 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Detection of Digital and Physical Face Attacks
Apr 05, 2021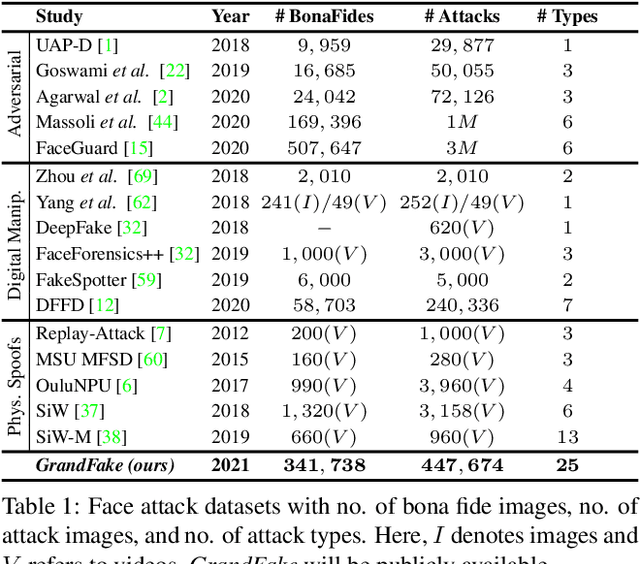
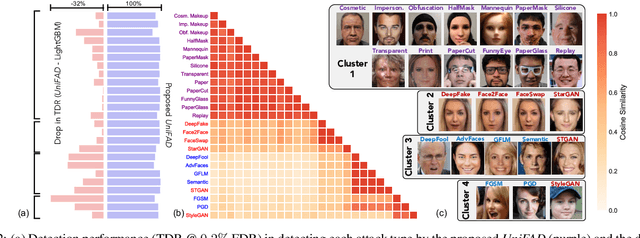
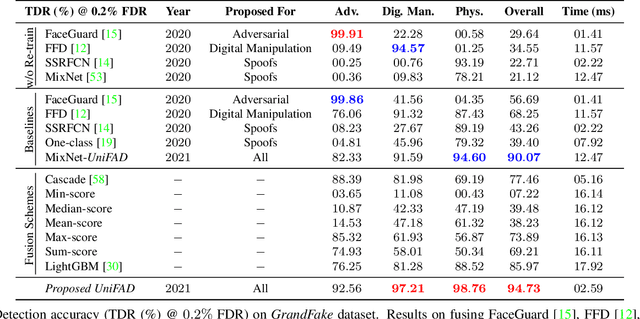
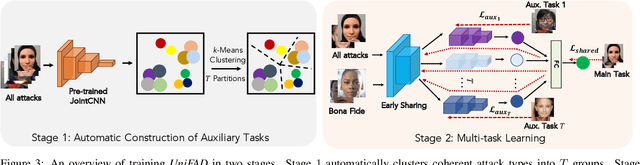
State-of-the-art defense mechanisms against face attacks achieve near perfect accuracies within one of three attack categories, namely adversarial, digital manipulation, or physical spoofs, however, they fail to generalize well when tested across all three categories. Poor generalization can be attributed to learning incoherent attacks jointly. To overcome this shortcoming, we propose a unified attack detection framework, namely UniFAD, that can automatically cluster 25 coherent attack types belonging to the three categories. Using a multi-task learning framework along with k-means clustering, UniFAD learns joint representations for coherent attacks, while uncorrelated attack types are learned separately. Proposed UniFAD outperforms prevailing defense methods and their fusion with an overall TDR = 94.73% @ 0.2% FDR on a large fake face dataset consisting of 341K bona fide images and 448K attack images of 25 types across all 3 categories. Proposed method can detect an attack within 3 milliseconds on a Nvidia 2080Ti. UniFAD can also identify the attack types and categories with 75.81% and 97.37% accuracies, respectively.
FaceGuard: A Self-Supervised Defense Against Adversarial Face Images
Nov 28, 2020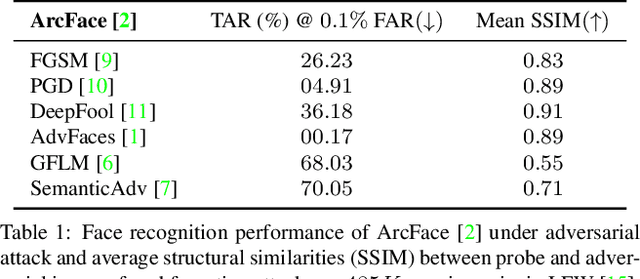

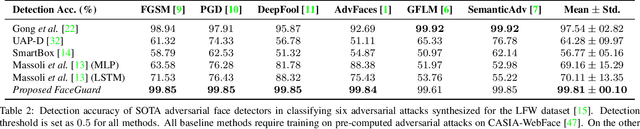
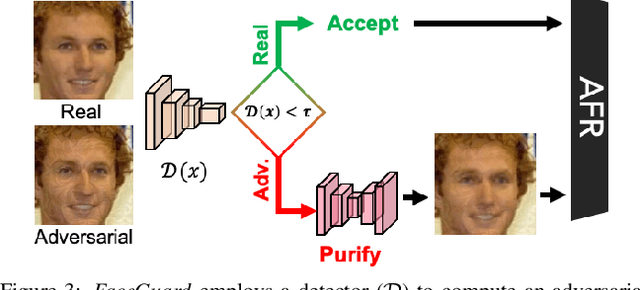
Prevailing defense mechanisms against adversarial face images tend to overfit to the adversarial perturbations in the training set and fail to generalize to unseen adversarial attacks. We propose a new self-supervised adversarial defense framework, namely FaceGuard, that can automatically detect, localize, and purify a wide variety of adversarial faces without utilizing pre-computed adversarial training samples. During training, FaceGuard automatically synthesizes challenging and diverse adversarial attacks, enabling a classifier to learn to distinguish them from real faces and a purifier attempts to remove the adversarial perturbations in the image space. Experimental results on LFW dataset show that FaceGuard can achieve 99.81% detection accuracy on six unseen adversarial attack types. In addition, the proposed method can enhance the face recognition performance of ArcFace from 34.27% TAR @ 0.1% FAR under no defense to 77.46% TAR @ 0.1% FAR.
Lifting 2D StyleGAN for 3D-Aware Face Generation
Nov 26, 2020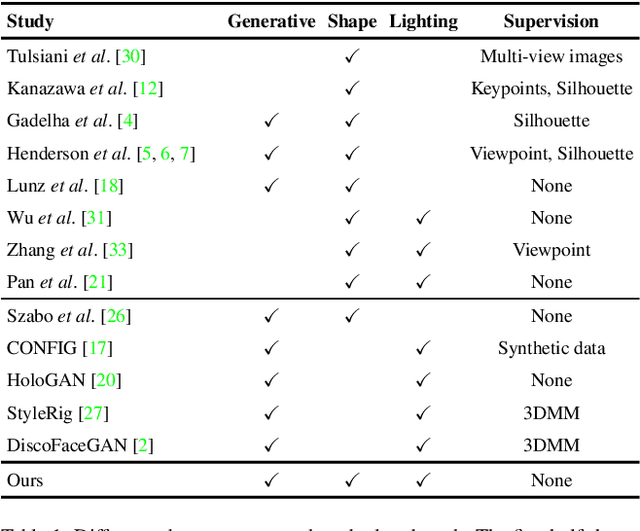
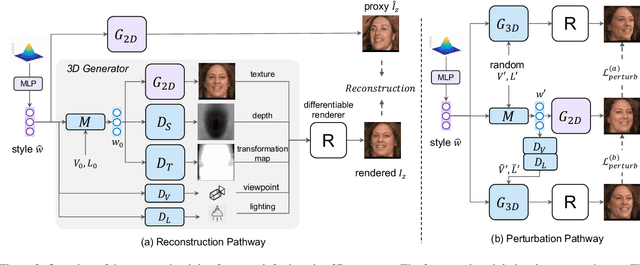
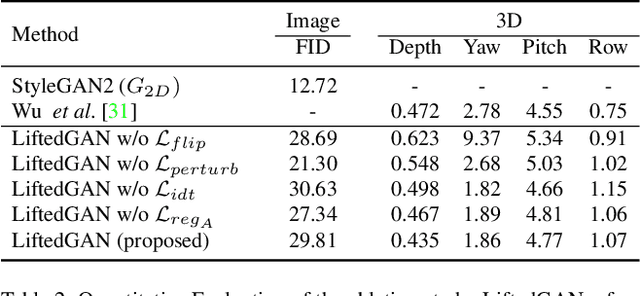

We propose a framework, called LiftedGAN, that disentangles and lifts a pre-trained StyleGAN2 for 3D-aware face generation. Our model is "3D-aware" in the sense that it is able to (1) disentangle the latent space of StyleGAN2 into texture, shape, viewpoint, lighting and (2) generate 3D components for rendering synthetic images. Unlike most previous methods, our method is completely self-supervised, i.e. it neither requires any manual annotation nor 3DMM model for training. Instead, it learns to generate images as well as their 3D components by distilling the prior knowledge in StyleGAN2 with a differentiable renderer. The proposed model is able to output both the 3D shape and texture, allowing explicit pose and lighting control over generated images. Qualitative and quantitative results show the superiority of our approach over existing methods on 3D-controllable GANs in content controllability while generating realistic high quality images.
Infant-ID: Fingerprints for Global Good
Oct 07, 2020
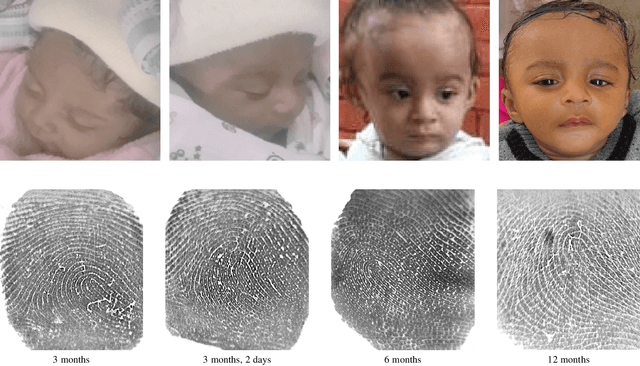
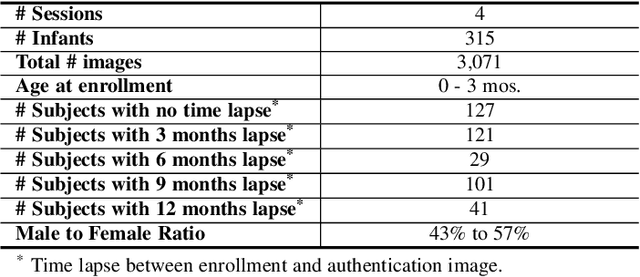
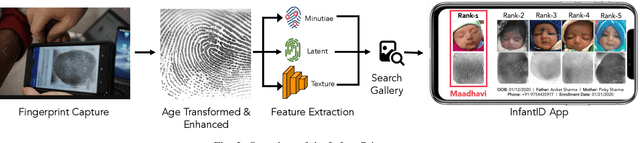
In many of the least developed and developing countries, a multitude of infants continue to suffer and die from vaccine-preventable diseases and malnutrition. Lamentably, the lack of official identification documentation makes it exceedingly difficult to track which infants have been vaccinated and which infants have received nutritional supplements. Answering these questions could prevent this infant suffering and premature death around the world. To that end, we propose Infant-Prints, an end-to-end, low-cost, infant fingerprint recognition system. Infant-Prints is comprised of our (i) custom built, compact, low-cost (85 USD), high-resolution (1,900 ppi), ergonomic fingerprint reader, and (ii) high-resolution infant fingerprint matcher. To evaluate the efficacy of Infant-Prints, we collected a longitudinal infant fingerprint database captured in 4 different sessions over a 12-month time span (December 2018 to January 2020), from 315 infants at the Saran Ashram Hospital, a charitable hospital in Dayalbagh, Agra, India. Our experimental results demonstrate, for the first time, that Infant-Prints can deliver accurate and reliable recognition (over time) of infants enrolled between the ages of 2-3 months, in time for effective delivery of vaccinations, healthcare, and nutritional supplements (TAR=95.2% @ FAR = 1.0% for infants aged 8-16 weeks at enrollment and authenticated 3 months later).
White-Box Evaluation of Fingerprint Recognition Systems
Aug 01, 2020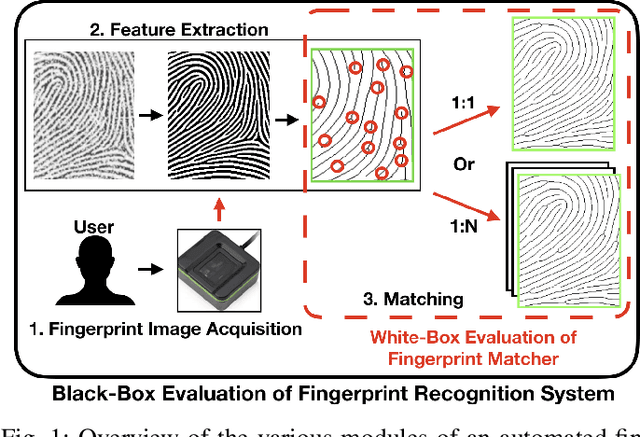
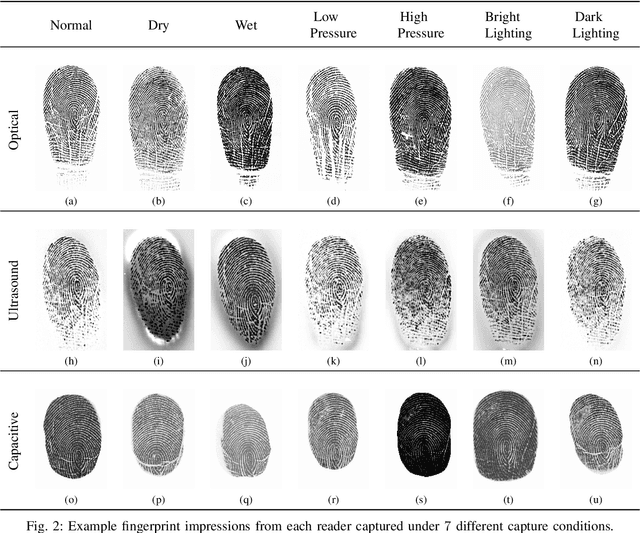
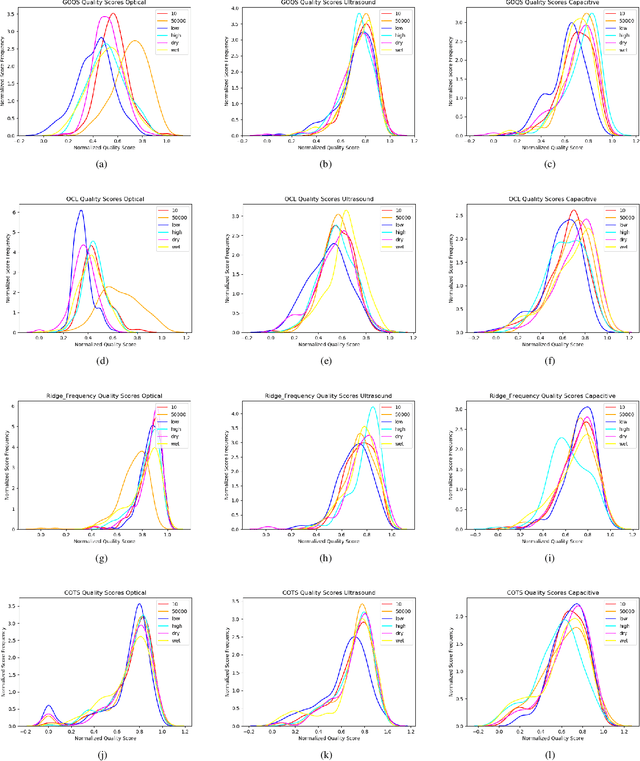

Typical evaluations of fingerprint recognition systems consist of end-to-end black-box evaluations, which assess performance in terms of overall identification or authentication accuracy. However, these black-box tests of system performance do not reveal insights into the performance of the individual modules, including image acquisition, feature extraction, and matching. On the other hand, white-box evaluations, the topic of this paper, measure the individual performance of each constituent module in isolation. While a few studies have conducted white-box evaluations of the fingerprint reader, feature extractor, and matching components, no existing study has provided a full system, white-box analysis of the uncertainty introduced at each stage of a fingerprint recognition system. In this work, we extend previous white-box evaluations of fingerprint recognition system components and provide a unified, in-depth analysis of fingerprint recognition system performance based on the aggregated white-box evaluation results. In particular, we analyze the uncertainty introduced at each stage of the fingerprint recognition system due to adverse capture conditions (i.e., varying illumination, moisture, and pressure) at the time of acquisition. Our experiments show that a system that performs better overall, in terms of black-box recognition performance, does not necessarily perform best at each module in the fingerprint recognition system pipeline, which can only be seen with white-box analysis of each sub-module. Findings such as these enable researchers to better focus their efforts in improving fingerprint recognition systems.
Look Locally Infer Globally: A Generalizable Face Anti-Spoofing Approach
Jun 15, 2020
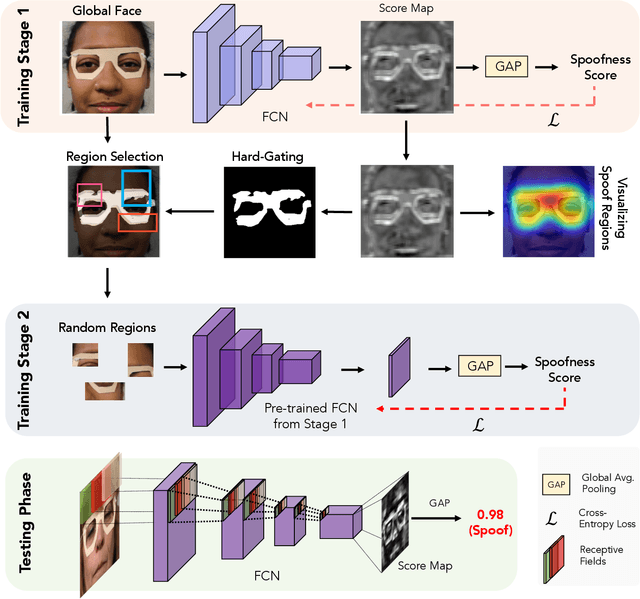
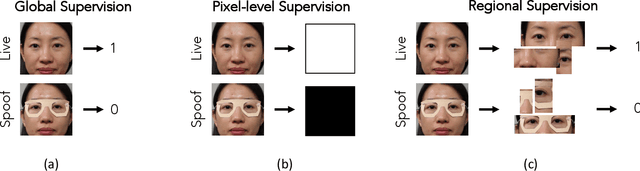

State-of-the-art spoof detection methods tend to overfit to the spoof types seen during training and fail to generalize to unknown spoof types. Given that face anti-spoofing is inherently a local task, we propose a face anti-spoofing framework, namely Self-Supervised Regional Fully Convolutional Network (SSR-FCN), that is trained to learn local discriminative cues from a face image in a self-supervised manner. The proposed framework improves generalizability while maintaining the computational efficiency of holistic face anti-spoofing approaches (< 4 ms on a Nvidia GTX 1080Ti GPU). The proposed method is interpretable since it localizes which parts of the face are labeled as spoofs. Experimental results show that SSR-FCN can achieve TDR = 65% @ 2.0% FDR when evaluated on a dataset comprising of 13 different spoof types under unknown attacks while achieving competitive performances under standard benchmark datasets (Oulu-NPU, CASIA-MFSD, and Replay-Attack).
Mitigating Face Recognition Bias via Group Adaptive Classifier
Jun 13, 2020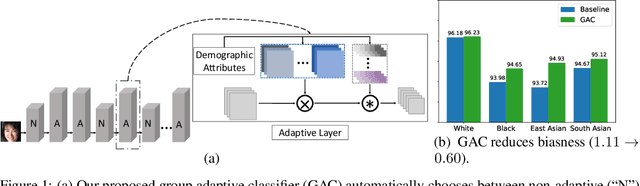
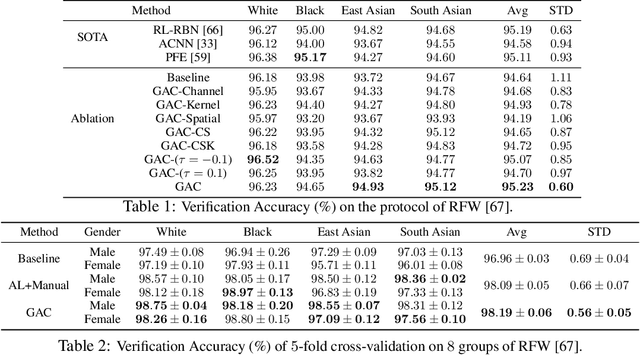
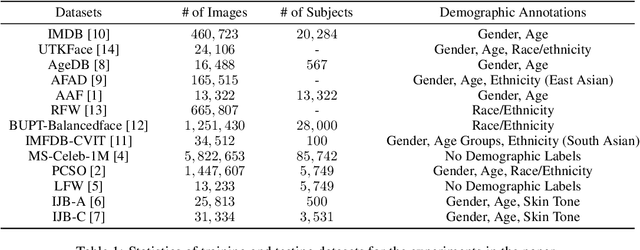
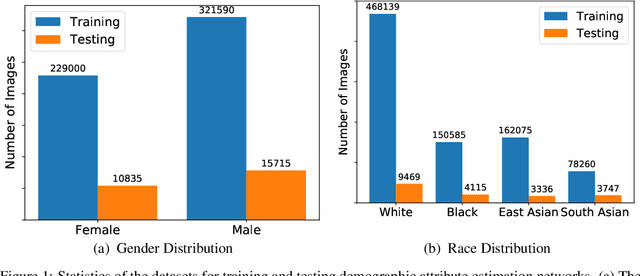
Face recognition is known to exhibit bias - subjects in certain demographic group can be better recognized than other groups. This work aims to learn a fair face representation, where faces of every group could be equally well-represented. Our proposed group adaptive classifier, GAC, learns to mitigate bias by using adaptive convolution kernels and attention mechanisms on faces based on their demographic attributes. The adaptive module comprises kernel masks and channel-wise attention maps for each demographic group so as to activate different facial regions for identification, leading to more discriminative features pertinent to their demographics. We also introduce an automated adaptation strategy which determines whether to apply adaptation to a certain layer by iteratively computing the dissimilarity among demographic-adaptive parameters, thereby increasing the efficiency of the adaptation learning. Experiments on benchmark face datasets (RFW, LFW, IJB-A, and IJB-C) show that our framework is able to mitigate face recognition bias on various demographic groups as well as maintain the competitive performance.
DashCam Pay: A System for In-vehicle Payments Using Face and Voice
Apr 08, 2020
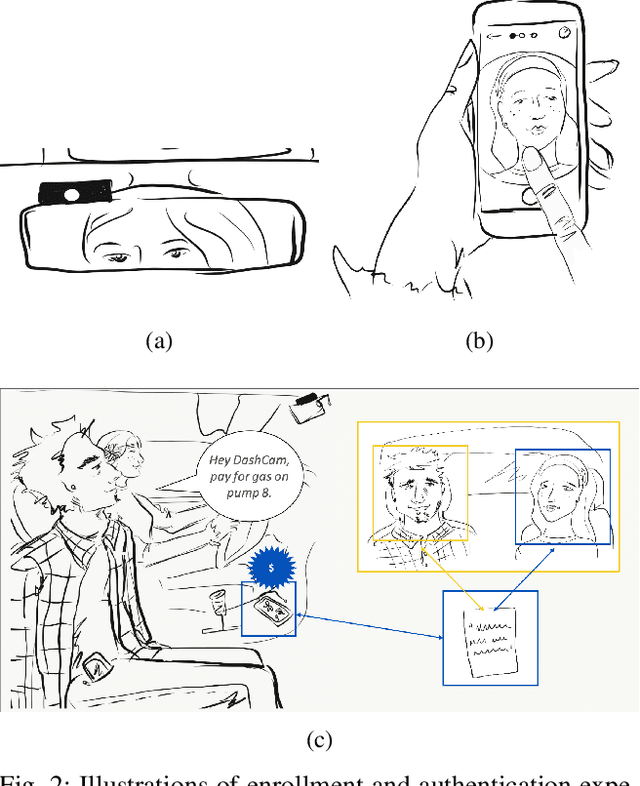
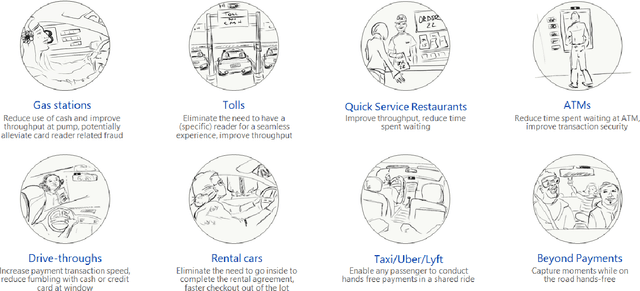

We present an open loop system, called DashCam Pay, that enables in-vehicle payments using face and voice biometrics. The system uses a plug-and-play device (dashcam) mounted in the vehicle to capture face images and voice commands of passengers. The dashcam is connected to mobile devices of passengers sitting in the vehicle, and uses privacy-preserving biometric comparison techniques to compare the biometric data captured by the dashcam with the biometric data enrolled on the users' mobile devices to determine the payer. Once the payer is verified, payment is initiated via the mobile device of the payer. For initial feasibility analysis, we collected data from 20 different subjects at two different sites using a commercially available dashcam, and evaluated open-source biometric algorithms on the collected data. Subsequently, we built an android prototype of the proposed system using open-source software packages to demonstrate the utility of the proposed system in facilitating secure in-vehicle payments. DashCam Pay can be integrated either by dashcam or vehicle manufacturers to enable open loop in-vehicle payments. We also discuss the applicability of the system to other payments scenarios, such as in-store payments.
Fingerprint Presentation Attack Detection: A Sensor and Material Agnostic Approach
Apr 06, 2020
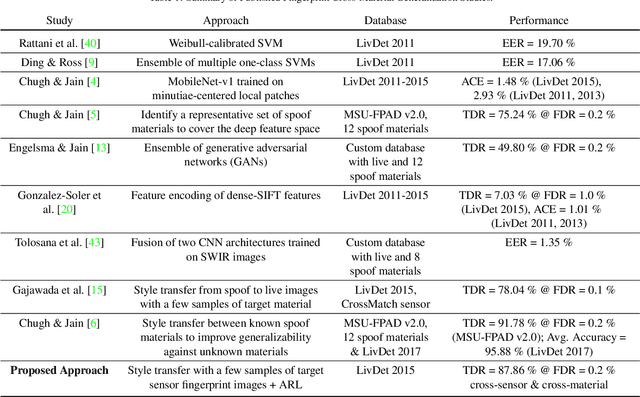
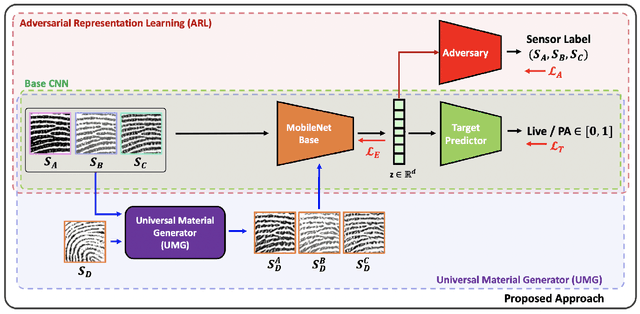
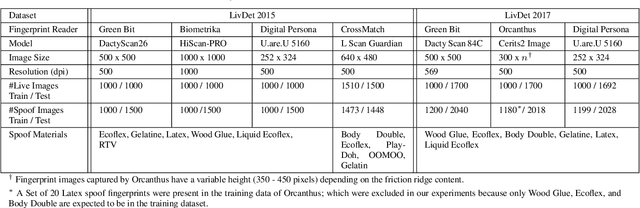
The vulnerability of automated fingerprint recognition systems to presentation attacks (PA), i.e., spoof or altered fingers, has been a growing concern, warranting the development of accurate and efficient presentation attack detection (PAD) methods. However, one major limitation of the existing PAD solutions is their poor generalization to new PA materials and fingerprint sensors, not used in training. In this study, we propose a robust PAD solution with improved cross-material and cross-sensor generalization. Specifically, we build on top of any CNN-based architecture trained for fingerprint spoof detection combined with cross-material spoof generalization using a style transfer network wrapper. We also incorporate adversarial representation learning (ARL) in deep neural networks (DNN) to learn sensor and material invariant representations for PAD. Experimental results on LivDet 2015 and 2017 public domain datasets exhibit the effectiveness of the proposed approach.
HERS: Homomorphically Encrypted Representation Search
Mar 27, 2020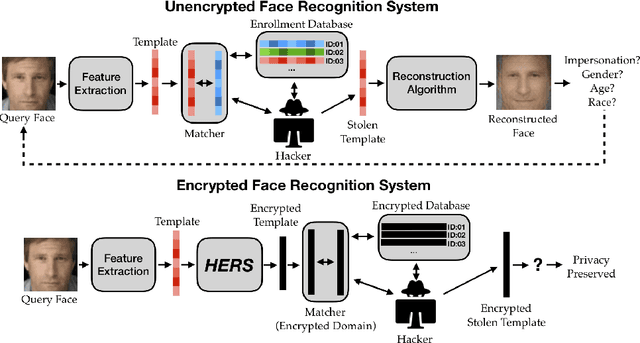
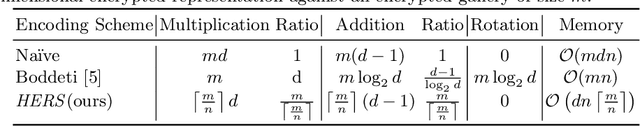
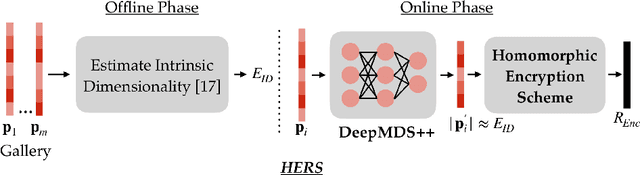

We present a method to search for a probe (or query) image representation against a large gallery in the encrypted domain. We require that the probe and gallery images be represented in terms of a fixed-length representation, which is typical for representations obtained from learned networks. Our encryption scheme is agnostic to how the fixed-length representation is obtained and can, therefore, be applied to any fixed-length representation in any application domain. Our method, dubbed HERS (Homomorphically Encrypted Representation Search), operates by (i) compressing the representation towards its estimated intrinsic dimensionality, (ii) encrypting the compressed representation using the proposed fully homomorphic encryption scheme, and (iii) searching against a gallery of encrypted representations directly in the encrypted domain, without decrypting them, and with minimal loss of accuracy. Numerical results on large galleries of face, fingerprint, and object datasets such as ImageNet show that, for the first time, accurate and fast image search within the encrypted domain is feasible at scale (296 seconds; 46x speedup over state-of-the-art for face search against a background of 1 million).