 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Pretraining Shapes a Generalizable Manifold: Insights into Cross-Modal Transfer to Time Series
May 19, 2026Can language-pretrained transformers become effective time-series forecasters, and why? In this paper, we show that cross-modal transfer arises because language pretraining preconditions time series training with a reusable manifold. A linear probe on frozen LLM states decodes realistic time-series trajectories without paired supervision, and retrieval in this projected space yields competitive forecasts, showing that structure and dynamics exist before finetuning. Pretrained initialization also improves optimization, producing coherent gradients and a highly anisotropic loss landscape unlike random initialization. Finetuning then acts as low-dimensional alignment, reusing existing directions rather than learning temporal primitives from scratch, as evidenced by low-rank updates, subspace alignment, and shared features for periodicity, trend, and repetition. Together, these results support a geometric account of LLM-to-time-series transfer: language pretraining builds the manifold, and finetuning projects numerical dynamics onto task-relevant directions.
Training Dynamics Underlying Language Model Scaling Laws: Loss Deceleration and Zero-Sum Learning
Jun 05, 2025This work aims to understand how scaling improves language models, specifically in terms of training dynamics. We find that language models undergo loss deceleration early in training; an abrupt slowdown in the rate of loss improvement, resulting in piecewise linear behaviour of the loss curve in log-log space. Scaling up the model mitigates this transition by (1) decreasing the loss at which deceleration occurs, and (2) improving the log-log rate of loss improvement after deceleration. We attribute loss deceleration to a type of degenerate training dynamics we term zero-sum learning (ZSL). In ZSL, per-example gradients become systematically opposed, leading to destructive interference in per-example changes in loss. As a result, improving loss on one subset of examples degrades it on another, bottlenecking overall progress. Loss deceleration and ZSL provide new insights into the training dynamics underlying language model scaling laws, and could potentially be targeted directly to improve language models independent of scale. We make our code and artefacts available at: https://github.com/mirandrom/zsl
Human-artificial intelligence teaming for scientific information extraction from data-driven additive manufacturing research using large language models
Jul 26, 2024



Data-driven research in Additive Manufacturing (AM) has gained significant success in recent years. This has led to a plethora of scientific literature to emerge. The knowledge in these works consists of AM and Artificial Intelligence (AI) contexts that have not been mined and formalized in an integrated way. It requires substantial effort and time to extract scientific information from these works. AM domain experts have contributed over two dozen review papers to summarize these works. However, information specific to AM and AI contexts still requires manual effort to extract. The recent success of foundation models such as BERT (Bidirectional Encoder Representations for Transformers) or GPT (Generative Pre-trained Transformers) on textual data has opened the possibility of expediting scientific information extraction. We propose a framework that enables collaboration between AM and AI experts to continuously extract scientific information from data-driven AM literature. A demonstration tool is implemented based on the proposed framework and a case study is conducted to extract information relevant to the datasets, modeling, sensing, and AM system categories. We show the ability of LLMs (Large Language Models) to expedite the extraction of relevant information from data-driven AM literature. In the future, the framework can be used to extract information from the broader design and manufacturing literature in the engineering discipline.
Bridging the gap between supervised classification and unsupervised topic modelling for social-media assisted crisis management
Mar 22, 2021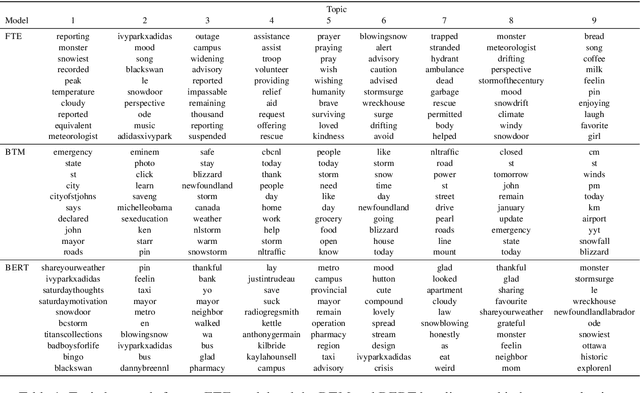
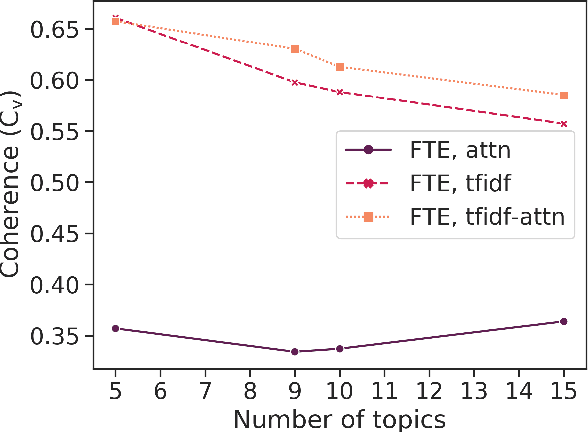
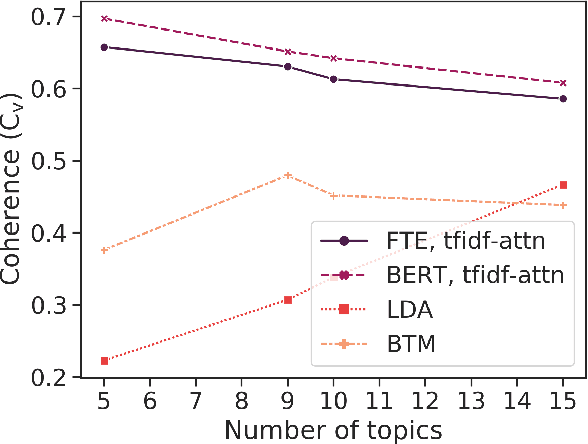
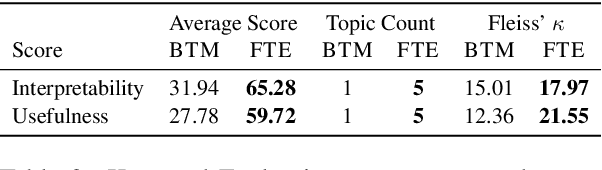
Social media such as Twitter provide valuable information to crisis managers and affected people during natural disasters. Machine learning can help structure and extract information from the large volume of messages shared during a crisis; however, the constantly evolving nature of crises makes effective domain adaptation essential. Supervised classification is limited by unchangeable class labels that may not be relevant to new events, and unsupervised topic modelling by insufficient prior knowledge. In this paper, we bridge the gap between the two and show that BERT embeddings finetuned on crisis-related tweet classification can effectively be used to adapt to a new crisis, discovering novel topics while preserving relevant classes from supervised training, and leveraging bidirectional self-attention to extract topic keywords. We create a dataset of tweets from a snowstorm to evaluate our method's transferability to new crises, and find that it outperforms traditional topic models in both automatic, and human evaluations grounded in the needs of crisis managers. More broadly, our method can be used for textual domain adaptation where the latent classes are unknown but overlap with known classes from other domains.