 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChild Palm-ID: Contactless Palmprint Recognition for Children
May 09, 2023



Effective distribution of nutritional and healthcare aid for children, particularly infants and toddlers, in some of the least developed and most impoverished countries of the world, is a major problem due to the lack of reliable identification documents. Biometric authentication technology has been investigated to address child recognition in the absence of reliable ID documents. We present a mobile-based contactless palmprint recognition system, called Child Palm-ID, which meets the requirements of usability, hygiene, cost, and accuracy for child recognition. Using a contactless child palmprint database, Child-PalmDB1, consisting of 19,158 images from 1,020 unique palms (in the age range of 6 mos. to 48 mos.), we report a TAR=94.11% @ FAR=0.1%. The proposed Child Palm-ID system is also able to recognize adults, achieving a TAR=99.4% on the CASIA contactless palmprint database and a TAR=100% on the COEP contactless adult palmprint database, both @ FAR=0.1%. These accuracies are competitive with the SOTA provided by COTS systems. Despite these high accuracies, we show that the TAR for time-separated child-palmprints is only 78.1% @ FAR=0.1%.
Latent Fingerprint Recognition: Fusion of Local and Global Embeddings
Apr 26, 2023



One of the most challenging problems in fingerprint recognition continues to be establishing the identity of a suspect associated with partial and smudgy fingerprints left at a crime scene (i.e., latent prints or fingermarks). Despite the success of fixed-length embeddings for rolled and slap fingerprint recognition, the features learned for latent fingerprint matching have mostly been limited to local minutiae-based embeddings and have not directly leveraged global representations for matching. In this paper, we combine global embeddings with local embeddings for state-of-the-art latent to rolled matching accuracy with high throughput. The combination of both local and global representations leads to improved recognition accuracy across NIST SD 27, NIST SD 302, MSP, MOLF DB1/DB4, and MOLF DB2/DB4 latent fingerprint datasets for both closed-set (84.11%, 54.36%, 84.35%, 70.43%, 62.86% rank-1 retrieval rate, respectively) and open-set (0.50, 0.74, 0.44, 0.60, 0.68 FNIR at FPIR=0.02, respectively) identification scenarios on a gallery of 100K rolled fingerprints. Not only do we fuse the complimentary representations, we also use the local features to guide the global representations to focus on discriminatory regions in two fingerprint images to be compared. This leads to a multi-stage matching paradigm in which subsets of the retrieved candidate lists for each probe image are passed to subsequent stages for further processing, resulting in a considerable reduction in latency (requiring just 0.068 ms per latent to rolled comparison on a AMD EPYC 7543 32-Core Processor, roughly 15K comparisons per second). Finally, we show the generalizability of the fused representations for improving authentication accuracy across several rolled, plain, and contactless fingerprint datasets.
Child PalmID: Contactless Palmprint Recognition
Dec 14, 2022



Developing and least developed countries face the dire challenge of ensuring that each child in their country receives required doses of vaccination, adequate nutrition and proper medication. International agencies such as UNICEF, WHO and WFP, among other organizations, strive to find innovative solutions to determine which child has received the benefits and which have not. Biometric recognition systems have been sought out to help solve this problem. To that end, this report establishes a baseline accuracy of a commercial contactless palmprint recognition system that may be deployed for recognizing children in the age group of one to five years old. On a database of contactless palmprint images of one thousand unique palms from 500 children, we establish SOTA authentication accuracy of 90.85% @ FAR of 0.01%, rank-1 identification accuracy of 99.0% (closed set), and FPIR=0.01 @ FNIR=0.3 for open-set identification using PalmMobile SDK from Armatura.
AFR-Net: Attention-Driven Fingerprint Recognition Network
Dec 03, 2022



The use of vision transformers (ViT) in computer vision is increasing due to limited inductive biases (e.g., locality, weight sharing, etc.) and increased scalability compared to other deep learning methods. This has led to some initial studies on the use of ViT for biometric recognition, including fingerprint recognition. In this work, we improve on these initial studies for transformers in fingerprint recognition by i.) evaluating additional attention-based architectures, ii.) scaling to larger and more diverse training and evaluation datasets, and iii.) combining the complimentary representations of attention-based and CNN-based embeddings for improved state-of-the-art (SOTA) fingerprint recognition (both authentication and identification). Our combined architecture, AFR-Net (Attention-Driven Fingerprint Recognition Network), outperforms several baseline transformer and CNN-based models, including a SOTA commercial fingerprint system, Verifinger v12.3, across intra-sensor, cross-sensor, and latent to rolled fingerprint matching datasets. Additionally, we propose a realignment strategy using local embeddings extracted from intermediate feature maps within the networks to refine the global embeddings in low certainty situations, which boosts the overall recognition accuracy significantly across each of the models. This realignment strategy requires no additional training and can be applied as a wrapper to any existing deep learning network (including attention-based, CNN-based, or both) to boost its performance.
Minutiae-Guided Fingerprint Embeddings via Vision Transformers
Oct 26, 2022



Minutiae matching has long dominated the field of fingerprint recognition. However, deep networks can be used to extract fixed-length embeddings from fingerprints. To date, the few studies that have explored the use of CNN architectures to extract such embeddings have shown extreme promise. Inspired by these early works, we propose the first use of a Vision Transformer (ViT) to learn a discriminative fixed-length fingerprint embedding. We further demonstrate that by guiding the ViT to focus in on local, minutiae related features, we can boost the recognition performance. Finally, we show that by fusing embeddings learned by CNNs and ViTs we can reach near parity with a commercial state-of-the-art (SOTA) matcher. In particular, we obtain a TAR=94.23% @ FAR=0.1% on the NIST SD 302 public-domain dataset, compared to a SOTA commercial matcher which obtains TAR=96.71% @ FAR=0.1%. Additionally, our fixed-length embeddings can be matched orders of magnitude faster than the commercial system (2.5 million matches/second compared to 50K matches/second). We make our code and models publicly available to encourage further research on this topic: https://github.com/tba.
Learning an Ensemble of Deep Fingerprint Representations
Sep 02, 2022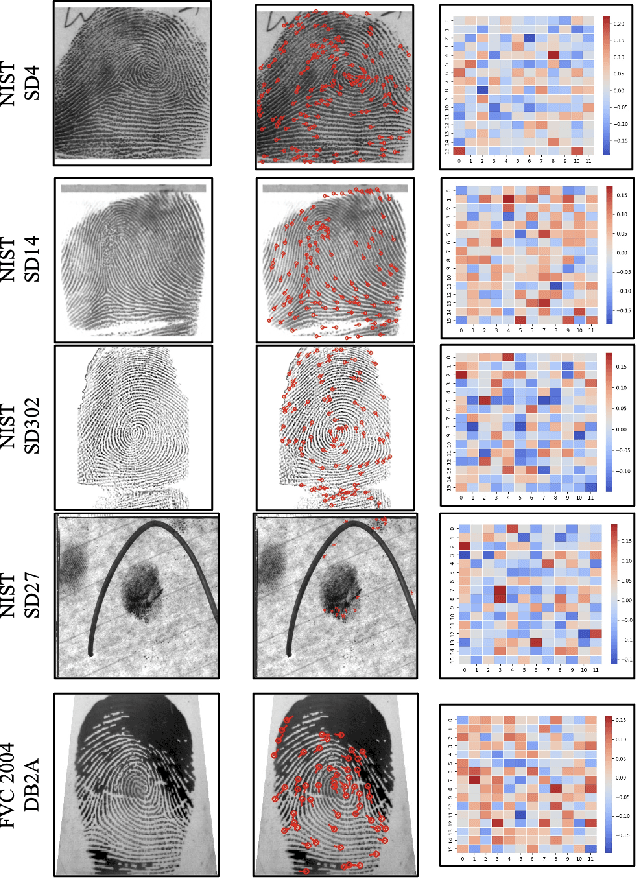

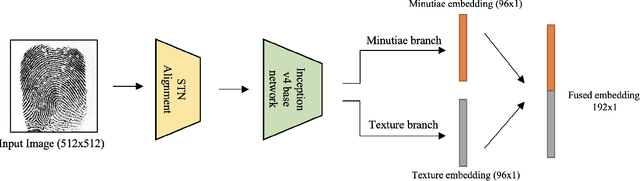
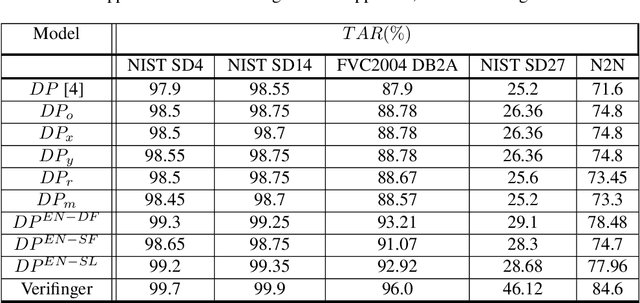
Deep neural networks (DNNs) have shown incredible promise in learning fixed-length representations from fingerprints. Since the representation learning is often focused on capturing specific prior knowledge (e.g., minutiae), there is no universal representation that comprehensively encapsulates all the discriminatory information available in a fingerprint. While learning an ensemble of representations can mitigate this problem, two critical challenges need to be addressed: (i) How to extract multiple diverse representations from the same fingerprint image? and (ii) How to optimally exploit these representations during the matching process? In this work, we train multiple instances of DeepPrint (a state-of-the-art DNN-based fingerprint encoder) on different transformations of the input image to generate an ensemble of fingerprint embeddings. We also propose a feature fusion technique that distills these multiple representations into a single embedding, which faithfully captures the diversity present in the ensemble without increasing the computational complexity. The proposed approach has been comprehensively evaluated on five databases containing rolled, plain, and latent fingerprints (NIST SD4, NIST SD14, NIST SD27, NIST SD302, and FVC2004 DB2A) and statistically significant improvements in accuracy have been consistently demonstrated across a range of verification as well as closed- and open-set identification settings. The proposed approach serves as a wrapper capable of improving the accuracy of any DNN-based recognition system.
Synthetic Latent Fingerprint Generator
Aug 29, 2022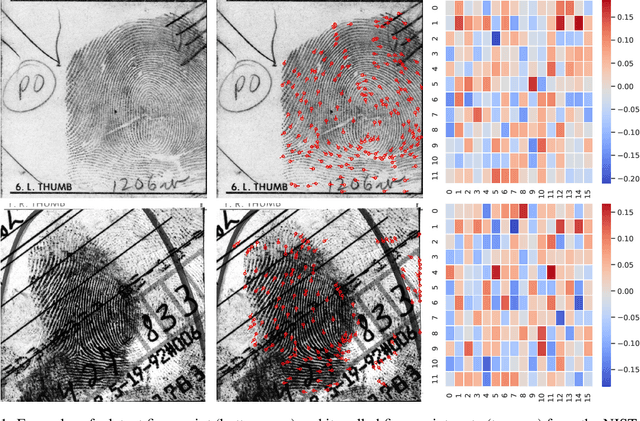
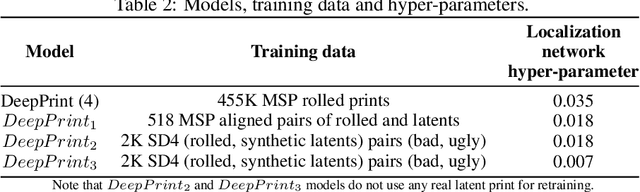
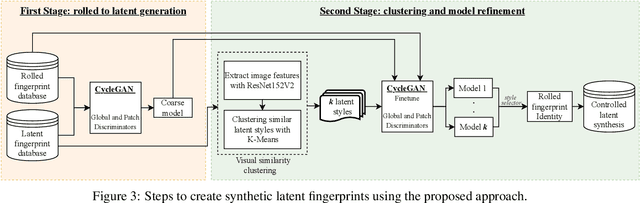
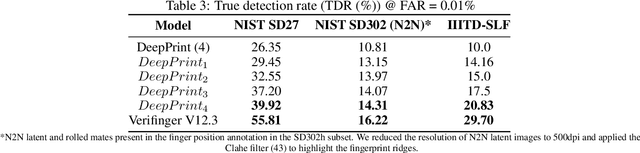
Given a full fingerprint image (rolled or slap), we present CycleGAN models to generate multiple latent impressions of the same identity as the full print. Our models can control the degree of distortion, noise, blurriness and occlusion in the generated latent print images to obtain Good, Bad and Ugly latent image categories as introduced in the NIST SD27 latent database. The contributions of our work are twofold: (i) demonstrate the similarity of synthetically generated latent fingerprint images to crime scene latents in NIST SD27 and MSP databases as evaluated by the NIST NFIQ 2 quality measure and ROC curves obtained by a SOTA fingerprint matcher, and (ii) use of synthetic latents to augment small-size latent training databases in the public domain to improve the performance of DeepPrint, a SOTA fingerprint matcher designed for rolled to rolled fingerprint matching on three latent databases (NIST SD27, NIST SD302, and IIITD-SLF). As an example, with synthetic latent data augmentation, the Rank-1 retrieval performance of DeepPrint is improved from 15.50% to 29.07% on challenging NIST SD27 latent database. Our approach for generating synthetic latent fingerprints can be used to improve the recognition performance of any latent matcher and its individual components (e.g., enhancement, segmentation and feature extraction).
On Demographic Bias in Fingerprint Recognition
May 19, 2022
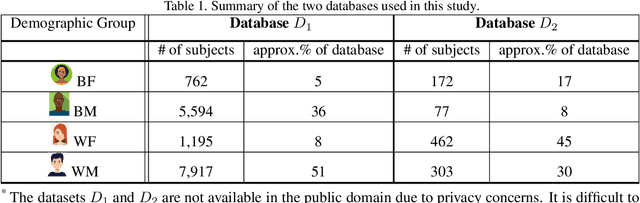
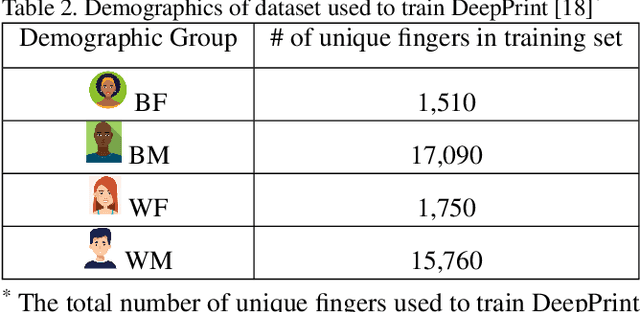
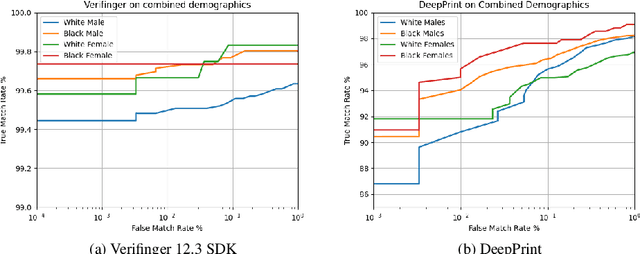
Fingerprint recognition systems have been deployed globally in numerous applications including personal devices, forensics, law enforcement, banking, and national identity systems. For these systems to be socially acceptable and trustworthy, it is critical that they perform equally well across different demographic groups. In this work, we propose a formal statistical framework to test for the existence of bias (demographic differentials) in fingerprint recognition across four major demographic groups (white male, white female, black male, and black female) for two state-of-the-art (SOTA) fingerprint matchers operating in verification and identification modes. Experiments on two different fingerprint databases (with 15,468 and 1,014 subjects) show that demographic differentials in SOTA fingerprint recognition systems decrease as the matcher accuracy increases and any small bias that may be evident is likely due to certain outlier, low-quality fingerprint images.
Fingerprint Template Invertibility: Minutiae vs. Deep Templates
May 08, 2022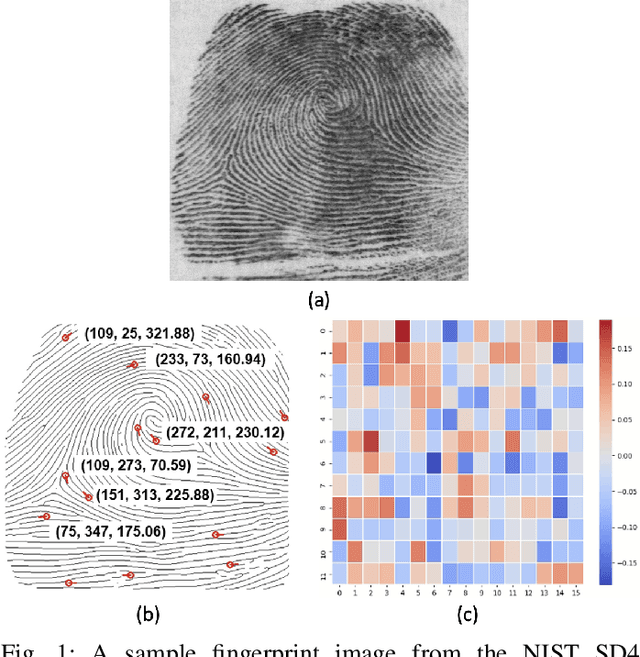

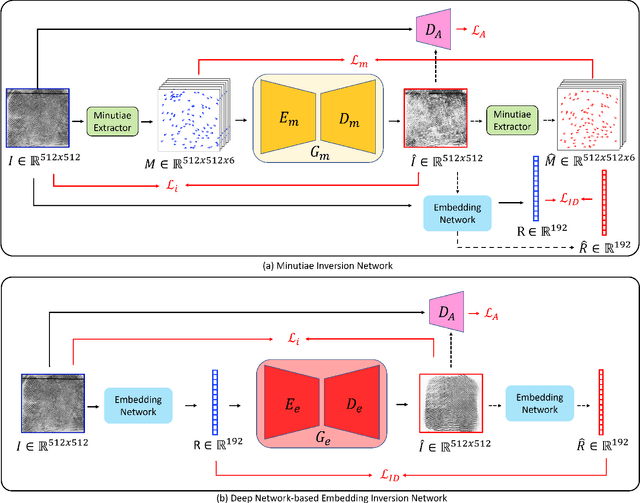

Much of the success of fingerprint recognition is attributed to minutiae-based fingerprint representation. It was believed that minutiae templates could not be inverted to obtain a high fidelity fingerprint image, but this assumption has been shown to be false. The success of deep learning has resulted in alternative fingerprint representations (embeddings), in the hope that they might offer better recognition accuracy as well as non-invertibility of deep network-based templates. We evaluate whether deep fingerprint templates suffer from the same reconstruction attacks as the minutiae templates. We show that while a deep template can be inverted to produce a fingerprint image that could be matched to its source image, deep templates are more resistant to reconstruction attacks than minutiae templates. In particular, reconstructed fingerprint images from minutiae templates yield a TAR of about 100.0% (98.3%) @ FAR of 0.01% for type-I (type-II) attacks using a state-of-the-art commercial fingerprint matcher, when tested on NIST SD4. The corresponding attack performance for reconstructed fingerprint images from deep templates using the same commercial matcher yields a TAR of less than 1% for both type-I and type-II attacks; however, when the reconstructed images are matched using the same deep network, they achieve a TAR of 85.95% (68.10%) for type-I (type-II) attacks. Furthermore, what is missing from previous fingerprint template inversion studies is an evaluation of the black-box attack performance, which we perform using 3 different state-of-the-art fingerprint matchers. We conclude that fingerprint images generated by inverting minutiae templates are highly susceptible to both white-box and black-box attack evaluations, while fingerprint images generated by deep templates are resistant to black-box evaluations and comparatively less susceptible to white-box evaluations.
SpoofGAN: Synthetic Fingerprint Spoof Images
Apr 15, 2022
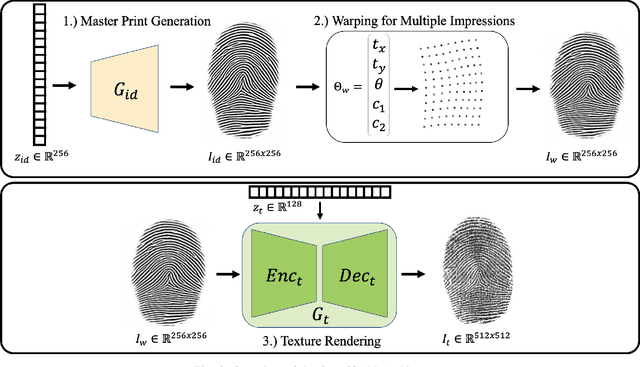


A major limitation to advances in fingerprint spoof detection is the lack of publicly available, large-scale fingerprint spoof datasets, a problem which has been compounded by increased concerns surrounding privacy and security of biometric data. Furthermore, most state-of-the-art spoof detection algorithms rely on deep networks which perform best in the presence of a large amount of training data. This work aims to demonstrate the utility of synthetic (both live and spoof) fingerprints in supplying these algorithms with sufficient data to improve the performance of fingerprint spoof detection algorithms beyond the capabilities when training on a limited amount of publicly available real datasets. First, we provide details of our approach in modifying a state-of-the-art generative architecture to synthesize high quality live and spoof fingerprints. Then, we provide quantitative and qualitative analysis to verify the quality of our synthetic fingerprints in mimicking the distribution of real data samples. We showcase the utility of our synthetic live and spoof fingerprints in training a deep network for fingerprint spoof detection, which dramatically boosts the performance across three different evaluation datasets compared to an identical model trained on real data alone. Finally, we demonstrate that only 25% of the original (real) dataset is required to obtain similar detection performance when augmenting the training dataset with synthetic data.