 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRomanian Multiword Expression Detection Using Multilingual Adversarial Training and Lateral Inhibition
Apr 22, 2023


Multiword expressions are a key ingredient for developing large-scale and linguistically sound natural language processing technology. This paper describes our improvements in automatically identifying Romanian multiword expressions on the corpus released for the PARSEME v1.2 shared task. Our approach assumes a multilingual perspective based on the recently introduced lateral inhibition layer and adversarial training to boost the performance of the employed multilingual language models. With the help of these two methods, we improve the F1-score of XLM-RoBERTa by approximately 2.7% on unseen multiword expressions, the main task of the PARSEME 1.2 edition. In addition, our results can be considered SOTA performance, as they outperform the previous results on Romanian obtained by the participants in this competition.
An Open-Domain QA System for e-Governance
Jun 16, 2022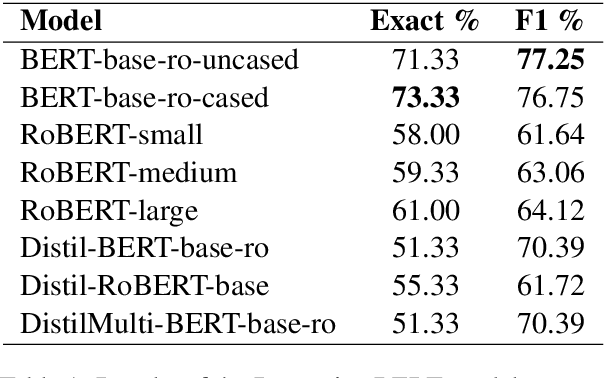
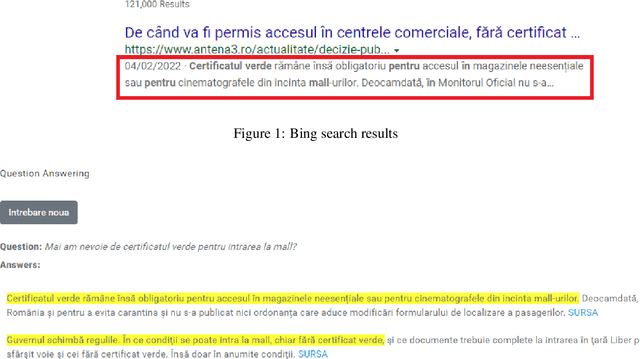
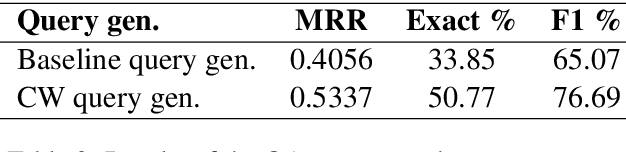
The paper presents an open-domain Question Answering system for Romanian, answering COVID-19 related questions. The QA system pipeline involves automatic question processing, automatic query generation, web searching for the top 10 most relevant documents and answer extraction using a fine-tuned BERT model for Extractive QA, trained on a COVID-19 data set that we have manually created. The paper will present the QA system and its integration with the Romanian language technologies portal RELATE, the COVID-19 data set and different evaluations of the QA performance.
Distilling the Knowledge of Romanian BERTs Using Multiple Teachers
Jan 11, 2022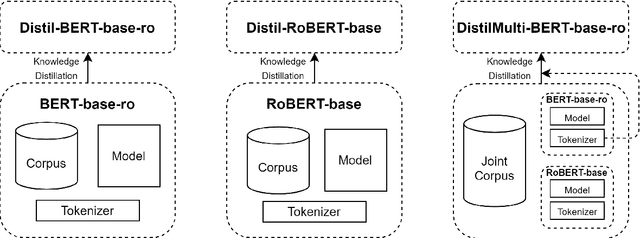
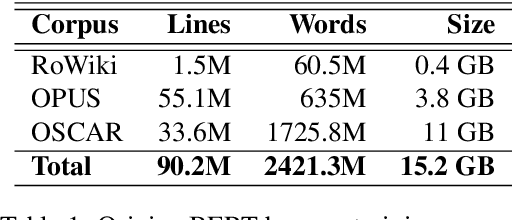

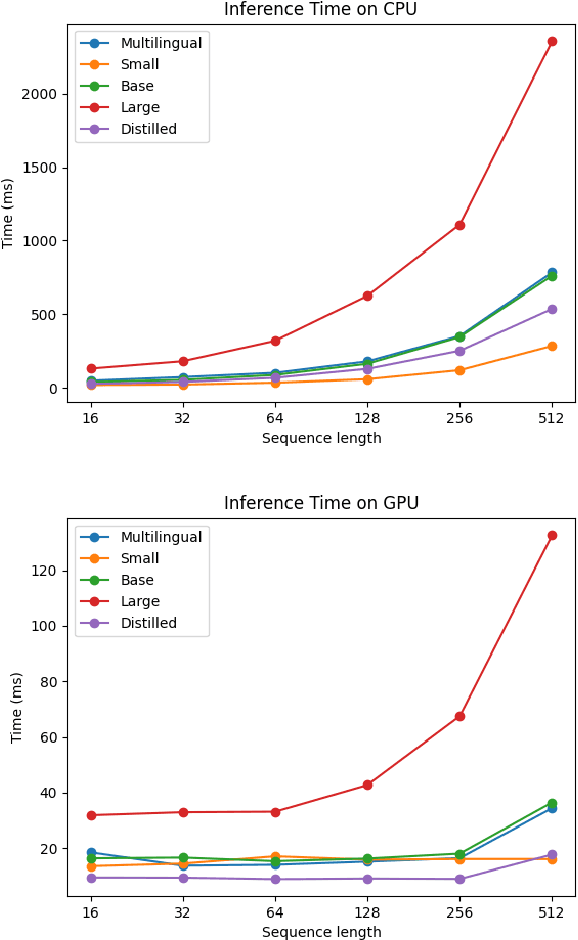
Running large-scale pre-trained language models in computationally constrained environments remains a challenging problem yet to be addressed, while transfer learning from these models has become prevalent in Natural Language Processing tasks. Several solutions, including knowledge distillation, network quantization, or network pruning have been previously proposed; however, these approaches focus mostly on the English language, thus widening the gap when considering low-resource languages. In this work, we introduce three light and fast versions of distilled BERT models for the Romanian language: Distil-BERT-base-ro, Distil-RoBERT-base, and DistilMulti-BERT-base-ro. The first two models resulted from the individual distillation of knowledge from two base versions of Romanian BERTs available in literature, while the last one was obtained by distilling their ensemble. To our knowledge, this is the first attempt to create publicly available Romanian distilled BERT models, which were thoroughly evaluated on five tasks: part-of-speech tagging, named entity recognition, sentiment analysis, semantic textual similarity, and dialect identification. Our experimental results argue that the three distilled models maintain most performance in terms of accuracy with their teachers, while being twice as fast on a GPU and ~35% smaller. In addition, we further test the similarity between the predictions of our students versus their teachers by measuring their label and probability loyalty, together with regression loyalty - a new metric introduced in this work.
Romanian Speech Recognition Experiments from the ROBIN Project
Nov 23, 2021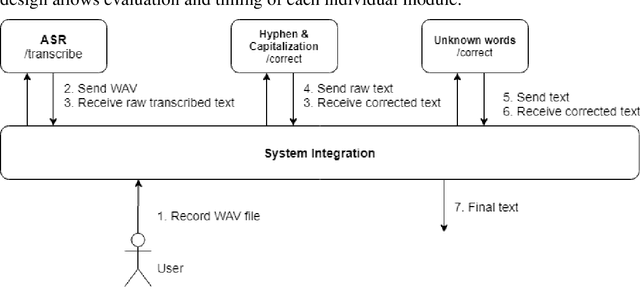
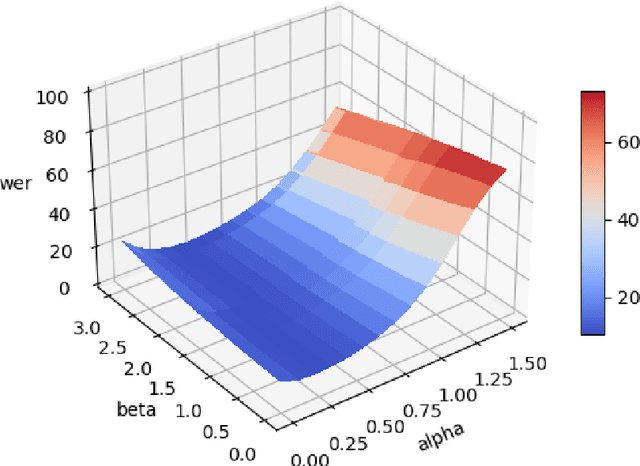
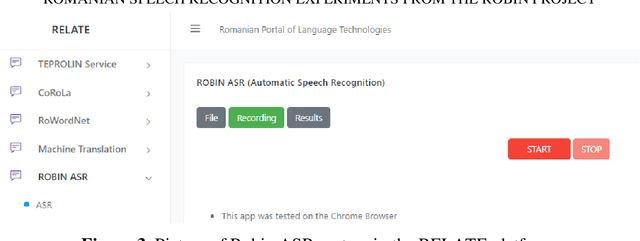
One of the fundamental functionalities for accepting a socially assistive robot is its communication capabilities with other agents in the environment. In the context of the ROBIN project, situational dialogue through voice interaction with a robot was investigated. This paper presents different speech recognition experiments with deep neural networks focusing on producing fast (under 100ms latency from the network itself), while still reliable models. Even though one of the key desired characteristics is low latency, the final deep neural network model achieves state of the art results for recognizing Romanian language, obtaining a 9.91% word error rate (WER), when combined with a language model, thus improving over the previous results while offering at the same time an improved runtime performance. Additionally, we explore two modules for correcting the ASR output (hyphen and capitalization restoration and unknown words correction), targeting the ROBIN project's goals (dialogue in closed micro-worlds). We design a modular architecture based on APIs allowing an integration engine (either in the robot or external) to chain together the available modules as needed. Finally, we test the proposed design by integrating it in the RELATE platform and making the ASR service available to web users by either uploading a file or recording new speech.
Human-Machine Interaction Speech Corpus from the ROBIN project
Nov 22, 2021
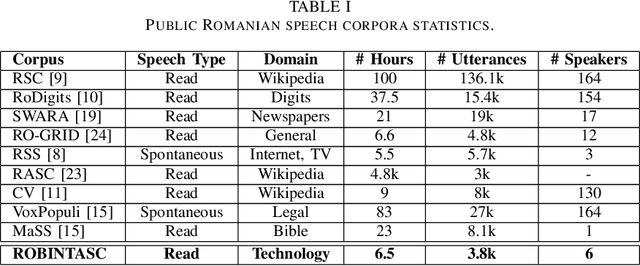
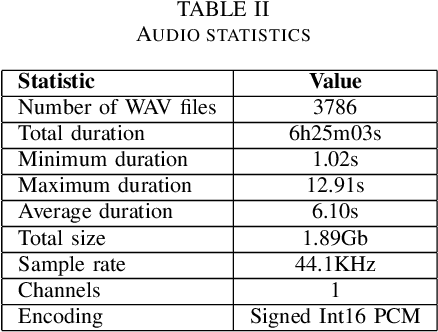
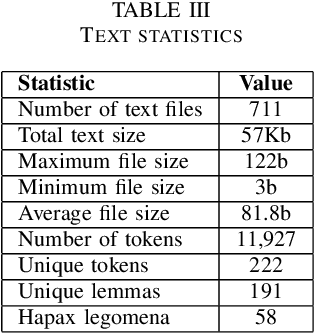
This paper introduces a new Romanian speech corpus from the ROBIN project, called ROBIN Technical Acquisition Speech Corpus (ROBINTASC). Its main purpose was to improve the behaviour of a conversational agent, allowing human-machine interaction in the context of purchasing technical equipment. The paper contains a detailed description of the acquisition process, corpus statistics as well as an evaluation of the corpus influence on a low-latency ASR system as well as a dialogue component.
* V. P\u{a}i\c{s}, R. Ion, A. -M. Avram, E. Irimia, V. B. Mititelu and M. Mitrofan, "Human-Machine Interaction Speech Corpus from the ROBIN project", Proceedings of the 2021 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), 2021, pp. 91-96
PyEuroVoc: A Tool for Multilingual Legal Document Classification with EuroVoc Descriptors
Aug 10, 2021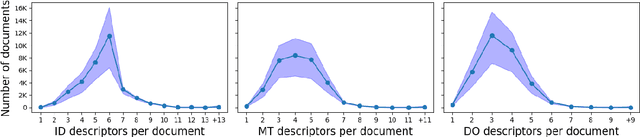
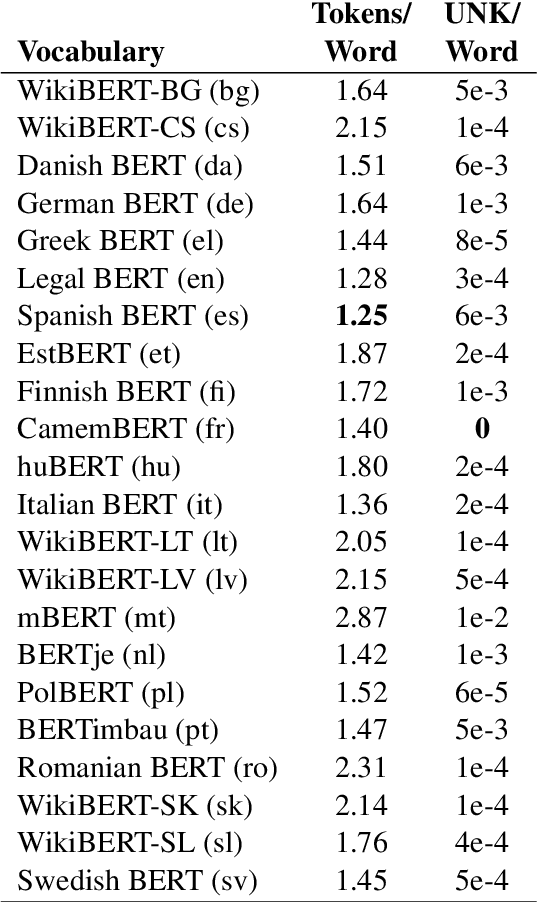
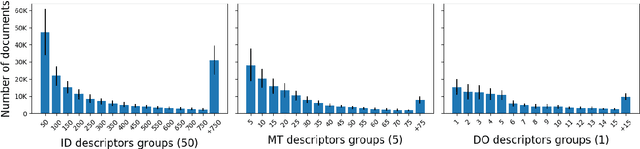
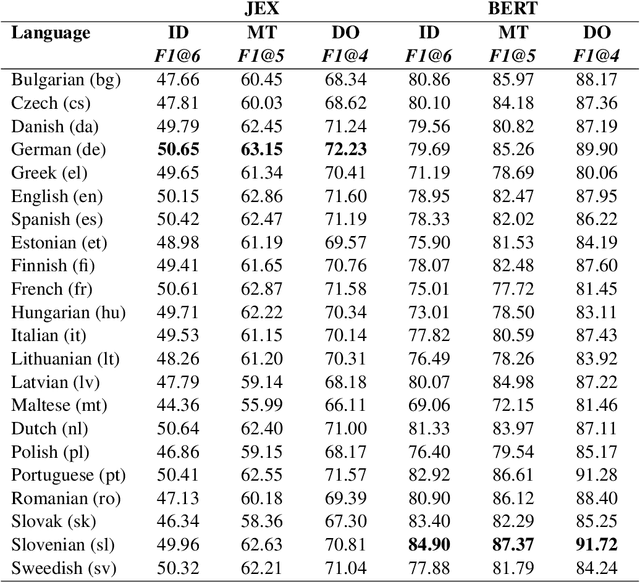
EuroVoc is a multilingual thesaurus that was built for organizing the legislative documentary of the European Union institutions. It contains thousands of categories at different levels of specificity and its descriptors are targeted by legal texts in almost thirty languages. In this work we propose a unified framework for EuroVoc classification on 22 languages by fine-tuning modern Transformer-based pretrained language models. We study extensively the performance of our trained models and show that they significantly improve the results obtained by a similar tool - JEX - on the same dataset. The code and the fine-tuned models were open sourced, together with a programmatic interface that eases the process of loading the weights of a trained model and of classifying a new document.
UPB at SemEval-2021 Task 8: Extracting Semantic Information on Measurements as Multi-Turn Question Answering
Apr 09, 2021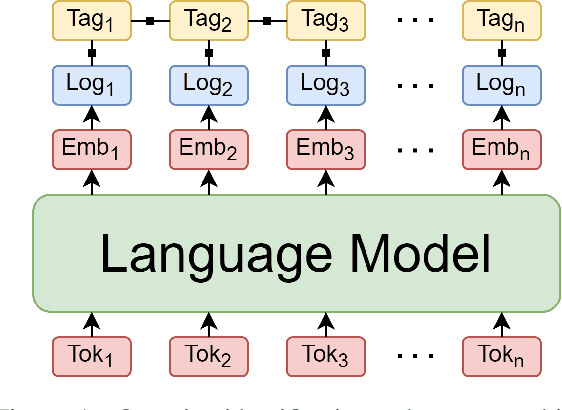

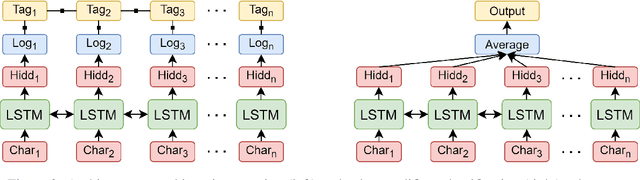

Extracting semantic information on measurements and counts is an important topic in terms of analyzing scientific discourses. The 8th task of SemEval-2021: Counts and Measurements (MeasEval) aimed to boost research in this direction by providing a new dataset on which participants train their models to extract meaningful information on measurements from scientific texts. The competition is composed of five subtasks that build on top of each other: (1) quantity span identification, (2) unit extraction from the identified quantities and their value modifier classification, (3) span identification for measured entities and measured properties, (4) qualifier span identification, and (5) relation extraction between the identified quantities, measured entities, measured properties, and qualifiers. We approached these challenges by first identifying the quantities, extracting their units of measurement, classifying them with corresponding modifiers, and afterwards using them to jointly solve the last three subtasks in a multi-turn question answering manner. Our best performing model obtained an overlapping F1-score of 36.91% on the test set.
The birth of Romanian BERT
Sep 18, 2020
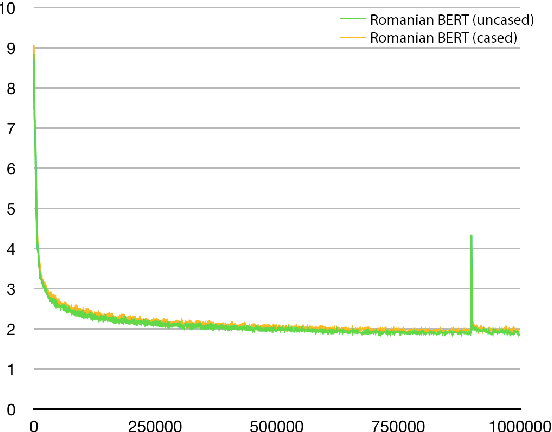

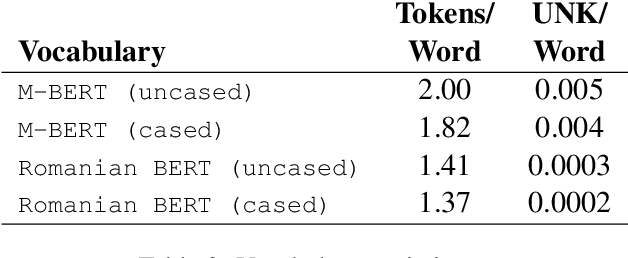
Large-scale pretrained language models have become ubiquitous in Natural Language Processing. However, most of these models are available either in high-resource languages, in particular English, or as multilingual models that compromise performance on individual languages for coverage. This paper introduces Romanian BERT, the first purely Romanian transformer-based language model, pretrained on a large text corpus. We discuss corpus composition and cleaning, the model training process, as well as an extensive evaluation of the model on various Romanian datasets. We open source not only the model itself, but also a repository that contains information on how to obtain the corpus, fine-tune and use this model in production (with practical examples), and how to fully replicate the evaluation process.
UPB at SemEval-2020 Task 6: Pretrained Language Models for Definition Extraction
Sep 16, 2020
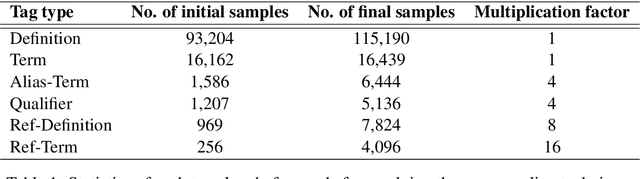
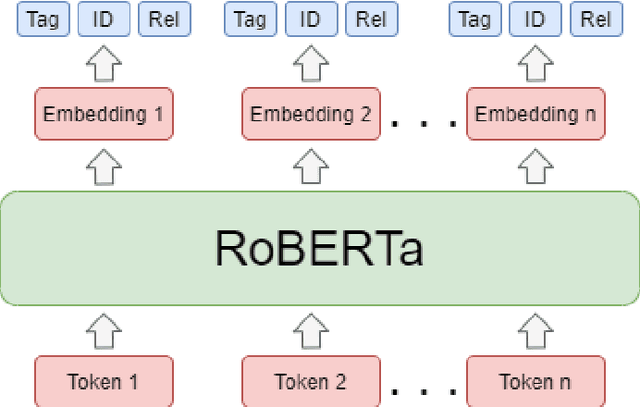
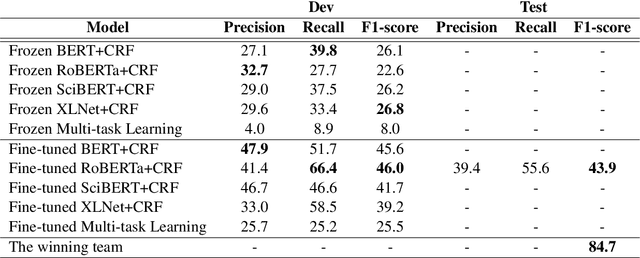
This work presents our contribution in the context of the 6th task of SemEval-2020: Extracting Definitions from Free Text in Textbooks (DeftEval). This competition consists of three subtasks with different levels of granularity: (1) classification of sentences as definitional or non-definitional,(2) labeling of definitional sentences, and (3) relation classification. We use various pretrained language models (i.e., BERT, XLNet, RoBERTa, SciBERT, and ALBERT) to solve each of the three subtasks of the competition. Specifically, for each language model variant, we experiment by both freezing its weights and fine-tuning them. We also explore a multi-task architecture that was trained to jointly predict the outputs for the second and the third subtasks. Our best performing model evaluated on the DeftEval dataset obtains the 32nd place for the first subtask and the 37th place for the second subtask. The code is available for further research at: https://github.com/avramandrei/DeftEval.
Introducing RONEC -- the Romanian Named Entity Corpus
Sep 03, 2019
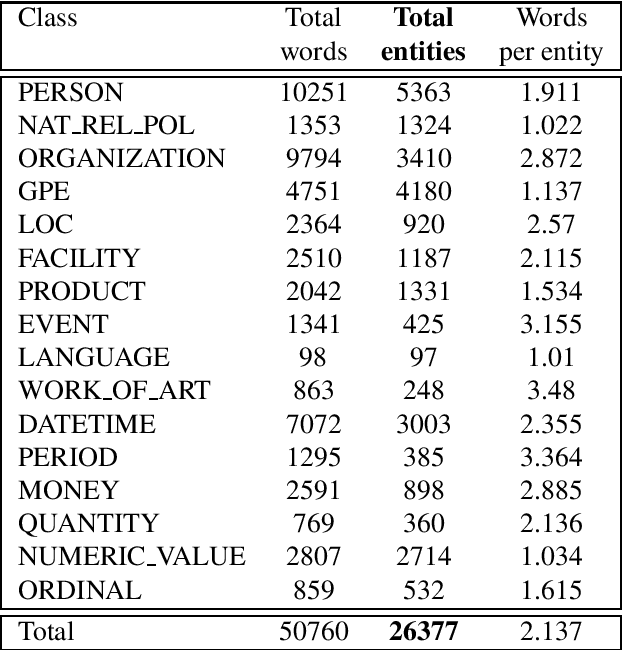
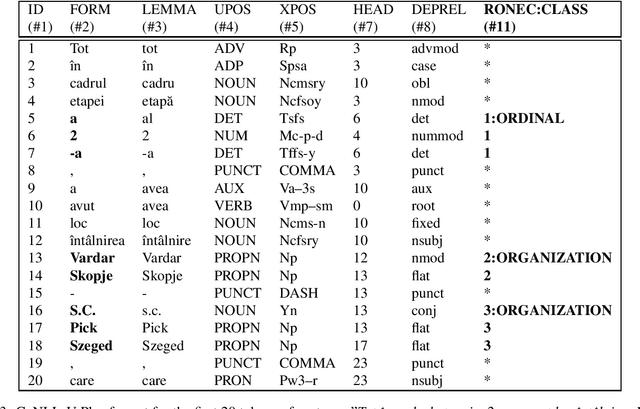
We present RONEC - the Named Entity Corpus for the Romanian language. The corpus contains over 26000 entities in ~5000 annotated sentences, belonging to 16 distinct classes. The sentences have been extracted from a copy-right free newspaper, covering several styles. This corpus represents the first initiative in the Romanian language space specifically targeted for named entity recognition. It is available in BRAT and CoNLL-U Plus formats, and it is free to use and extend at github.com/dumitrescustefan/ronec .