tests. Furthermore, our white-box evaluations reveal that the performance of fingerprint minutiae matchers are more susceptible to non-linear distortion and missing minutiae than spurious minutiae and small positional displacements of the minutiae locations. The measurement uncertainty in fingerprint matching is also developed.
Learning a Fixed-Length Fingerprint Representation
Sep 21, 2019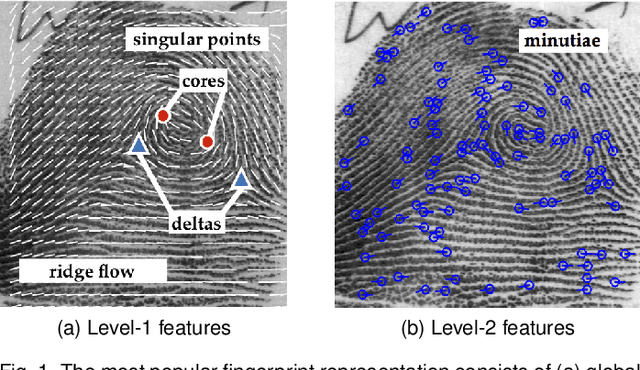


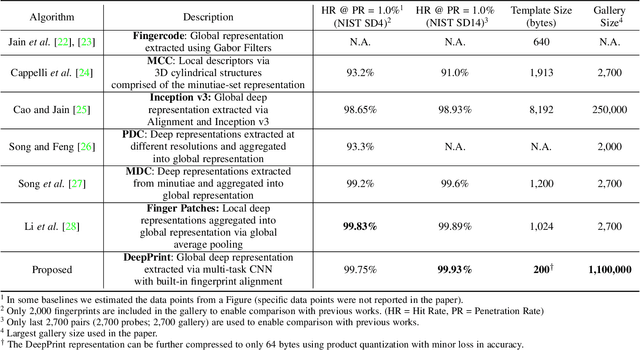
We present DeepPrint, a deep network, which learns to extract fixed-length fingerprint representations of only 200 bytes. DeepPrint incorporates fingerprint domain knowledge, including alignment and minutiae detection, into the deep network architecture to maximize the discriminative power of its representation. The compact, DeepPrint representation has several advantages over the prevailing variable length minutiae representation which (i) requires computationally expensive graph matching techniques, (ii) is difficult to secure using strong encryption schemes (e.g. homomorphic encryption), and (iii) has low discriminative power in poor quality fingerprints where minutiae extraction is unreliable. We benchmark DeepPrint against two top performing COTS SDKs (Verifinger and Innovatrics) from the NIST and FVC evaluations. Coupled with a re-ranking scheme, the DeepPrint rank-1 search accuracy on the NIST SD4 dataset against a gallery of 1.1 million fingerprints is comparable to the top COTS matcher, but it is significantly faster (DeepPrint: 98.80% in 0.3 seconds vs. COTS A: 98.85% in 27 seconds). To the best of our knowledge, the DeepPrint representation is the most compact and discriminative fixed-length fingerprint representation reported in the academic literature.
AdvFaces: Adversarial Face Synthesis
Aug 14, 2019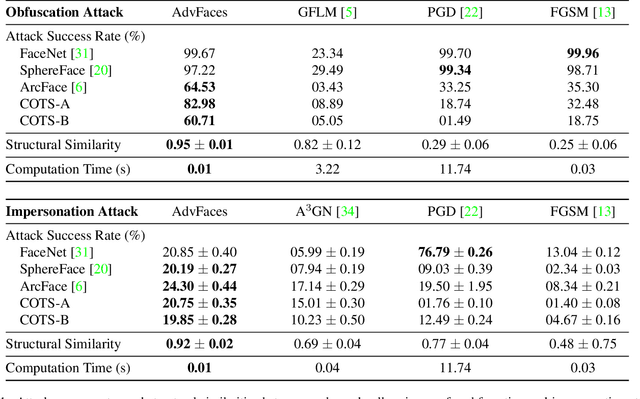

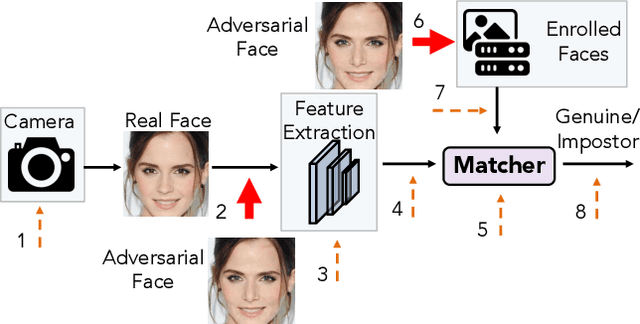
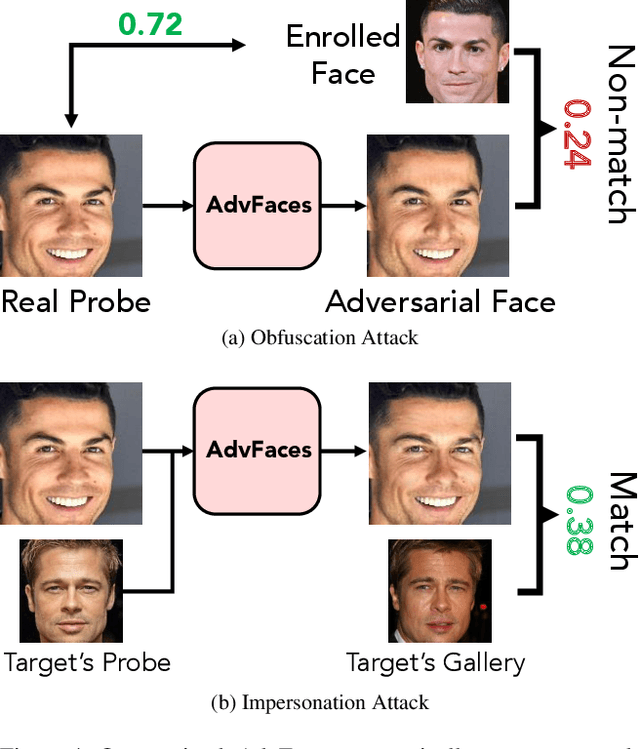
Face recognition systems have been shown to be vulnerable to adversarial examples resulting from adding small perturbations to probe images. Such adversarial images can lead state-of-the-art face recognition systems to falsely reject a genuine subject (obfuscation attack) or falsely match to an impostor (impersonation attack). Current approaches to crafting adversarial face images lack perceptual quality and take an unreasonable amount of time to generate them. We propose, AdvFaces, an automated adversarial face synthesis method that learns to generate minimal perturbations in the salient facial regions via Generative Adversarial Networks. Once AdvFaces is trained, it can automatically generate imperceptible perturbations that can evade state-of-the-art face matchers with attack success rates as high as 97.22% and 24.30% for obfuscation and impersonation attacks, respectively.
OCT Fingerprints: Resilience to Presentation Attacks
Jul 31, 2019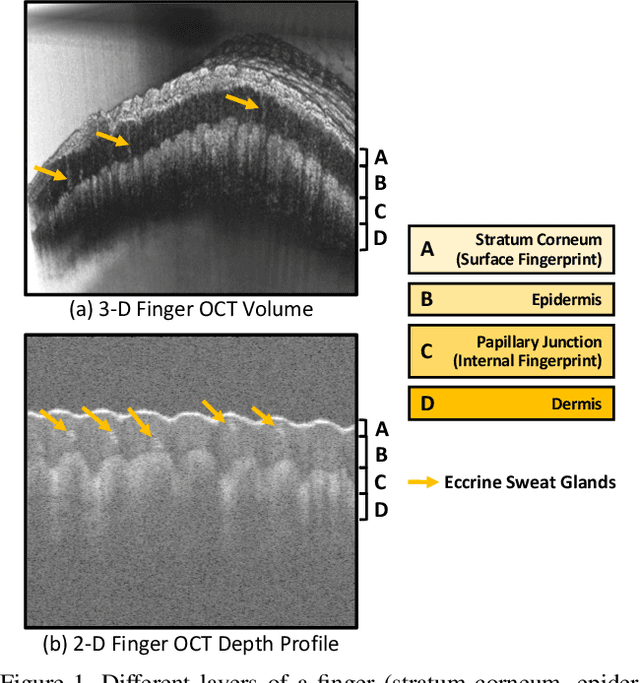
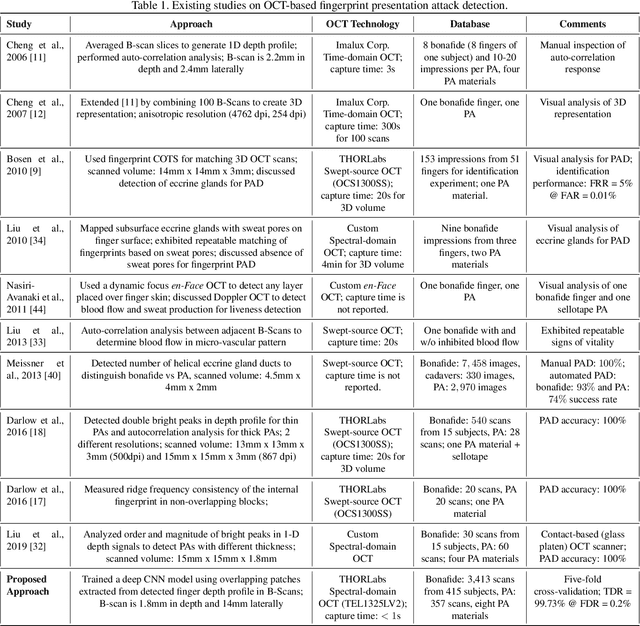
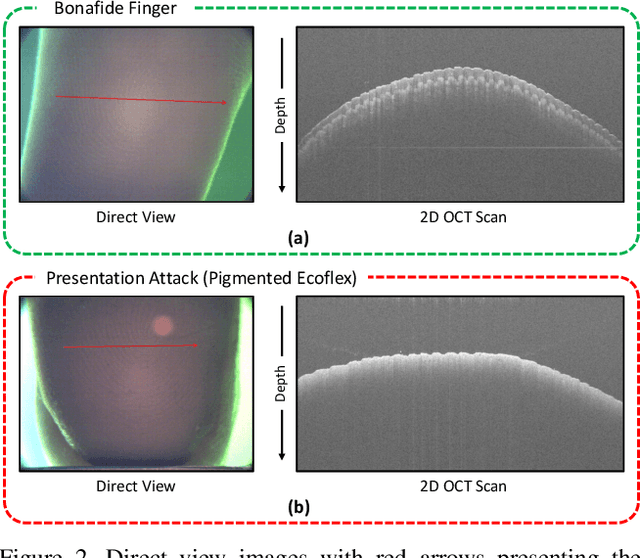
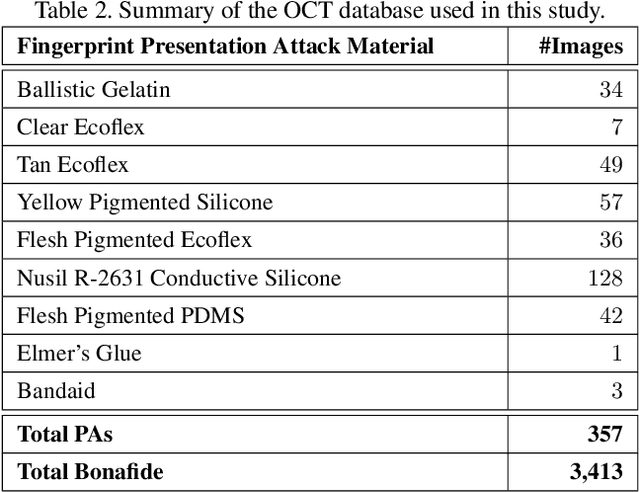
Optical coherent tomography (OCT) fingerprint technology provides rich depth information, including internal fingerprint (papillary junction) and sweat (eccrine) glands, in addition to imaging any fake layers (presentation attacks) placed over finger skin. Unlike 2D surface fingerprint scans, additional depth information provided by the cross-sectional OCT depth profile scans are purported to thwart fingerprint presentation attacks. We develop and evaluate a presentation attack detector (PAD) based on deep convolutional neural network (CNN). Input data to CNN are local patches extracted from the cross-sectional OCT depth profile scans captured using THORLabs Telesto series spectral-domain fingerprint reader. The proposed approach achieves a TDR of 99.73% @ FDR of 0.2% on a database of 3,413 bonafide and 357 PA OCT scans, fabricated using 8 different PA materials. By employing a visualization technique, known as CNN-Fixations, we are able to identify the regions in the OCT scan patches that are crucial for fingerprint PAD detection.
End-to-End Pore Extraction and Matching in Latent Fingerprints: Going Beyond Minutiae
May 30, 2019
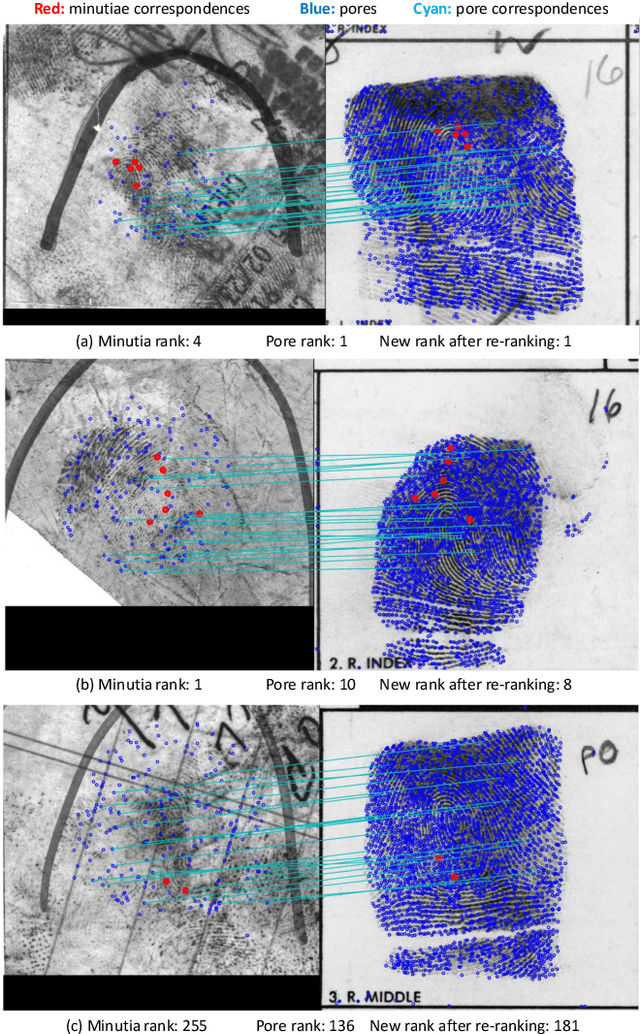
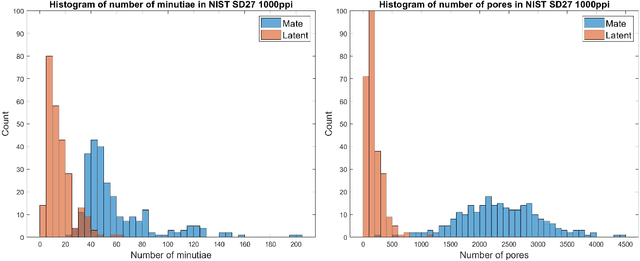
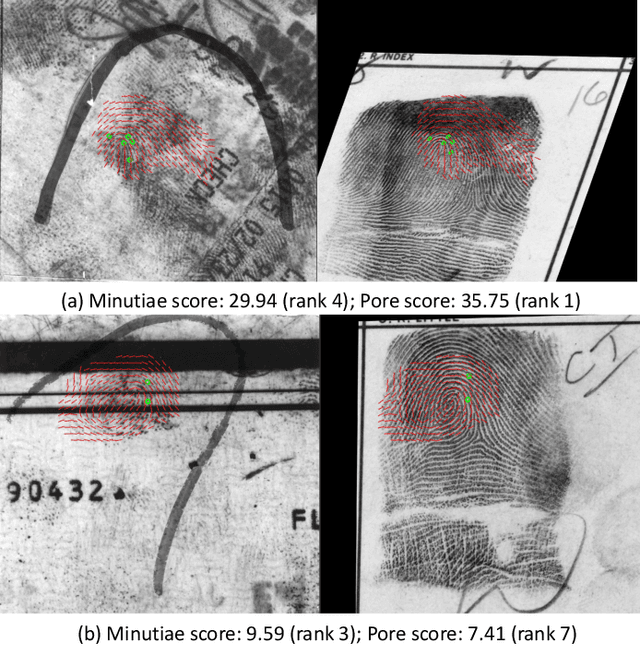
Latent fingerprint recognition is not a new topic but it has attracted a lot of attention from researchers in both academia and industry over the past 50 years. With the rapid development of pattern recognition techniques, automated fingerprint identification systems (AFIS) have become more and more ubiquitous. However, most AFIS are utilized for live-scan or rolled/slap prints while only a few systems can work on latent fingerprints with reasonable accuracy. The question of whether taking higher resolution scans of latent fingerprints and their rolled/slap mate prints could help improve the identification accuracy still remains an open question in the forensic community. Because pores are one of the most reliable features besides minutiae to identify latent fingerprints, we propose an end-to-end automatic pore extraction and matching system to analyze the utility of pores in latent fingerprint identification. Hence, this paper answers two questions in the latent fingerprint domain: (i) does the incorporation of pores as level-3 features improve the system performance significantly? and (ii) does the 1,000 ppi image resolution improve the recognition results? We believe that our proposed end-to-end pore extraction and matching system will be a concrete baseline for future latent AFIS development.
Recurrent Embedding Aggregation Network for Video Face Recognition
Apr 26, 2019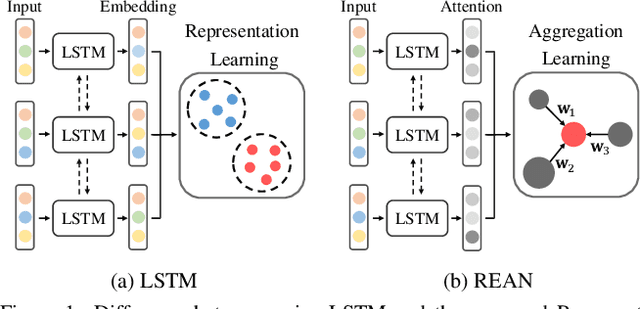
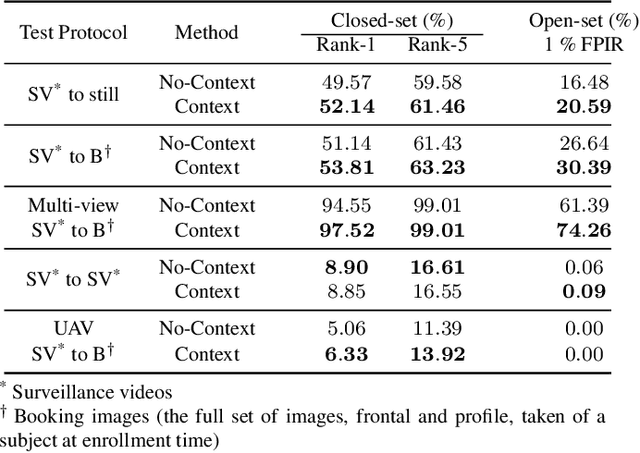

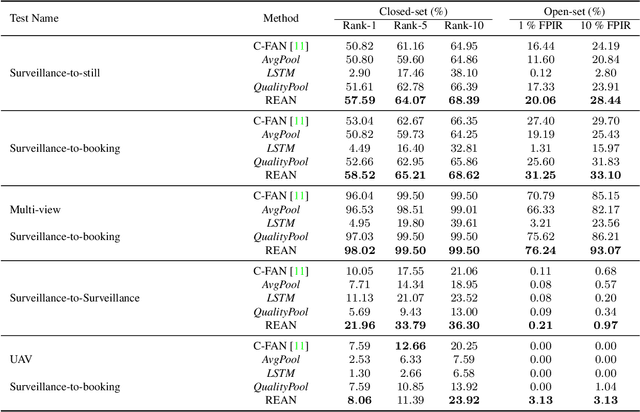
Recurrent networks have been successful in analyzing temporal data and have been widely used for video analysis. However, for video face recognition, where the base CNNs trained on large-scale data already provide discriminative features, using Long Short-Term Memory (LSTM), a popular recurrent network, for feature learning could lead to overfitting and degrade the performance instead. We propose a Recurrent Embedding Aggregation Network (REAN) for set to set face recognition. Compared with LSTM, REAN is robust against overfitting because it only learns how to aggregate the pre-trained embeddings rather than learning representations from scratch. Compared with quality-aware aggregation methods, REAN can take advantage of the context information to circumvent the noise introduced by redundant video frames. Empirical results on three public domain video face recognition datasets, IJB-S, YTF, and PaSC show that the proposed REAN significantly outperforms naive CNN-LSTM structure and quality-aware aggregation methods.
Probabilistic Face Embeddings
Apr 25, 2019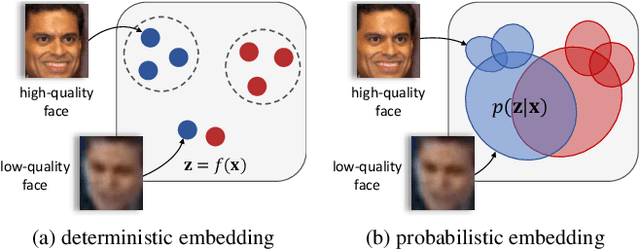
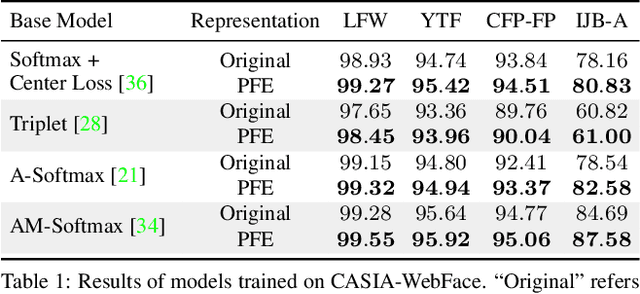

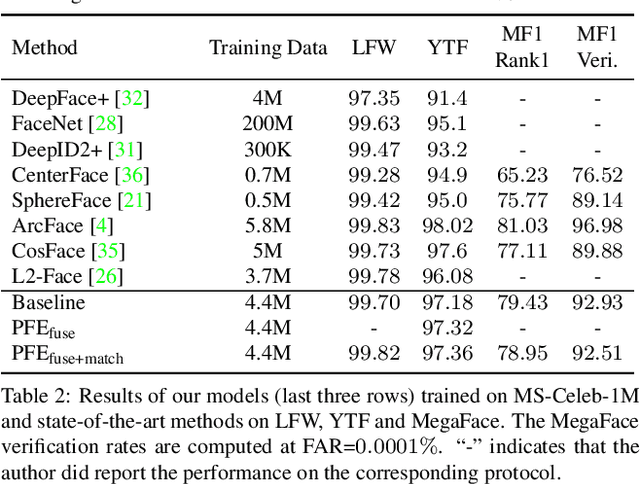
Embedding methods have achieved success in face recognition by comparing facial features in a latent semantic space. However, in a fully unconstrained face setting, the features learned by the embedding model could be ambiguous or may not even be present in the input face, leading to noisy representations. We propose Probabilistic Face Embeddings (PFEs), which represent each face image as a Gaussian distribution in the latent space. The mean of the distribution estimates the most likely feature values while the variance shows the uncertainty in the feature values. Probabilistic solutions can then be naturally derived for matching and fusing PFEs using the uncertainty information. Empirical evaluation on different baseline models, training datasets and benchmarks show that the proposed method can improve the face recognition performance of deterministic embeddings by converting them into PFEs. The uncertainties estimated by PFEs also serve as good indicators of the potential matching accuracy, which are important for a risk-controlled recognition system.
Fingerprints: Fixed Length Representation via Deep Networks and Domain Knowledge
Apr 01, 2019
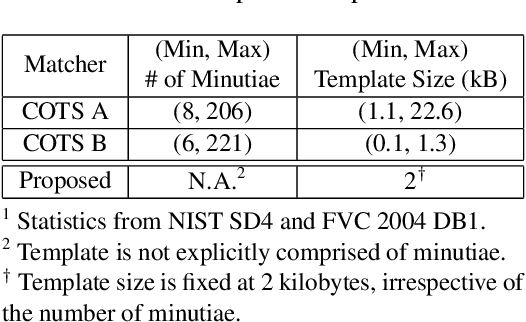

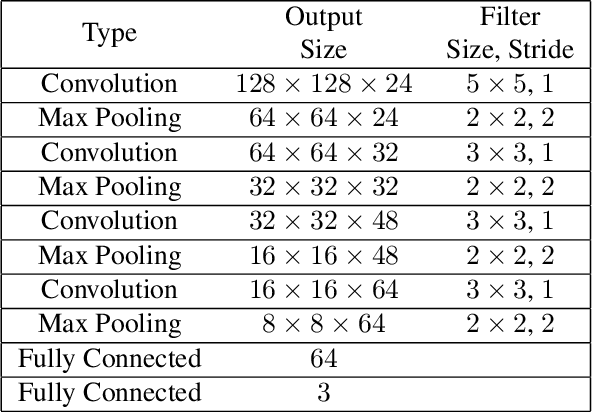
We learn a discriminative fixed length feature representation of fingerprints which stands in contrast to commonly used unordered, variable length sets of minutiae points. To arrive at this fixed length representation, we embed fingerprint domain knowledge into a multitask deep convolutional neural network architecture. Empirical results, on two public-domain fingerprint databases (NIST SD4 and FVC 2004 DB1) show that compared to minutiae representations, extracted by two state-of-the-art commercial matchers (Verifinger v6.3 and Innovatrics v2.0.3), our fixed-length representations provide (i) higher search accuracy: Rank-1 accuracy of 97.9% vs. 97.3% on NIST SD4 against a gallery size of 2000 and (ii) significantly faster, large scale search: 682,594 matches per second vs. 22 matches per second for commercial matchers on an i5 3.3 GHz processor with 8 GB of RAM.
Infant-Prints: Fingerprints for Reducing Infant Mortality
Apr 01, 2019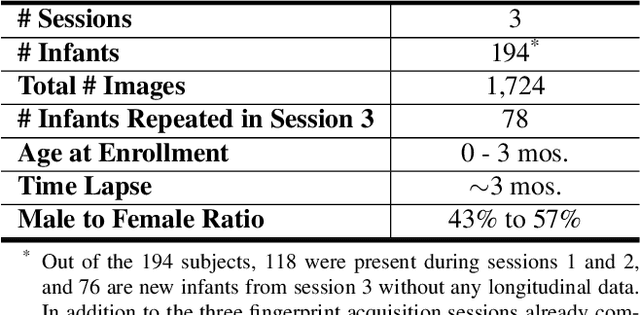


In developing countries around the world, a multitude of infants continue to suffer and die from vaccine-preventable diseases, and malnutrition. Lamentably, the lack of any official identification documentation makes it exceedingly difficult to prevent these infant deaths. To solve this global crisis, we propose Infant-Prints which is comprised of (i) a custom, compact, low-cost (85 USD), high-resolution (1,900 ppi) fingerprint reader, (ii) a high-resolution fingerprint matcher, and (iii) a mobile application for search and verification for the infant fingerprint. Using Infant-Prints, we have collected a longitudinal database of infant fingerprints and demonstrate its ability to perform accurate and reliable recognition of infants enrolled at the ages 0-3 months, in time for effective delivery of critical vaccinations and nutritional supplements (TAR=90% @ FAR = 0.1% for infants older than 8 weeks).
Video Face Recognition: Component-wise Feature Aggregation Network (C-FAN)
Feb 21, 2019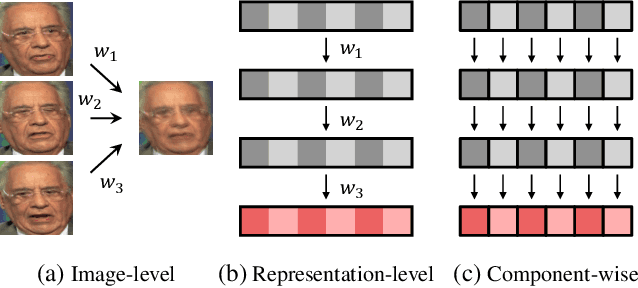


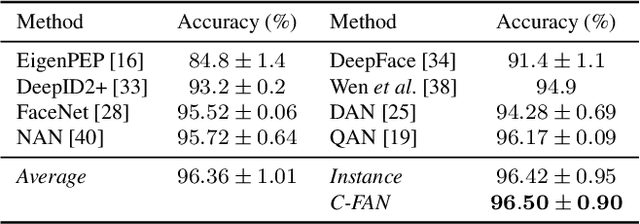
We propose a new approach to video face recognition. Our component-wise feature aggregation network (C-FAN) accepts a set of face images of a subject as an input, and outputs a single feature vector as the face representation of the set for the recognition task. The whole network is trained in two steps: (i) train a base CNN for still image face recognition; (ii) add an aggregation module to the base network to learn the quality value for each feature component, which adaptively aggregates deep feature vectors into a single vector to represent the face in a video. C-FAN automatically learns to retain salient face features with high quality scores while suppressing features with low quality scores. The experimental results on three benchmark datasets, YouTube Faces, IJB-A, and IJB-S show that the proposed C-FAN network is capable of generating a compact feature vector with 512 dimensions for a video sequence by efficiently aggregating feature vectors of all the video frames to achieve state of the art performance.