 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparable Convolutional LSTMs for Faster Video Segmentation
Paper and Code
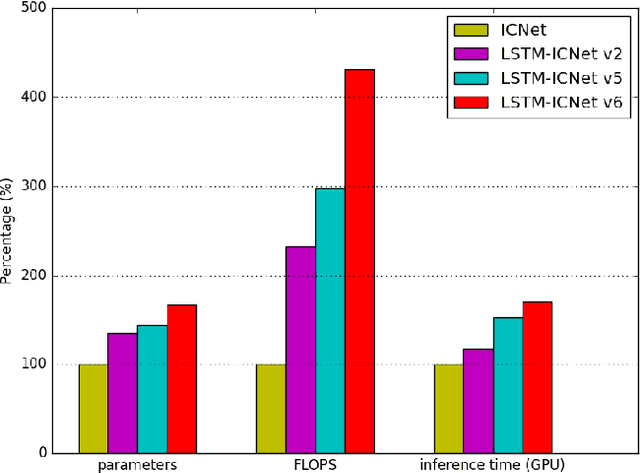

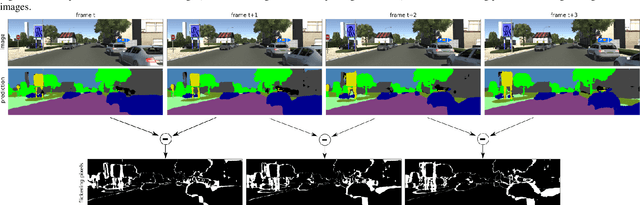
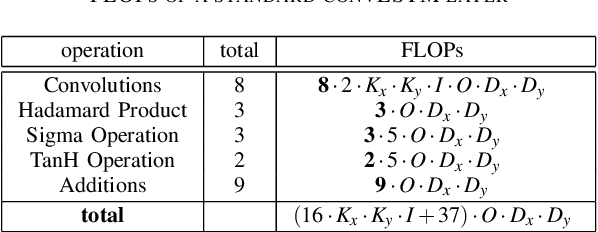
Semantic Segmentation is an important module for autonomous robots such as self-driving cars. The advantage of video segmentation approaches compared to single image segmentation is that temporal image information is considered, and their performance increases due to this. Hence, single image segmentation approaches are extended by recurrent units such as convolutional LSTM (convLSTM) cells, which are placed at suitable positions in the basic network architecture. However, a major critique of video segmentation approaches based on recurrent neural networks is their large parameter count and their computational complexity, and so, their inference time of one video frame takes up to 66 percent longer than their basic version. Inspired by the success of the spatial and depthwise separable convolutional neural networks, we generalize these techniques for convLSTMs in this work, so that the number of parameters and the required FLOPs are reduced significantly. Experiments on different datasets show that the segmentation approaches using the proposed, modified convLSTM cells achieve similar or slightly worse accuracy, but are up to 15 percent faster on a GPU than the ones using the standard convLSTM cells. Furthermore, a new evaluation metric is introduced, which measures the amount of flickering pixels in the segmented video sequence.