 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyIn: Discovering Subgoal Structure with Keyframe-based Video Prediction
Apr 11, 2019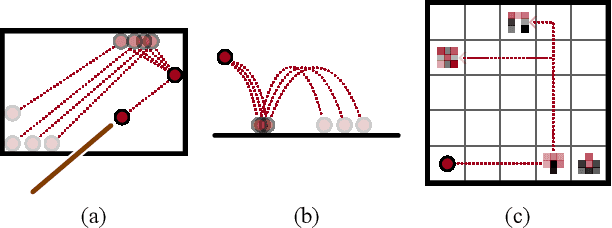
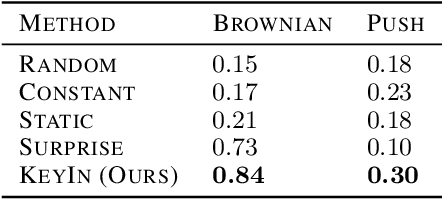
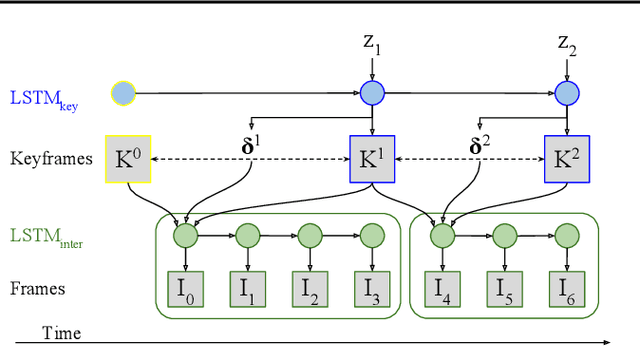
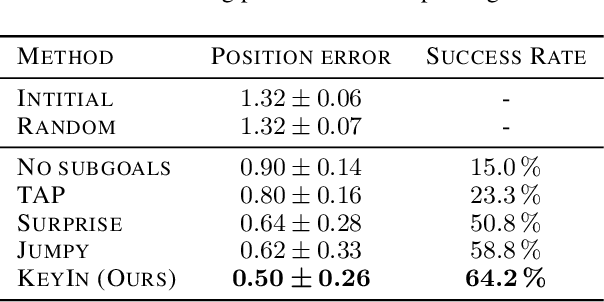
Real-world image sequences can often be naturally decomposed into a small number of frames depicting interesting, highly stochastic moments (its $\textit{keyframes}$) and the low-variance frames in between them. In image sequences depicting trajectories to a goal, keyframes can be seen as capturing the $\textit{subgoals}$ of the sequence as they depict the high-variance moments of interest that ultimately led to the goal. In this paper, we introduce a video prediction model that discovers the keyframe structure of image sequences in an unsupervised fashion. We do so using a hierarchical Keyframe-Intermediate model (KeyIn) that stochastically predicts keyframes and their offsets in time and then uses these predictions to deterministically predict the intermediate frames. We propose a differentiable formulation of this problem that allows us to train the full hierarchical model using a sequence reconstruction loss. We show that our model is able to find meaningful keyframe structure in a simulated dataset of robotic demonstrations and that these keyframes can serve as subgoals for planning. Our model outperforms other hierarchical prediction approaches for planning on a simulated pushing task.
Unsupervised Learning of Sensorimotor Affordances by Stochastic Future Prediction
Jun 25, 2018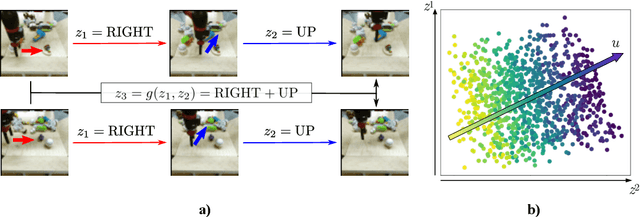
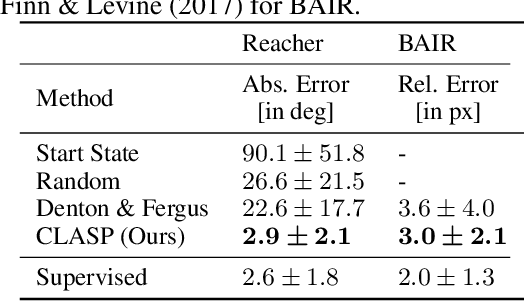
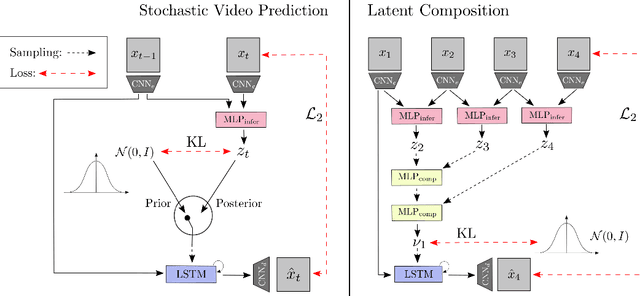
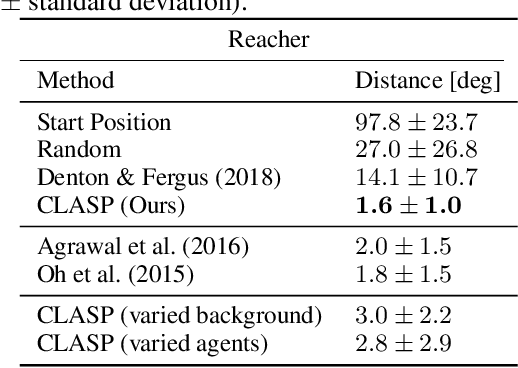
Recently, much progress has been made building systems that can capture static image properties, but natural environments are intrinsically dynamic. For an intelligent agent, perception is responsible not only for capturing features of scene content, but also capturing its \textit{affordances}: how the state of things can change, especially as the result of the agent's actions. We propose an unsupervised method to learn representations of the sensorimotor affordances of an environment. We do so by learning an embedding for stochastic future prediction that is (i) sensitive to scene dynamics and minimally sensitive to static scene content and (ii) compositional in nature, capturing the fact that changes in the environment can be composed to produce a cumulative change. We show that these two properties are sufficient to induce representations that are reusable across visually distinct scenes that share degrees of freedom. We show the applicability of our method to synthetic settings and its potential for understanding more complex, realistic visual settings.
Predicting the Future with Transformational States
Mar 26, 2018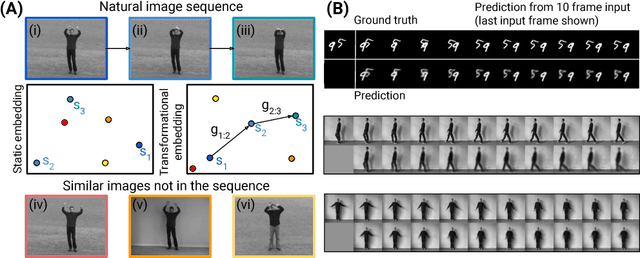
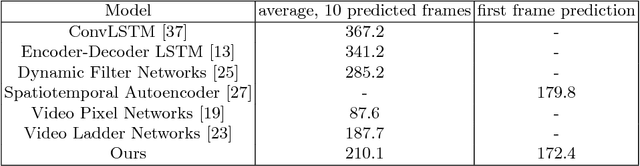

An intelligent observer looks at the world and sees not only what is, but what is moving and what can be moved. In other words, the observer sees how the present state of the world can transform in the future. We propose a model that predicts future images by learning to represent the present state and its transformation given only a sequence of images. To do so, we introduce an architecture with a latent state composed of two components designed to capture (i) the present image state and (ii) the transformation between present and future states, respectively. We couple this latent state with a recurrent neural network (RNN) core that predicts future frames by transforming past states into future states by applying the accumulated state transformation with a learned operator. We describe how this model can be integrated into an encoder-decoder convolutional neural network (CNN) architecture that uses weighted residual connections to integrate representations of the past with representations of the future. Qualitatively, our approach generates image sequences that are stable and capture realistic motion over multiple predicted frames, without requiring adversarial training. Quantitatively, our method achieves prediction results comparable to state-of-the-art results on standard image prediction benchmarks (Moving MNIST, KTH, and UCF101).
Understanding image motion with group representations
Feb 26, 2018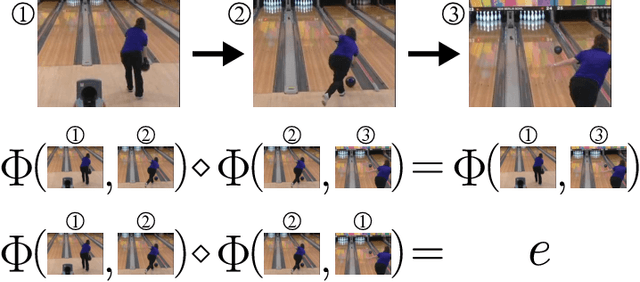
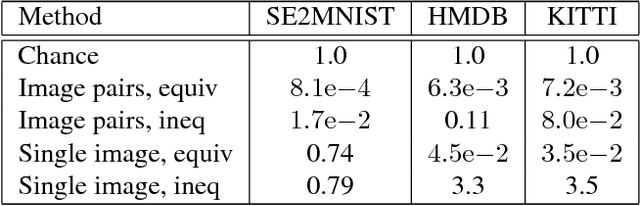

Motion is an important signal for agents in dynamic environments, but learning to represent motion from unlabeled video is a difficult and underconstrained problem. We propose a model of motion based on elementary group properties of transformations and use it to train a representation of image motion. While most methods of estimating motion are based on pixel-level constraints, we use these group properties to constrain the abstract representation of motion itself. We demonstrate that a deep neural network trained using this method captures motion in both synthetic 2D sequences and real-world sequences of vehicle motion, without requiring any labels. Networks trained to respect these constraints implicitly identify the image characteristic of motion in different sequence types. In the context of vehicle motion, this method extracts information useful for localization, tracking, and odometry. Our results demonstrate that this representation is useful for learning motion in the general setting where explicit labels are difficult to obtain.
Fast, Robust, Continuous Monocular Egomotion Computation
Feb 16, 2016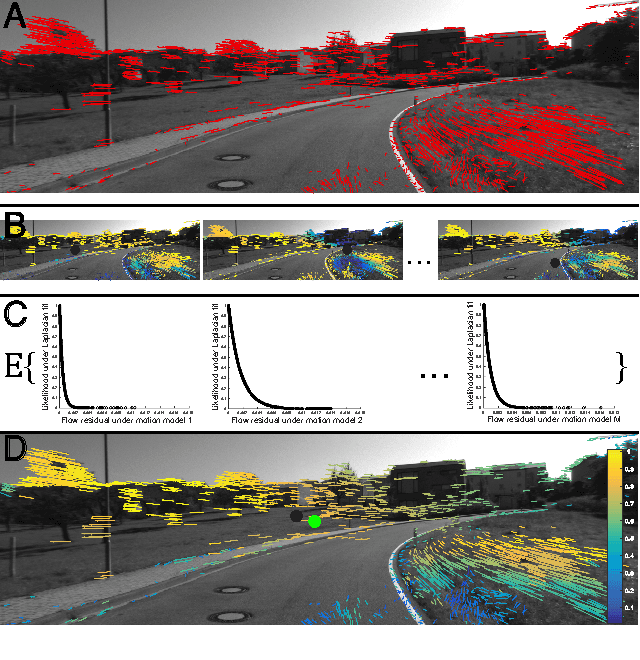
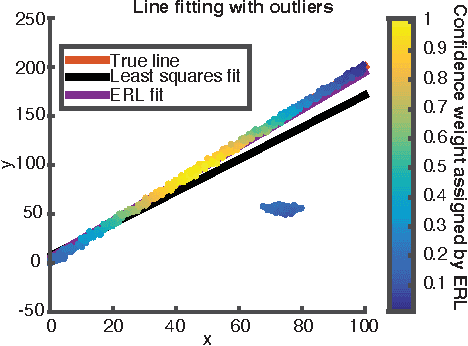
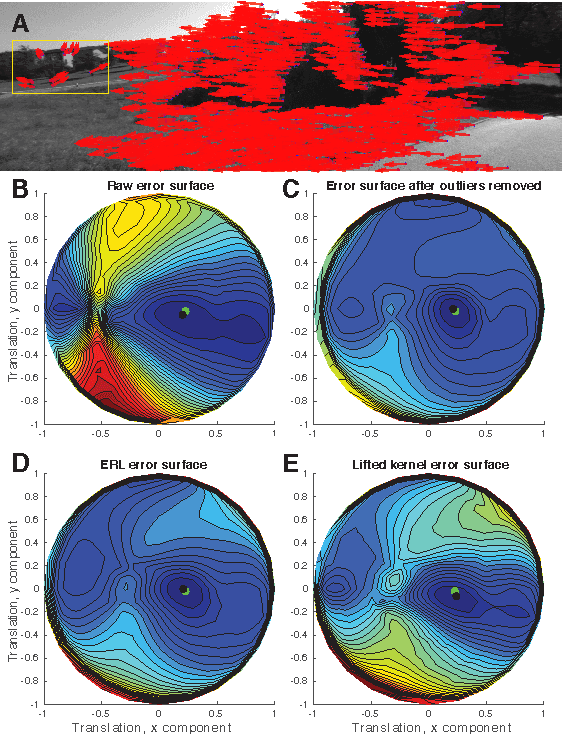
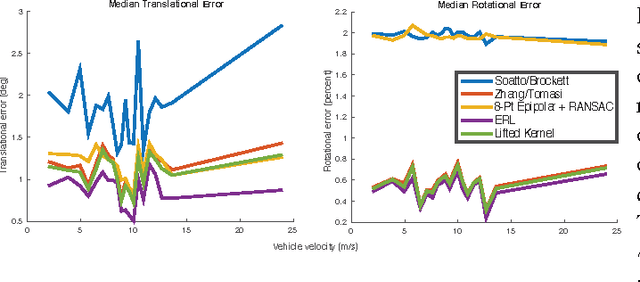
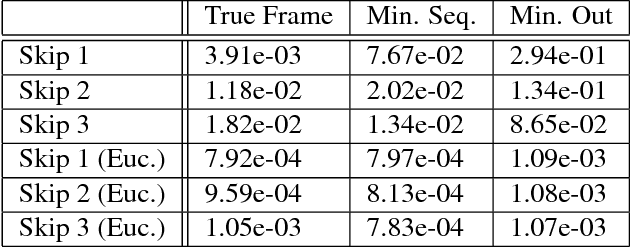
We propose robust methods for estimating camera egomotion in noisy, real-world monocular image sequences in the general case of unknown observer rotation and translation with two views and a small baseline. This is a difficult problem because of the nonconvex cost function of the perspective camera motion equation and because of non-Gaussian noise arising from noisy optical flow estimates and scene non-rigidity. To address this problem, we introduce the expected residual likelihood method (ERL), which estimates confidence weights for noisy optical flow data using likelihood distributions of the residuals of the flow field under a range of counterfactual model parameters. We show that ERL is effective at identifying outliers and recovering appropriate confidence weights in many settings. We compare ERL to a novel formulation of the perspective camera motion equation using a lifted kernel, a recently proposed optimization framework for joint parameter and confidence weight estimation with good empirical properties. We incorporate these strategies into a motion estimation pipeline that avoids falling into local minima. We find that ERL outperforms the lifted kernel method and baseline monocular egomotion estimation strategies on the challenging KITTI dataset, while adding almost no runtime cost over baseline egomotion methods.