 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Improvement Heuristics for Solving the Travelling Salesman Problem
Dec 12, 2019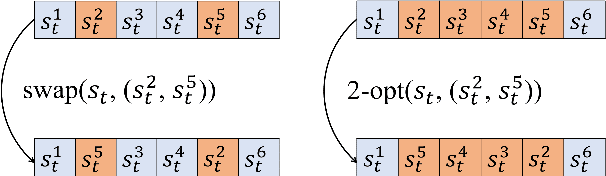
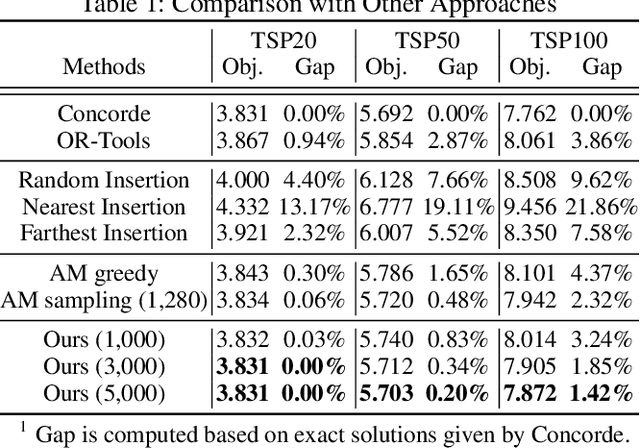
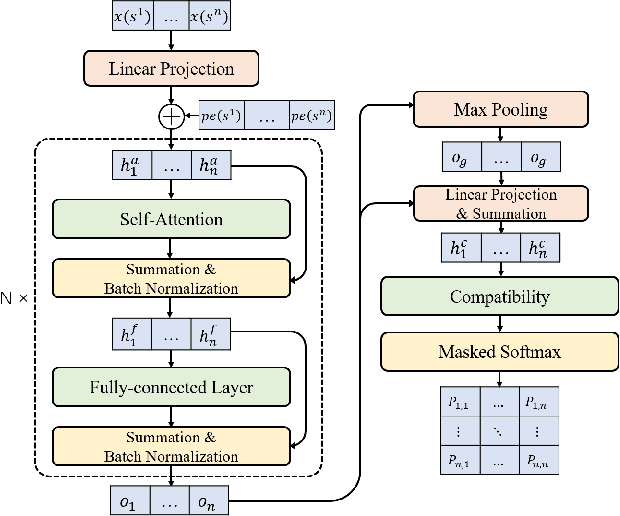
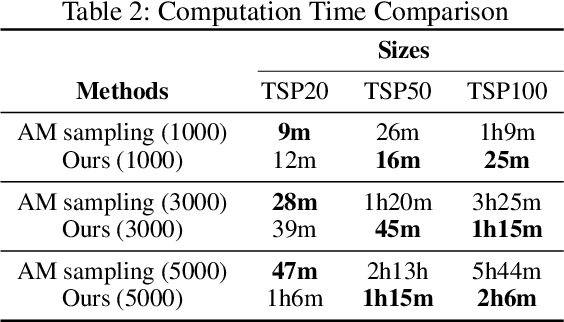
Recent studies in using deep learning to solve the Travelling Salesman Problem (TSP) focus on construction heuristics, the solution of which may still be far from optimality. To improve solution quality, additional procedures such as sampling or beam search are required. However, they are still based on the same construction policy, which is less effective in refining a solution. In this paper, we propose to directly learn the improvement heuristics for solving TSP based on deep reinforcement learning.We first present a reinforcement learning formulation for the improvement heuristic, where the policy guides selection of the next solution. Then, we propose a deep architecture as the policy network based on self-attention. Extensive experiments show that, improvement policies learned by our approach yield better results than state-of-the-art methods, even from random initial solutions. Moreover, the learned policies are more effective than the traditional hand-crafted ones, and robust to different initial solutions with either high or poor quality.
Learning Robust Features using Deep Learning for Automatic Seizure Detection
Jul 31, 2016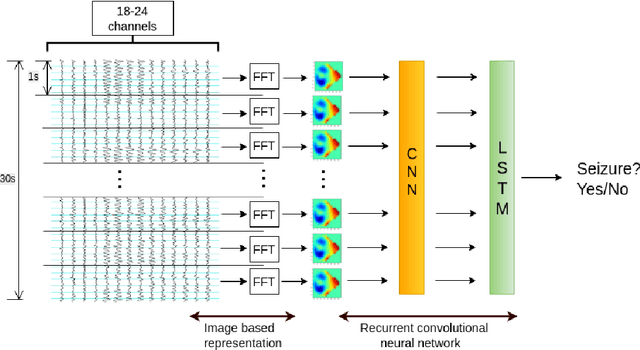
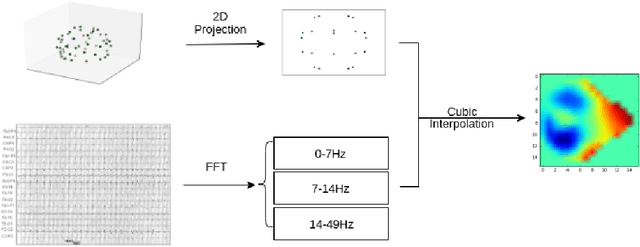
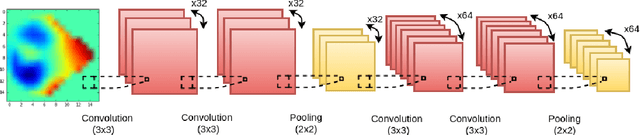
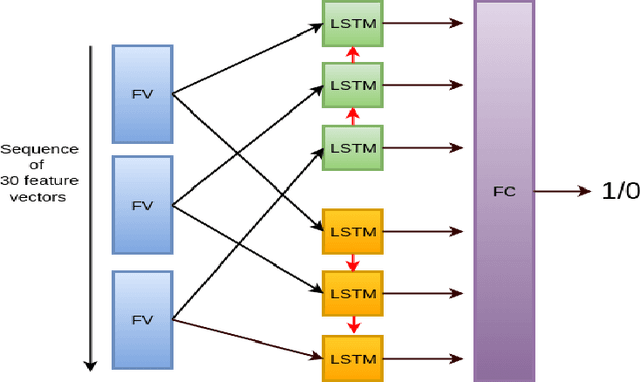
We present and evaluate the capacity of a deep neural network to learn robust features from EEG to automatically detect seizures. This is a challenging problem because seizure manifestations on EEG are extremely variable both inter- and intra-patient. By simultaneously capturing spectral, temporal and spatial information our recurrent convolutional neural network learns a general spatially invariant representation of a seizure. The proposed approach exceeds significantly previous results obtained on cross-patient classifiers both in terms of sensitivity and false positive rate. Furthermore, our model proves to be robust to missing channel and variable electrode montage.
A Tabu Search Algorithm for the Multi-period Inspector Scheduling Problem
Sep 17, 2014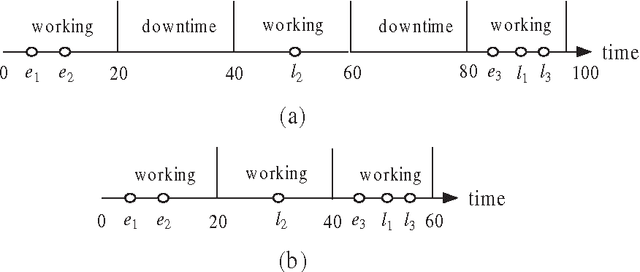

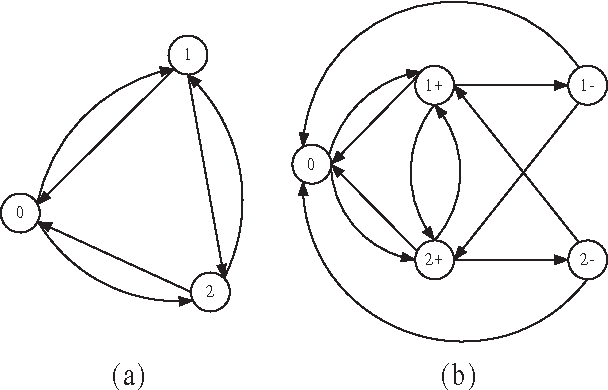
This paper introduces a multi-period inspector scheduling problem (MPISP), which is a new variant of the multi-trip vehicle routing problem with time windows (VRPTW). In the MPISP, each inspector is scheduled to perform a route in a given multi-period planning horizon. At the end of each period, each inspector is not required to return to the depot but has to stay at one of the vertices for recuperation. If the remaining time of the current period is insufficient for an inspector to travel from his/her current vertex $A$ to a certain vertex B, he/she can choose either waiting at vertex A until the start of the next period or traveling to a vertex C that is closer to vertex B. Therefore, the shortest transit time between any vertex pair is affected by the length of the period and the departure time. We first describe an approach of computing the shortest transit time between any pair of vertices with an arbitrary departure time. To solve the MPISP, we then propose several local search operators adapted from classical operators for the VRPTW and integrate them into a tabu search framework. In addition, we present a constrained knapsack model that is able to produce an upper bound for the problem. Finally, we evaluate the effectiveness of our algorithm with extensive experiments based on a set of test instances. Our computational results indicate that our approach generates high-quality solutions.
An Enhanced Branch-and-bound Algorithm for the Talent Scheduling Problem
Jan 23, 2014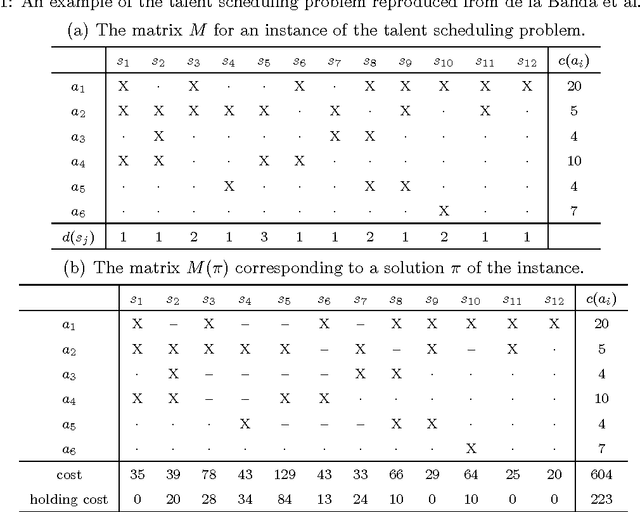
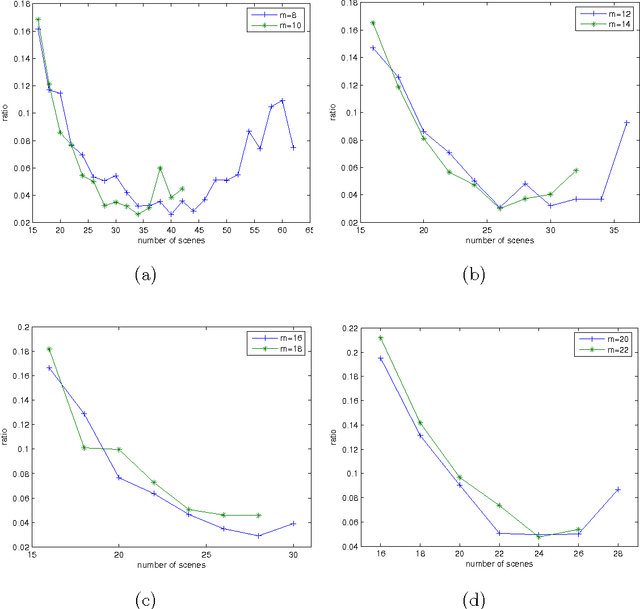

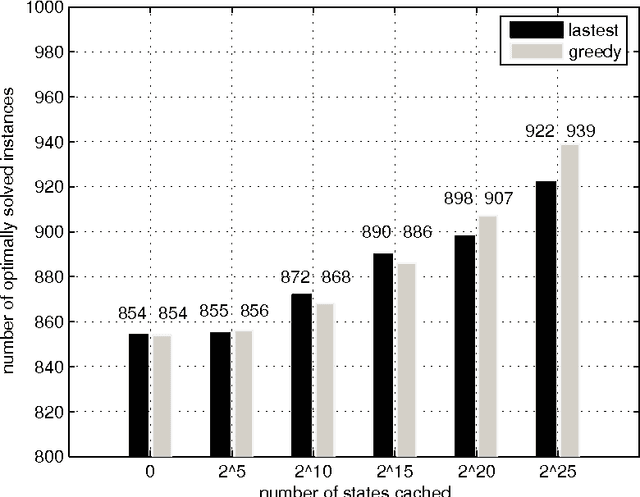
The talent scheduling problem is a simplified version of the real-world film shooting problem, which aims to determine a shooting sequence so as to minimize the total cost of the actors involved. In this article, we first formulate the problem as an integer linear programming model. Next, we devise a branch-and-bound algorithm to solve the problem. The branch-and-bound algorithm is enhanced by several accelerating techniques, including preprocessing, dominance rules and caching search states. Extensive experiments over two sets of benchmark instances suggest that our algorithm is superior to the current best exact algorithm. Finally, the impacts of different parameter settings are disclosed by some additional experiments.