 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalar Arithmetic Multiple Data: Customizable Precision for Deep Neural Networks
Sep 27, 2018

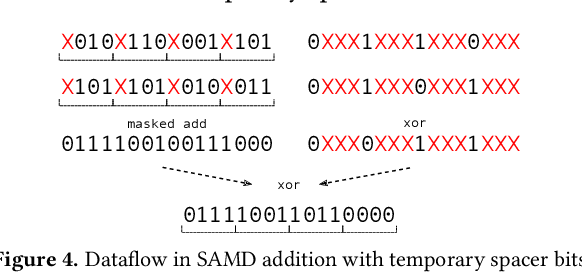

Quantization of weights and activations in Deep Neural Networks (DNNs) is a powerful technique for network compression, and has enjoyed significant attention and success. However, much of the inference-time benefit of quantization is accessible only through the use of customized hardware accelerators or by providing an FPGA implementation of quantized arithmetic. Building on prior work, we show how to construct arbitrary bit-precise signed and unsigned integer operations using a software technique which logically \emph{embeds} a vector architecture with custom bit-width lanes in universally available fixed-width scalar arithmetic. We evaluate our approach on a high-end Intel Haswell processor, and an embedded ARM processor. Our approach yields very fast implementations of bit-precise custom DNN operations, which often match or exceed the performance of operations quantized to the sizes supported in native arithmetic. At the strongest level of quantization, our approach yields a maximum speedup of $\thicksim6\times$ on the Intel platform, and $\thicksim10\times$ on the ARM platform versus quantization to native 8-bit integers.
Error Analysis and Improving the Accuracy of Winograd Convolution for Deep Neural Networks
Sep 22, 2018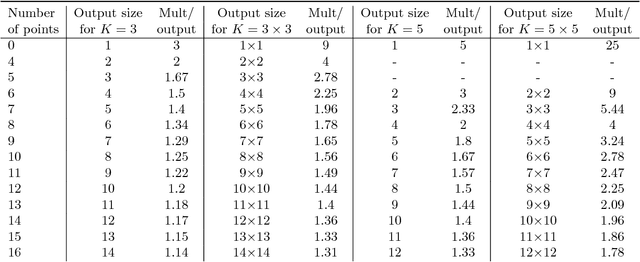
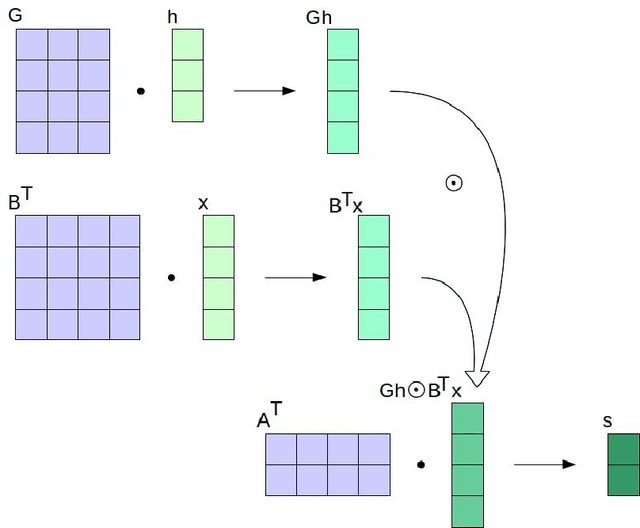
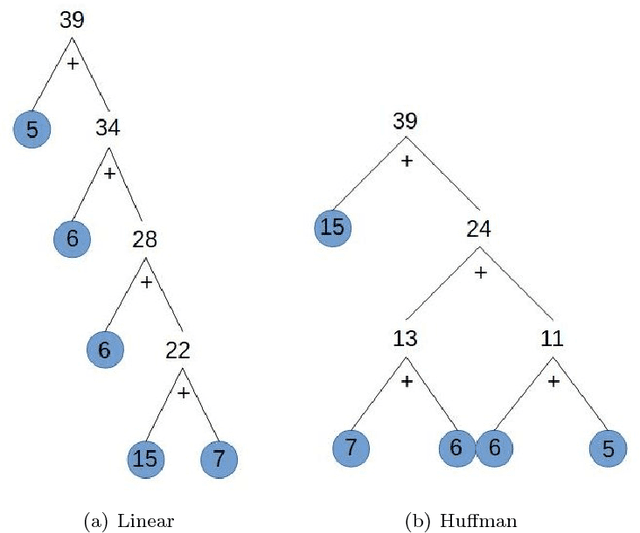
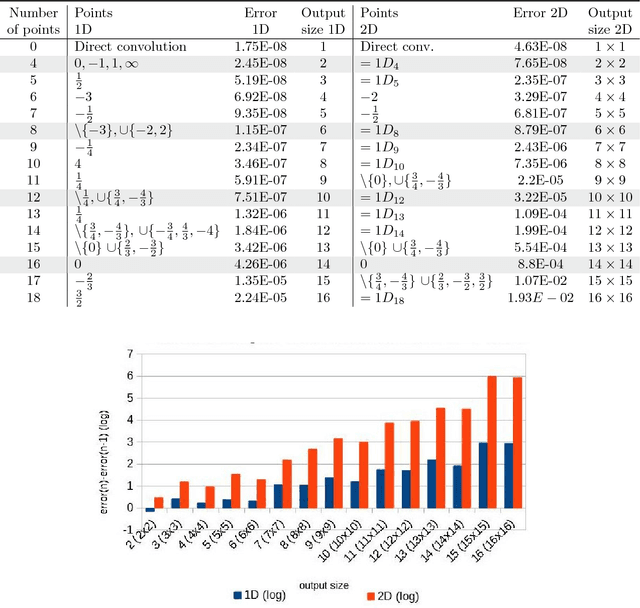
Modern deep neural networks (DNNs) spend a large amount of their execution time computing convolutions. Winograd's minimal algorithm for small convolutions can greatly reduce the number of arithmetic operations. However, a large reduction in floating point (FP) operations in these algorithms can result in poor numeric accuracy. In this paper we analyse the FP error and prove boundaries on the error. We show that the "modified" algorithm gives a significantly better accuracy of the result. We propose several methods for reducing FP error of these algorithms. Minimal convolution algorithms depend on the selection of several numeric \textit{points} that have a large impact on the accuracy of the result. We propose a canonical evaluation ordering that both reduces FP error and the size of the search space based on Huffman coding. We study point selection experimentally, and find empirically good points. We also identify the main factors that associated with sets of points that result in a low error. In addition, we explore other methods to reduce FP error, including mixed-precision convolution, and pairwise addition across DNN channels. Using our methods we can significantly reduce FP error for a given block size, which allows larger block sizes and reduced computation.
Low-memory GEMM-based convolution algorithms for deep neural networks
Sep 08, 2017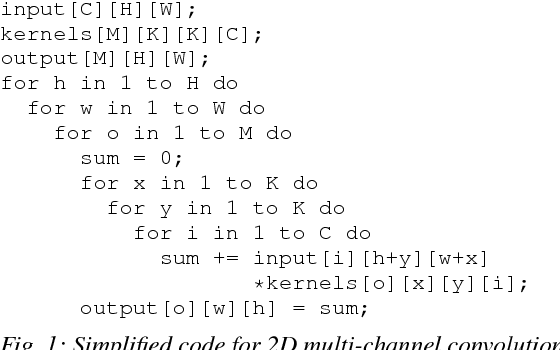
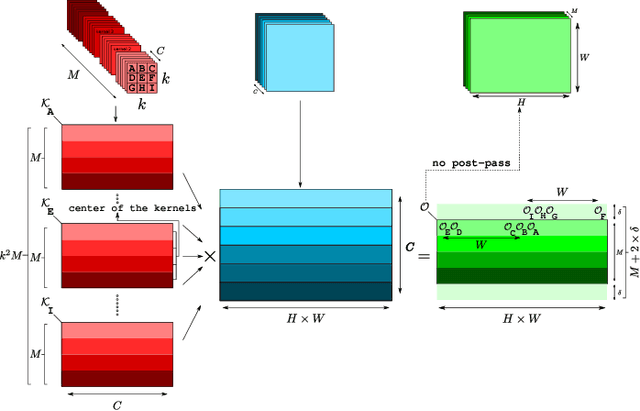
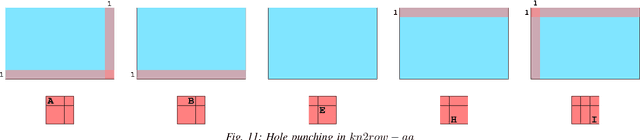
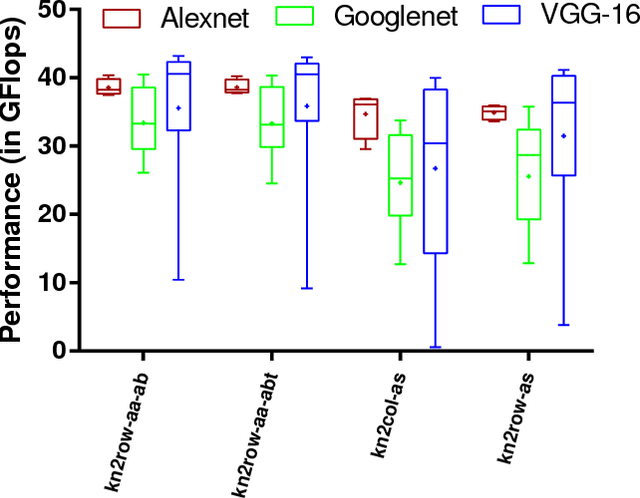
Deep neural networks (DNNs) require very large amounts of computation both for training and for inference when deployed in the field. A common approach to implementing DNNs is to recast the most computationally expensive operations as general matrix multiplication (GEMM). However, as we demonstrate in this paper, there are a great many different ways to express DNN convolution operations using GEMM. Although different approaches all perform the same number of operations, the size of temporary data structures differs significantly. Convolution of an input matrix with dimensions $C \times H \times W$, requires $O(K^2CHW)$ additional space using the classical im2col approach. More recently memory-efficient approaches requiring just $O(KCHW)$ auxiliary space have been proposed. We present two novel GEMM-based algorithms that require just $O(MHW)$ and $O(KW)$ additional space respectively, where $M$ is the number of channels in the result of the convolution. These algorithms dramatically reduce the space overhead of DNN convolution, making it much more suitable for memory-limited embedded systems. Experimental evaluation shows that our low-memory algorithms are just as fast as the best patch-building approaches despite requiring just a fraction of the amount of additional memory. Our low-memory algorithms have excellent data locality which gives them a further edge over patch-building algorithms when multiple cores are used. As a result, our low memory algorithms often outperform the best patch-building algorithms using multiple threads.
Parallel Multi Channel Convolution using General Matrix Multiplication
Jul 03, 2017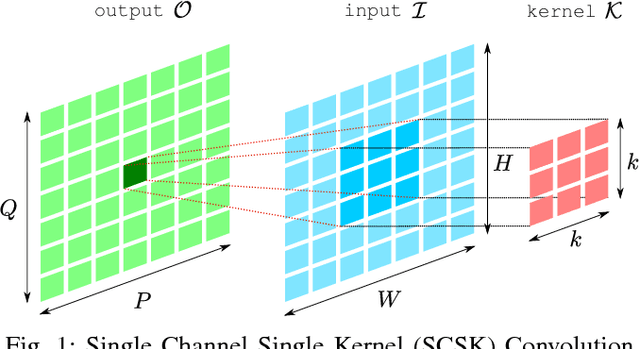
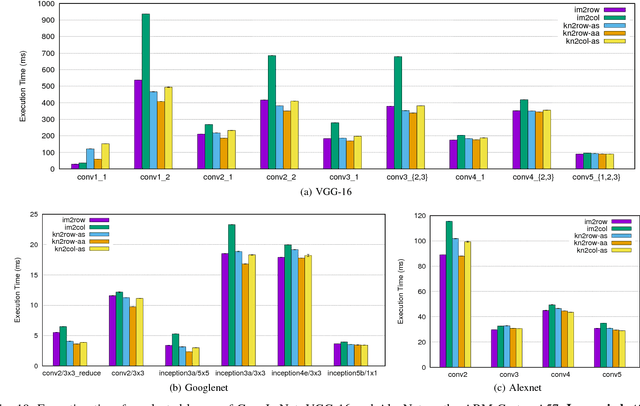
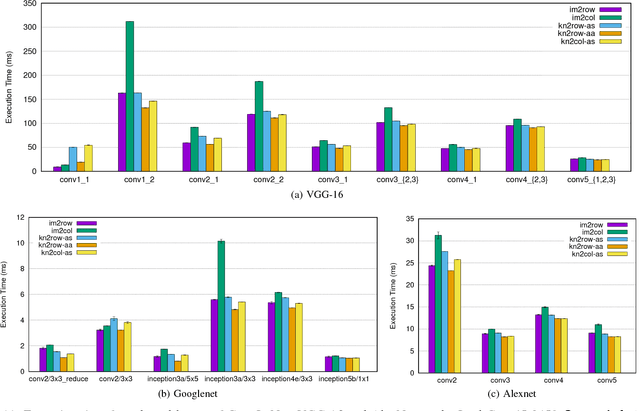
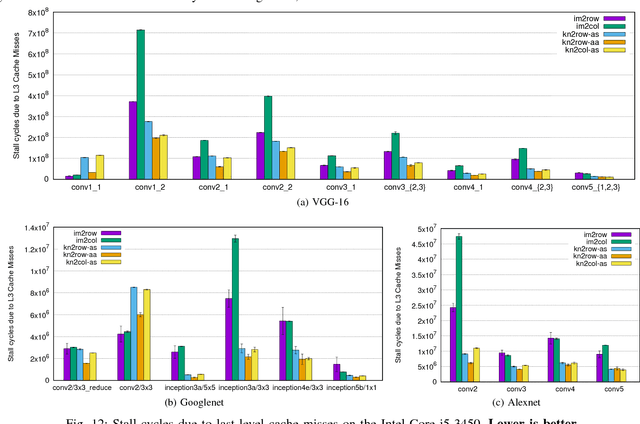
Convolutional neural networks (CNNs) have emerged as one of the most successful machine learning technologies for image and video processing. The most computationally intensive parts of CNNs are the convolutional layers, which convolve multi-channel images with multiple kernels. A common approach to implementing convolutional layers is to expand the image into a column matrix (im2col) and perform Multiple Channel Multiple Kernel (MCMK) convolution using an existing parallel General Matrix Multiplication (GEMM) library. This im2col conversion greatly increases the memory footprint of the input matrix and reduces data locality. In this paper we propose a new approach to MCMK convolution that is based on General Matrix Multiplication (GEMM), but not on im2col. Our algorithm eliminates the need for data replication on the input thereby enabling us to apply the convolution kernels on the input images directly. We have implemented several variants of our algorithm on a CPU processor and an embedded ARM processor. On the CPU, our algorithm is faster than im2col in most cases.