 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Video Sequences with Convolutional LSTMs
Paper and Code


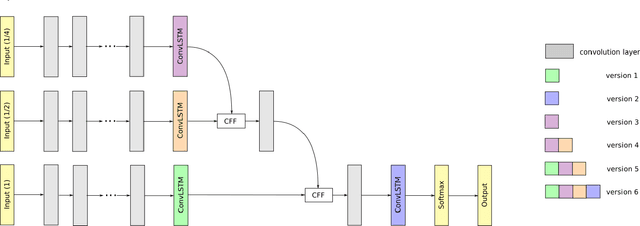
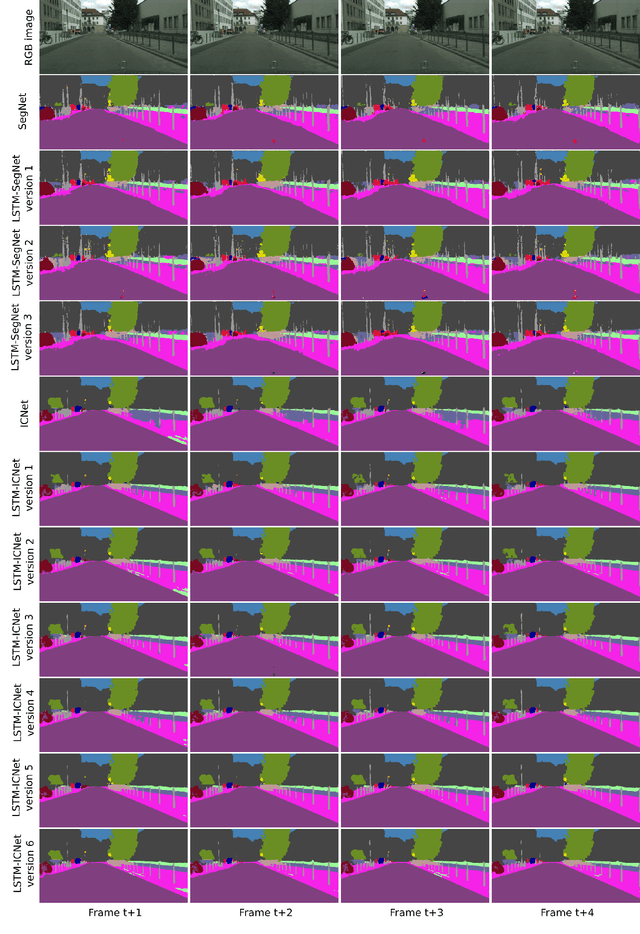
Most of the semantic segmentation approaches have been developed for single image segmentation, and hence, video sequences are currently segmented by processing each frame of the video sequence separately. The disadvantage of this is that temporal image information is not considered, which improves the performance of the segmentation approach. One possibility to include temporal information is to use recurrent neural networks. However, there are only a few approaches using recurrent networks for video segmentation so far. These approaches extend the encoder-decoder network architecture of well-known segmentation approaches and place convolutional LSTM layers between encoder and decoder. However, in this paper it is shown that this position is not optimal, and that other positions in the network exhibit better performance. Nowadays, state-of-the-art segmentation approaches rarely use the classical encoder-decoder structure, but use multi-branch architectures. These architectures are more complex, and hence, it is more difficult to place the recurrent units at a proper position. In this work, the multi-branch architectures are extended by convolutional LSTM layers at different positions and evaluated on two different datasets in order to find the best one. It turned out that the proposed approach outperforms the pure CNN-based approach for up to 1.6 percent.