 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers generalize differently from information stored in context vs in weights
Oct 11, 2022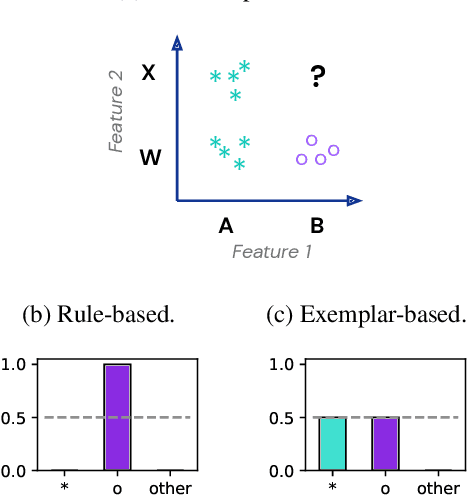
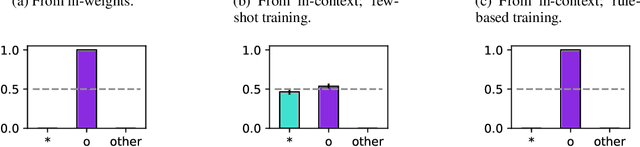
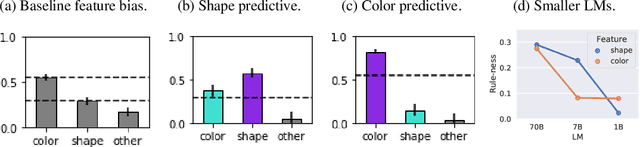
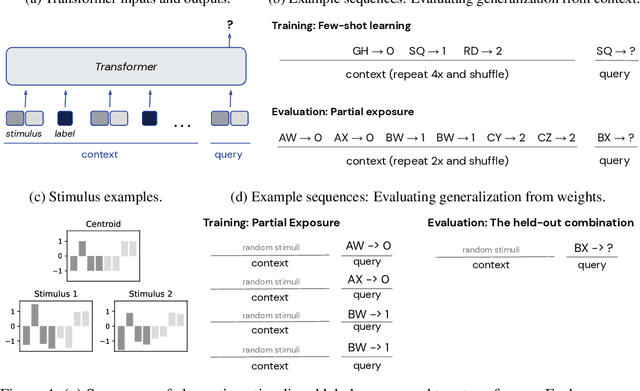
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.
Language models show human-like content effects on reasoning
Jul 14, 2022



Abstract reasoning is a key ability for an intelligent system. Large language models achieve above-chance performance on abstract reasoning tasks, but exhibit many imperfections. However, human abstract reasoning is also imperfect, and depends on our knowledge and beliefs about the content of the reasoning problem. For example, humans reason much more reliably about logical rules that are grounded in everyday situations than arbitrary rules about abstract attributes. The training experiences of language models similarly endow them with prior expectations that reflect human knowledge and beliefs. We therefore hypothesized that language models would show human-like content effects on abstract reasoning problems. We explored this hypothesis across three logical reasoning tasks: natural language inference, judging the logical validity of syllogisms, and the Wason selection task (Wason, 1968). We find that state of the art large language models (with 7 or 70 billion parameters; Hoffman et al., 2022) reflect many of the same patterns observed in humans across these tasks -- like humans, models reason more effectively about believable situations than unrealistic or abstract ones. Our findings have implications for understanding both these cognitive effects, and the factors that contribute to language model performance.
Know your audience: specializing grounded language models with the game of Dixit
Jun 16, 2022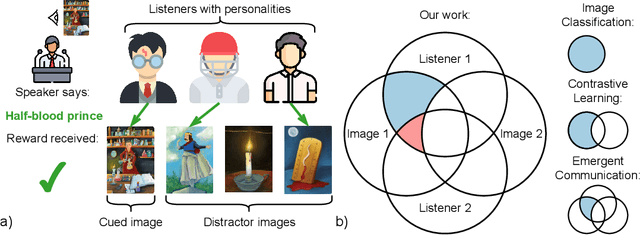
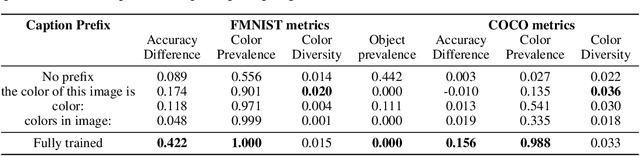
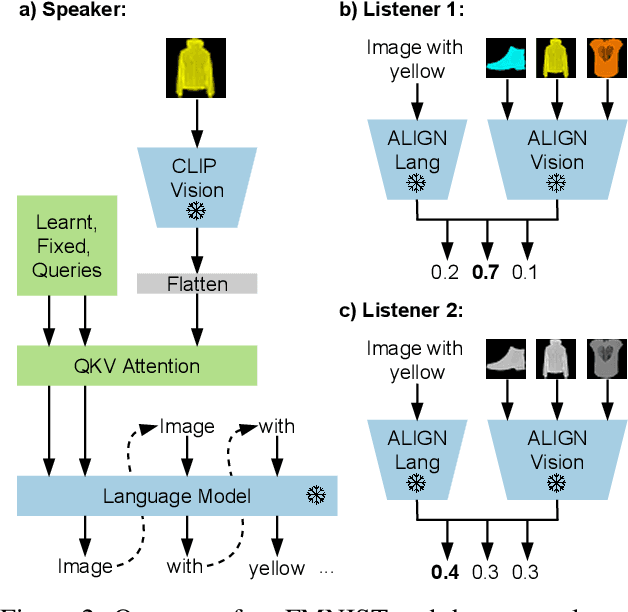
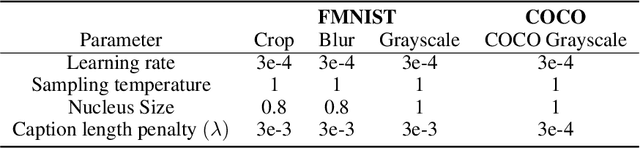
Effective communication requires adapting to the idiosyncratic common ground shared with each communicative partner. We study a particularly challenging instantiation of this problem: the popular game Dixit. We formulate a round of Dixit as a multi-agent image reference game where a (trained) speaker model is rewarded for describing a target image such that one (pretrained) listener model can correctly identify it from a pool of distractors, but another listener cannot. To adapt to this setting, the speaker must exploit differences in the common ground it shares with the different listeners. We show that finetuning an attention-based adapter between a CLIP vision encoder and a large language model in this contrastive, multi-agent setting gives rise to context-dependent natural language specialization from rewards only, without direct supervision. In a series of controlled experiments, we show that the speaker can adapt according to the idiosyncratic strengths and weaknesses of various pairs of different listeners. Furthermore, we show zero-shot transfer of the speaker's specialization to unseen real-world data. Our experiments offer a step towards adaptive communication in complex multi-partner settings and highlight the interesting research challenges posed by games like Dixit. We hope that our work will inspire creative new approaches to adapting pretrained models.
Semantic Exploration from Language Abstractions and Pretrained Representations
Apr 08, 2022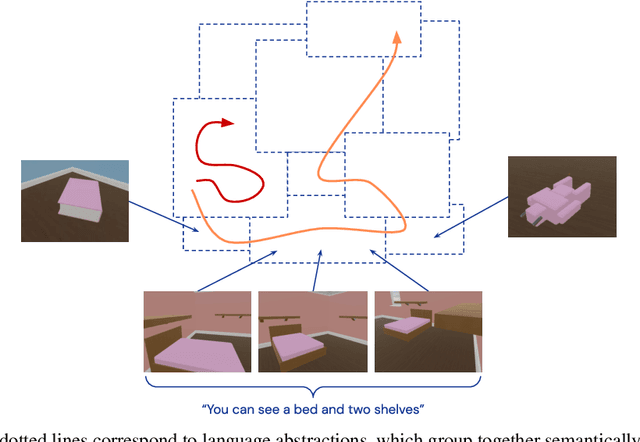


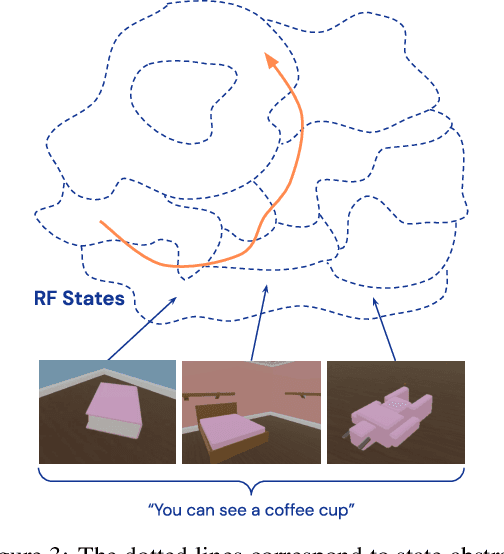
Continuous first-person 3D environments pose unique exploration challenges to reinforcement learning (RL) agents because of their high-dimensional state and action spaces. These challenges can be ameliorated by using semantically meaningful state abstractions to define novelty for exploration. We propose that learned representations shaped by natural language provide exactly this form of abstraction. In particular, we show that vision-language representations, when pretrained on image captioning datasets sampled from the internet, can drive meaningful, task-relevant exploration and improve performance on 3D simulated environments. We also characterize why and how language provides useful abstractions for exploration by comparing the impacts of using representations from a pretrained model, a language oracle, and several ablations. We demonstrate the benefits of our approach in two very different task domains -- one that stresses the identification and manipulation of everyday objects, and one that requires navigational exploration in an expansive world -- as well as two popular deep RL algorithms: Impala and R2D2. Our results suggest that using language-shaped representations could improve exploration for various algorithms and agents in challenging environments.
Can language models learn from explanations in context?
Apr 05, 2022
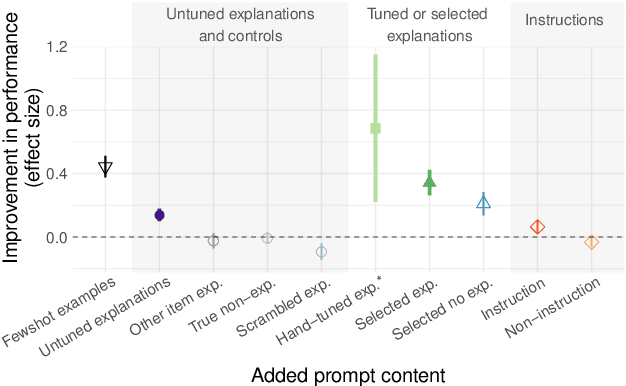
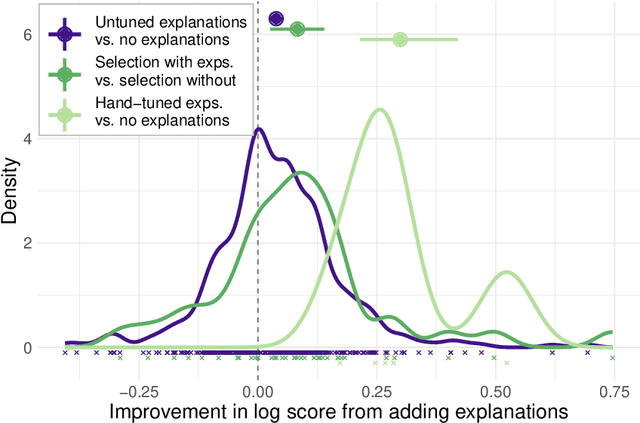

Large language models can perform new tasks by adapting to a few in-context examples. For humans, rapid learning from examples can benefit from explanations that connect examples to task principles. We therefore investigate whether explanations of few-shot examples can allow language models to adapt more effectively. We annotate a set of 40 challenging tasks from BIG-Bench with explanations of answers to a small subset of questions, as well as a variety of matched control explanations. We evaluate the effects of various zero-shot and few-shot prompts that include different types of explanations, instructions, and controls on the performance of a range of large language models. We analyze these results using statistical multilevel modeling techniques that account for the nested dependencies among conditions, tasks, prompts, and models. We find that explanations of examples can improve performance. Adding untuned explanations to a few-shot prompt offers a modest improvement in performance; about 1/3 the effect size of adding few-shot examples, but twice the effect size of task instructions. We then show that explanations tuned for performance on a small validation set offer substantially larger benefits; building a prompt by selecting examples and explanations together substantially improves performance over selecting examples alone. Hand-tuning explanations can substantially improve performance on challenging tasks. Furthermore, even untuned explanations outperform carefully matched controls, suggesting that the benefits are due to the link between an example and its explanation, rather than lower-level features of the language used. However, only large models can benefit from explanations. In summary, explanations can support the in-context learning abilities of large language models on
Zipfian environments for Reinforcement Learning
Mar 15, 2022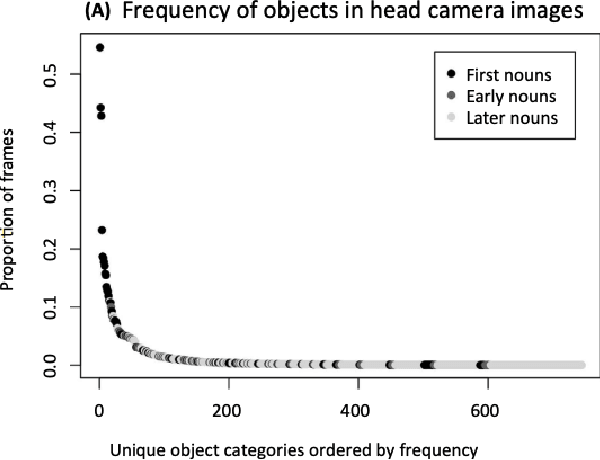
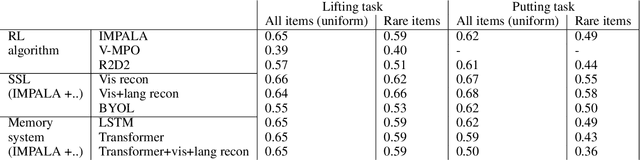
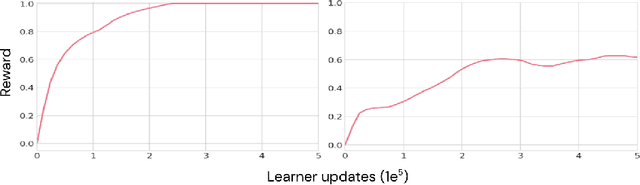
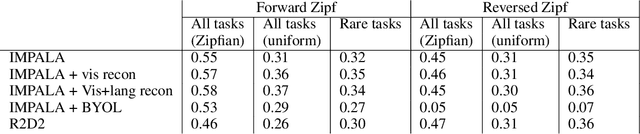
As humans and animals learn in the natural world, they encounter distributions of entities, situations and events that are far from uniform. Typically, a relatively small set of experiences are encountered frequently, while many important experiences occur only rarely. The highly-skewed, heavy-tailed nature of reality poses particular learning challenges that humans and animals have met by evolving specialised memory systems. By contrast, most popular RL environments and benchmarks involve approximately uniform variation of properties, objects, situations or tasks. How will RL algorithms perform in worlds (like ours) where the distribution of environment features is far less uniform? To explore this question, we develop three complementary RL environments where the agent's experience varies according to a Zipfian (discrete power law) distribution. On these benchmarks, we find that standard Deep RL architectures and algorithms acquire useful knowledge of common situations and tasks, but fail to adequately learn about rarer ones. To understand this failure better, we explore how different aspects of current approaches may be adjusted to help improve performance on rare events, and show that the RL objective function, the agent's memory system and self-supervised learning objectives can all influence an agent's ability to learn from uncommon experiences. Together, these results show that learning robustly from skewed experience is a critical challenge for applying Deep RL methods beyond simulations or laboratories, and our Zipfian environments provide a basis for measuring future progress towards this goal.
Tell me why! -- Explanations support learning of relational and causal structure
Dec 08, 2021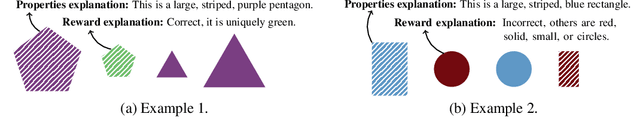
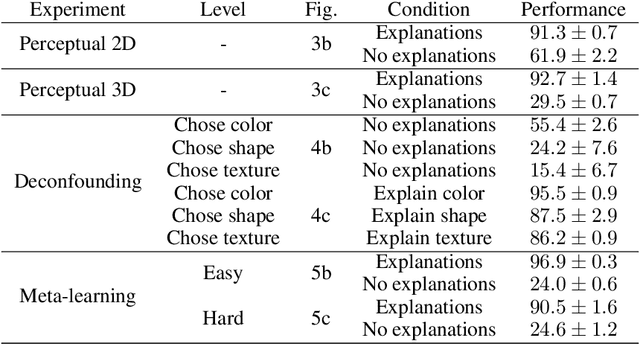
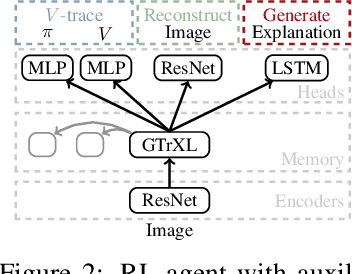
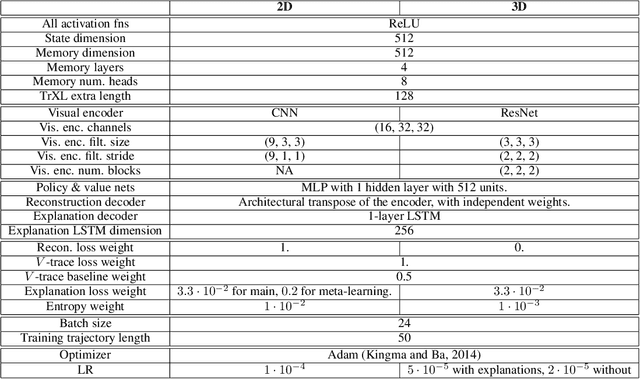
Explanations play a considerable role in human learning, especially in areas that remain major challenges for AI -- forming abstractions, and learning about the relational and causal structure of the world. Here, we explore whether reinforcement learning agents might likewise benefit from explanations. We outline a family of relational tasks that involve selecting an object that is the odd one out in a set (i.e., unique along one of many possible feature dimensions). Odd-one-out tasks require agents to reason over multi-dimensional relationships among a set of objects. We show that agents do not learn these tasks well from reward alone, but achieve >90% performance when they are also trained to generate language explaining object properties or why a choice is correct or incorrect. In further experiments, we show how predicting explanations enables agents to generalize appropriately from ambiguous, causally-confounded training, and even to meta-learn to perform experimental interventions to identify causal structure. We show that explanations help overcome the tendency of agents to fixate on simple features, and explore which aspects of explanations make them most beneficial. Our results suggest that learning from explanations is a powerful principle that could offer a promising path towards training more robust and general machine learning systems.
What shapes feature representations? Exploring datasets, architectures, and training
Jun 22, 2020
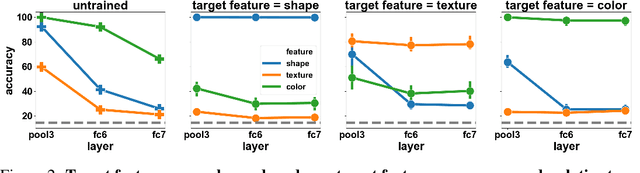
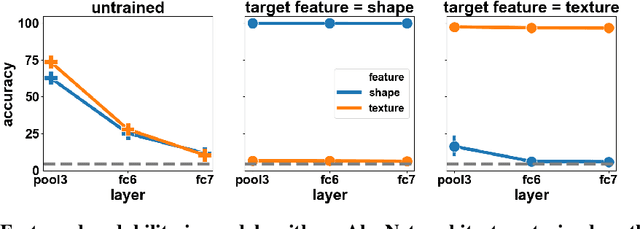
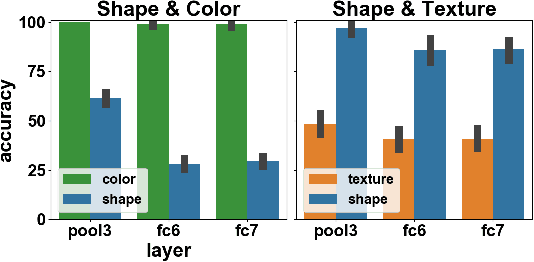
In naturalistic learning problems, a model's input contains a wide range of features, some useful for the task at hand, and others not. Of the useful features, which ones does the model use? Of the task-irrelevant features, which ones does the model represent? Answers to these questions are important for understanding the basis of models' decisions, for example to ensure they are equitable and unbiased, as well as for building new models that learn versatile, adaptable representations useful beyond their original training task. We study these questions using synthetic datasets in which the task-relevance of different input features can be controlled directly. We find that when two features redundantly predict the label, the model preferentially represents one, and its preference reflects what was most linearly decodable from the untrained model. Over training, task-relevant features are enhanced, and task-irrelevant features are partially suppressed. Interestingly, in some cases, an easier, weakly predictive feature can suppress a more strongly predictive, but harder one. Additionally, models trained to recognize both easy and hard features learn representations most similar to models that use only the easy feature. Further, easy features lead to more consistent representations across model runs than do hard features. Finally, models have more in common with an untrained model than with models trained on a different task. Our results highlight the complex processes that determine which features a model represents.
Transforming task representations to allow deep learning models to perform novel tasks
May 08, 2020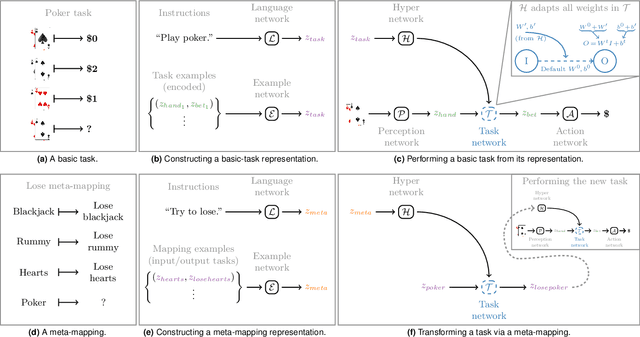
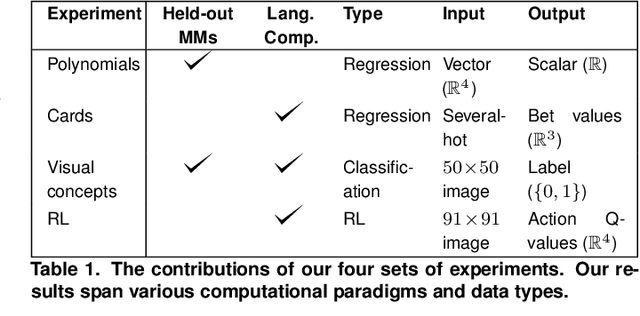
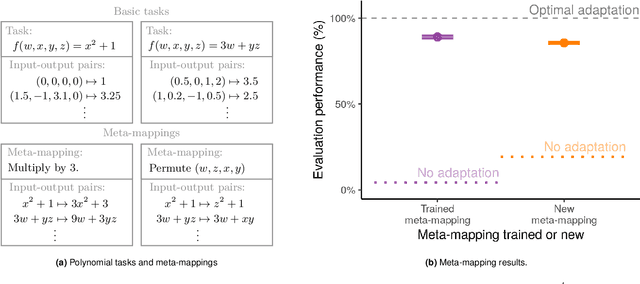
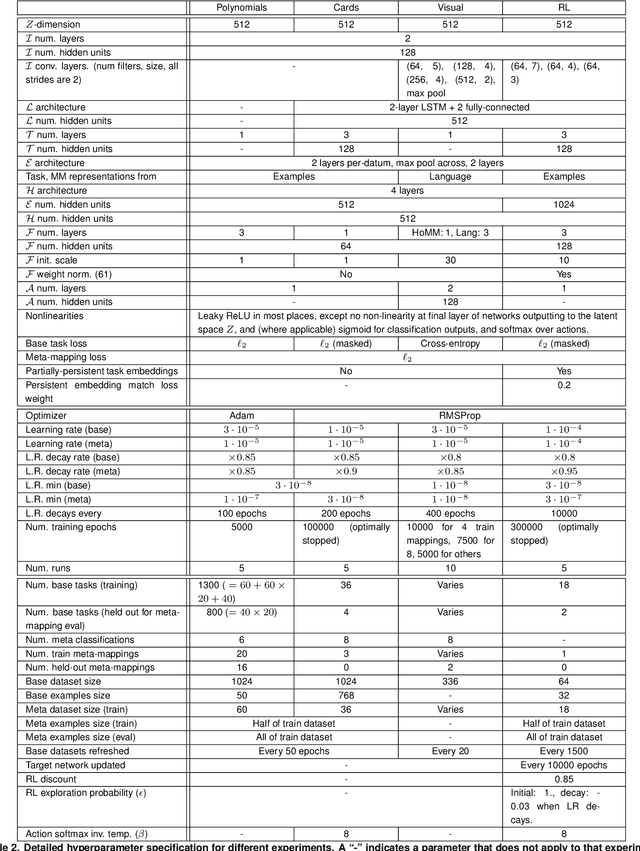
An important aspect of intelligence is the ability to adapt to a novel task without any direct experience (zero-shot), based on its relationship to previous tasks. Humans can exhibit this cognitive flexibility. By contrast, deep-learning models that achieve superhuman performance in specific tasks generally fail to adapt to even slight task alterations. To address this, we propose a general computational framework for adapting to novel tasks based on their relationship to prior tasks. We begin by learning vector representations of tasks. To adapt to new tasks, we propose meta-mappings, higher-order tasks that transform basic task representations. We demonstrate this framework across a wide variety of tasks and computational paradigms, ranging from regression to image classification and reinforcement learning. We compare to both human adaptability, and language-based approaches to zero-shot learning. Across these domains, meta-mapping is successful, often achieving 80-90% performance, without any data, on a novel task that directly contradicts its prior experience. We further show that using meta-mapping as a starting point can dramatically accelerate later learning on a new task, and reduce learning time and cumulative error substantially. Our results provide insight into a possible computational basis of intelligent adaptability, and offer a possible framework for modeling cognitive flexibility and building more flexible artificial intelligence.
Automated curricula through setter-solver interactions
Sep 27, 2019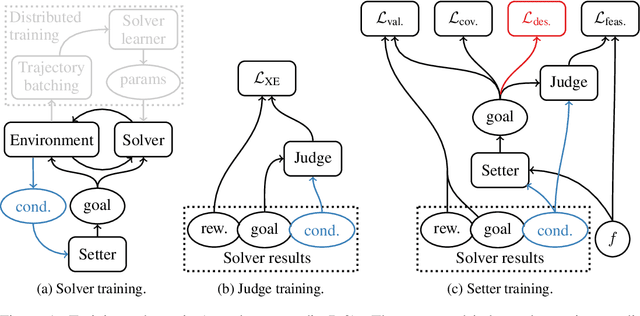

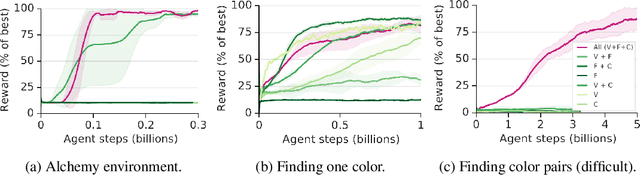
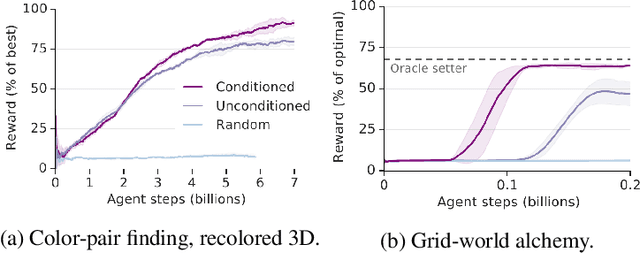
Reinforcement learning algorithms use correlations between policies and rewards to improve agent performance. But in dynamic or sparsely rewarding environments these correlations are often too small, or rewarding events are too infrequent to make learning feasible. Human education instead relies on curricula--the breakdown of tasks into simpler, static challenges with dense rewards--to build up to complex behaviors. While curricula are also useful for artificial agents, hand-crafting them is time consuming. This has lead researchers to explore automatic curriculum generation. Here we explore automatic curriculum generation in rich, dynamic environments. Using a setter-solver paradigm we show the importance of considering goal validity, goal feasibility, and goal coverage to construct useful curricula. We demonstrate the success of our approach in rich but sparsely rewarding 2D and 3D environments, where an agent is tasked to achieve a single goal selected from a set of possible goals that varies between episodes, and identify challenges for future work. Finally, we demonstrate the value of a novel technique that guides agents towards a desired goal distribution. Altogether, these results represent a substantial step towards applying automatic task curricula to learn complex, otherwise unlearnable goals, and to our knowledge are the first to demonstrate automated curriculum generation for goal-conditioned agents in environments where the possible goals vary between episodes.