 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Semantic Segmentation in Adverse Weather Conditions by means of Fast Video-Sequence Segmentation
Jul 01, 2020
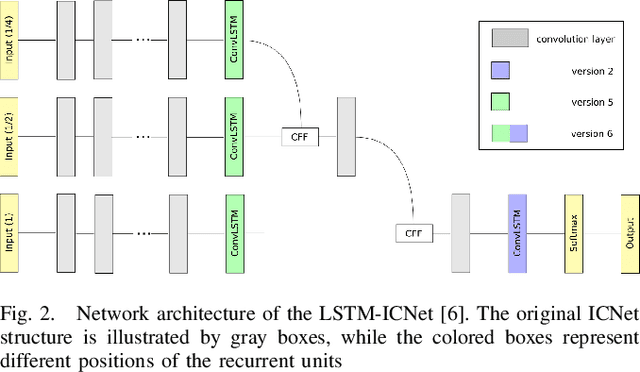
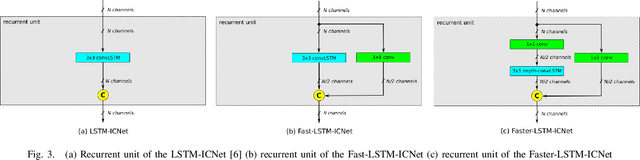
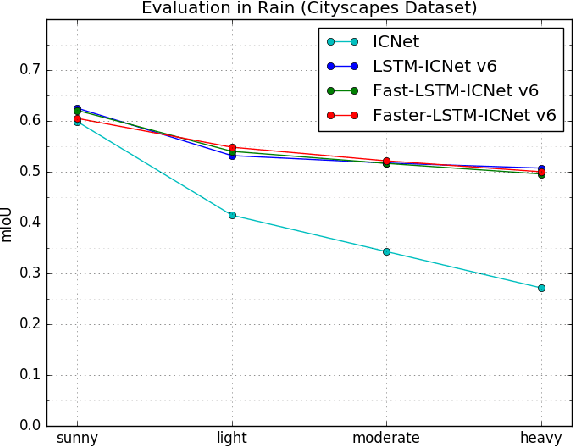
Computer vision tasks such as semantic segmentation perform very well in good weather conditions, but if the weather turns bad, they have problems to achieve this performance in these conditions. One possibility to obtain more robust and reliable results in adverse weather conditions is to use video-segmentation approaches instead of commonly used single-image segmentation methods. Video-segmentation approaches capture temporal information of the previous video-frames in addition to current image information, and hence, they are more robust against disturbances, especially if they occur in only a few frames of the video-sequence. However, video-segmentation approaches, which are often based on recurrent neural networks, cannot be applied in real-time applications anymore, since their recurrent structures in the network are computational expensive. For instance, the inference time of the LSTM-ICNet, in which recurrent units are placed at proper positions in the single-segmentation approach ICNet, increases up to 61 percent compared to the basic ICNet. Hence, in this work, the LSTM-ICNet is sped up by modifying the recurrent units of the network so that it becomes real-time capable again. Experiments on different datasets and various weather conditions show that the inference time can be decreased by about 23 percent by these modifications, while they achieve similar performance than the LSTM-ICNet and outperform the single-segmentation approach enormously in adverse weather conditions.
Separable Convolutional LSTMs for Faster Video Segmentation
Jul 16, 2019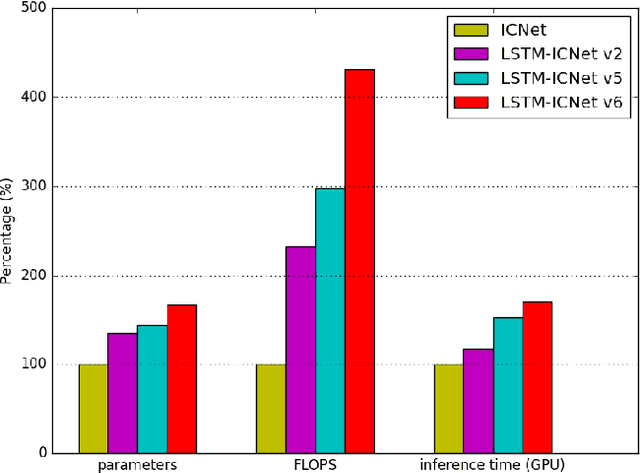

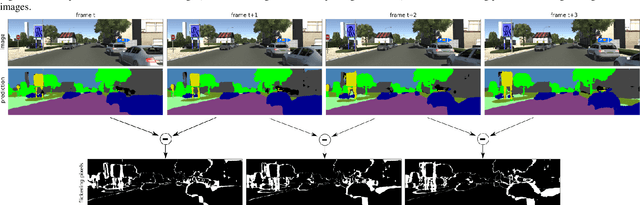
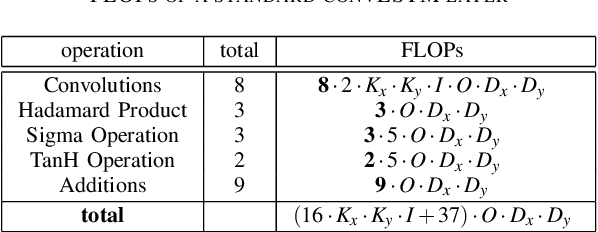
Semantic Segmentation is an important module for autonomous robots such as self-driving cars. The advantage of video segmentation approaches compared to single image segmentation is that temporal image information is considered, and their performance increases due to this. Hence, single image segmentation approaches are extended by recurrent units such as convolutional LSTM (convLSTM) cells, which are placed at suitable positions in the basic network architecture. However, a major critique of video segmentation approaches based on recurrent neural networks is their large parameter count and their computational complexity, and so, their inference time of one video frame takes up to 66 percent longer than their basic version. Inspired by the success of the spatial and depthwise separable convolutional neural networks, we generalize these techniques for convLSTMs in this work, so that the number of parameters and the required FLOPs are reduced significantly. Experiments on different datasets show that the segmentation approaches using the proposed, modified convLSTM cells achieve similar or slightly worse accuracy, but are up to 15 percent faster on a GPU than the ones using the standard convLSTM cells. Furthermore, a new evaluation metric is introduced, which measures the amount of flickering pixels in the segmented video sequence.
Robust Semantic Segmentation in Adverse Weather Conditions by means of Sensor Data Fusion
May 24, 2019
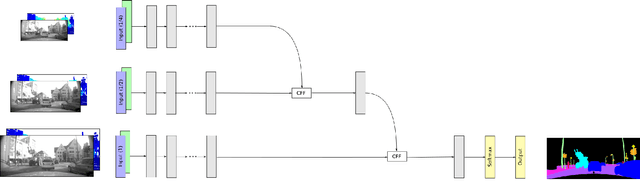
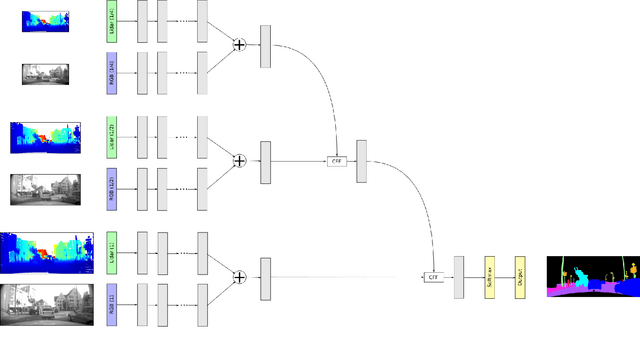

A robust and reliable semantic segmentation in adverse weather conditions is very important for autonomous cars, but most state-of-the-art approaches only achieve high accuracy rates in optimal weather conditions. The reason is that they are only optimized for good weather conditions and given noise models. However, most of them fail, if data with unknown disturbances occur, and their performance decrease enormously. One possibility to still obtain reliable results is to observe the environment with different sensor types, such as camera and lidar, and to fuse the sensor data by means of neural networks, since different sensors behave differently in diverse weather conditions. Hence, the sensors can complement each other by means of an appropriate sensor data fusion. Nevertheless, the fusion-based approaches are still susceptible to disturbances and fail to classify disturbed image areas correctly. This problem can be solved by means of a special training method, the so called Robust Learning Method (RLM), a method by which the neural network learns to handle unknown noise. In this work, two different sensor fusion architectures for semantic segmentation are compared and evaluated on several datasets. Furthermore, it is shown that the RLM increases the robustness in adverse weather conditions enormously, and achieve good results although no disturbance model has been learned by the neural network.
Semantic Segmentation of Video Sequences with Convolutional LSTMs
May 03, 2019

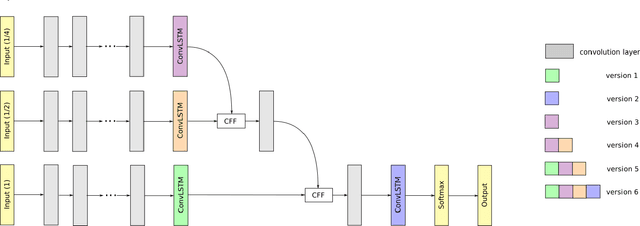
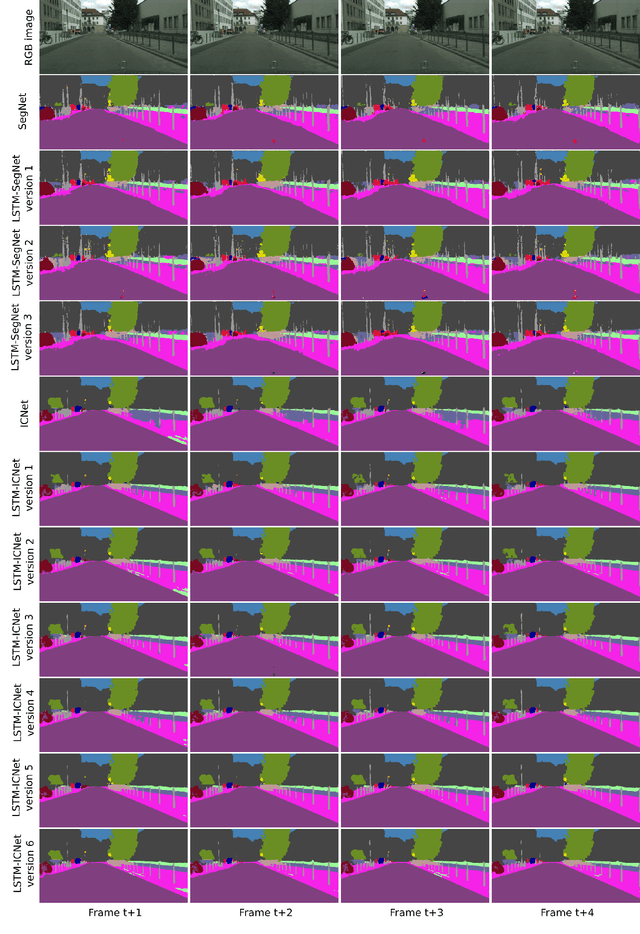
Most of the semantic segmentation approaches have been developed for single image segmentation, and hence, video sequences are currently segmented by processing each frame of the video sequence separately. The disadvantage of this is that temporal image information is not considered, which improves the performance of the segmentation approach. One possibility to include temporal information is to use recurrent neural networks. However, there are only a few approaches using recurrent networks for video segmentation so far. These approaches extend the encoder-decoder network architecture of well-known segmentation approaches and place convolutional LSTM layers between encoder and decoder. However, in this paper it is shown that this position is not optimal, and that other positions in the network exhibit better performance. Nowadays, state-of-the-art segmentation approaches rarely use the classical encoder-decoder structure, but use multi-branch architectures. These architectures are more complex, and hence, it is more difficult to place the recurrent units at a proper position. In this work, the multi-branch architectures are extended by convolutional LSTM layers at different positions and evaluated on two different datasets in order to find the best one. It turned out that the proposed approach outperforms the pure CNN-based approach for up to 1.6 percent.
* This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
Optimal Sensor Data Fusion Architecture for Object Detection in Adverse Weather Conditions
Jul 06, 2018


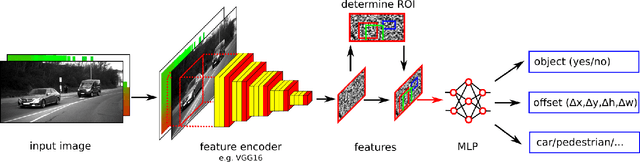
A good and robust sensor data fusion in diverse weather conditions is a quite challenging task. There are several fusion architectures in the literature, e.g. the sensor data can be fused right at the beginning (Early Fusion), or they can be first processed separately and then concatenated later (Late Fusion). In this work, different fusion architectures are compared and evaluated by means of object detection tasks, in which the goal is to recognize and localize predefined objects in a stream of data. Usually, state-of-the-art object detectors based on neural networks are highly optimized for good weather conditions, since the well-known benchmarks only consist of sensor data recorded in optimal weather conditions. Therefore, the performance of these approaches decreases enormously or even fails in adverse weather conditions. In this work, different sensor fusion architectures are compared for good and adverse weather conditions for finding the optimal fusion architecture for diverse weather situations. A new training strategy is also introduced such that the performance of the object detector is greatly enhanced in adverse weather scenarios or if a sensor fails. Furthermore, the paper responds to the question if the detection accuracy can be increased further by providing the neural network with a-priori knowledge such as the spatial calibration of the sensors.
* This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible